テキスト分析と単語ベクトル
このセクションでは、数式におけるテキスト分析、テキスト解析、および TF-IDF 単語ベクトル関数について概要を説明します。
テキスト分析
analyze 関数は、Solr アナライザーをテキストフィールドに適用し、アナライザーによって出力されたトークンを配列で返します。 Solr のスキーマでフィールドに添付されているアナライザーチェーンは、analyze 関数で使用できます。
以下の例では、テキスト "hello world" は、スキーマの subject フィールドに添付されたアナライザーチェーンを使用して分析されます。 subject フィールドはフィールドタイプ text_general として定義されており、テキストは text_general フィールドタイプに設定された分析チェーンを使用して分析されます。
analyze("hello world", subject)この式が /stream ハンドラに送信されると、次の応答が返されます。
{
"result-set": {
"docs": [
{
"return-value": [
"hello",
"world"
]
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}ドキュメントへのアノテーション
analyze 関数は、select 関数内で使用して、分析によって生成されたトークンでドキュメントにアノテーションを付けることができます。
以下の例では、"collection1" で search を実行します。 search 関数によって返される各タプルには、id と subject が含まれています。 各タプルについて、select 関数は id フィールドを選択し、subject フィールドで analyze 関数を呼び出します。 subject_bigram フィールドで指定されたアナライザーチェーンは、バイグラム分析を実行するように設定されています。 analyze 関数によって生成されたトークンは、terms というフィールドの各タプルに追加されます。
select(search(collection1, q="*:*", fl="id, subject", sort="id asc"),
id,
analyze(subject, subject_bigram) as terms)出力では、バイグラム単語の配列がタプルに追加されていることに注意してください。
{
"result-set": {
"docs": [
{
"terms": [
"text analysis",
"analysis example"
],
"id": "1"
},
{
"terms": [
"example number",
"number two"
],
"id": "2"
},
{
"EOF": true,
"RESPONSE_TIME": 4
}
]
}
}テキスト解析
cartesianProduct 関数は、analyze 関数と組み合わせて使用することで、幅広いテキスト解析を実行できます。
cartesianProduct 関数は、複数値フィールドをタプルのストリームに展開します。 analyze 関数を使用して複数値フィールドを作成する場合、cartesianProduct 関数は、分析されたトークンをタプルのストリームに展開します。 これにより、分析されたトークンのストリームに対して分析を実行し、Zeppelin-Solr で結果を視覚化できます。
例: フレーズ集計
フレーズ集計を実行する例を使用して、cartesianProduct と analyze を組み合わせる効果を示します。
この例では、映画レビューのコレクションに対して search 式が実行されます。 フレーズクエリ "Man on Fire" が検索され、スコア順に上位 5000 件の結果が返されます。 結果から返される単一のフィールドは、映画レビューのテキストを含む review_t フィールドです。
次に、検索結果に対して cartesianProduct 関数が実行されます。 cartesianProduct 関数は analyze 関数を適用します。これは、review_t フィールドを取得し、text_bigrams スキーマフィールドに添付されたアナライザーで分析します。 このアナライザーは、テキストフィールドで見つかったバイグラムを出力します。 cartesianProduct 関数は、各バイグラムを term フィールドに格納されたバイグラムを持つ独自のタプルに展開します。
それぞれバイグラムを含むタプルのストリームは、正規表現を使用して having 関数によってフィルタリングされ、長さが 12 以上のバイグラムを選択し、特定の文字を含むバイグラムを除外します。
次に、hashRollup 関数はバイグラムを集計し、top 関数はカウント別に上位 10 個のバイグラムを出力します.
次に、Zeppelin-Solr を使用して上位 10 個のバイグラムを視覚化します。
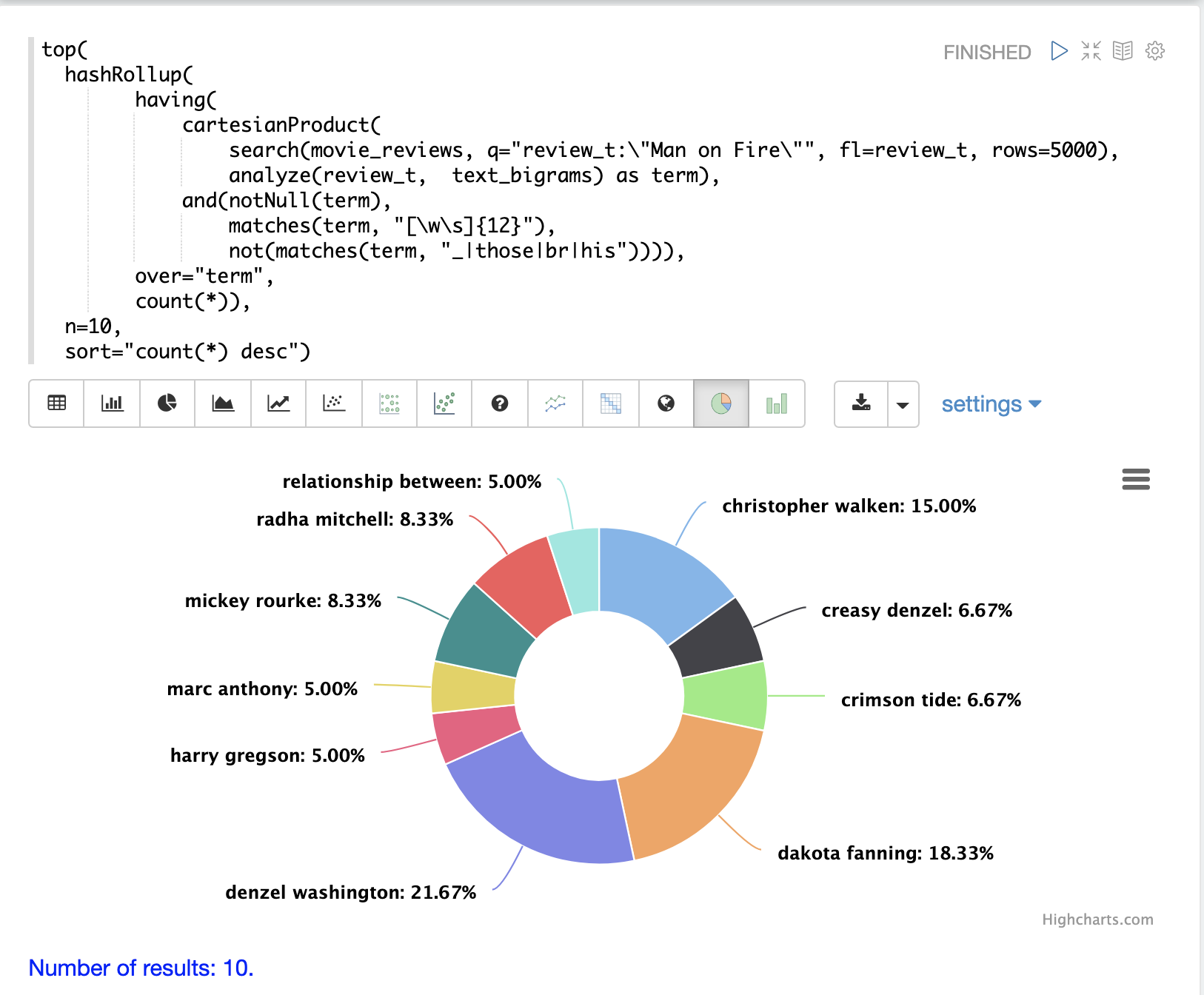
アナライザーは、正規表現または辞書で抽出されたトークンだけでなく、NLP エンティティ (人、場所、会社など) に対する集計をサポートするために、さまざまな方法で構成できます。
TF-IDF 単語ベクトル
termVectors 関数を使用して、analyze 関数によって生成された単語から TF-IDF 単語ベクトルを構築できます。
termVectors 関数は、id というフィールドと terms というフィールドを含むタプルのリストに対して動作します。これは、上記の文書アノテーションの例の出力構造と全く同じであることに注意してください。
termVectors 関数は、タプルのリストから行列を作成します。行列には、リスト内の各タプルに対応する行があります。行列には、terms フィールドの各用語に対応する列があります。
let(echo="c, d", (1)
a=select(search(collection3, q="*:*", fl="id, subject", sort="id asc"), (2)
id,
analyze(subject, subject_bigram) as terms),
b=termVectors(a, minTermLength=4, minDocFreq=0, maxDocFreq=1), (3)
c=getRowLabels(b), (4)
d=getColumnLabels(b))以下の例は、上記の文書アノテーションの例に基づいています。
| 1 | echo パラメータは変数 c と d をエコーするため、出力には行ラベルと列ラベルが含まれます。これらは式の中で後で定義されます。 |
| 2 | タプルのリストは変数 a に格納されます。termVectors 関数は変数 a に対して動作し、2 行 4 列の行列を作成します。 |
| 3 | termVectors 関数は、用語ベクトル行列の行ラベルと列ラベルを変数 b として設定します。行ラベルは文書 ID で、列ラベルは用語です。 |
| 4 | getRowLabels 関数と getColumnLabels 関数は、行ラベルと列ラベルを返します。これらは変数 c と d に格納されます。 |
この式が /stream ハンドラに送信されると、次の応答が返されます。
{
"result-set": {
"docs": [
{
"c": [
"1",
"2"
],
"d": [
"analysis example",
"example number",
"number two",
"text analysis"
]
},
{
"EOF": true,
"RESPONSE_TIME": 5
}
]
}
}TF-IDF 値
用語ベクトル行列内の値は、各文書の各用語の TF-IDF 値です。以下の例は、行列の値を示しています。
let(a=select(search(collection3, q="*:*", fl="id, subject", sort="id asc"),
id,
analyze(subject, subject_bigram) as terms),
b=termVectors(a, minTermLength=4, minDocFreq=0, maxDocFreq=1))この式が /stream ハンドラに送信されると、次の応答が返されます。
{
"result-set": {
"docs": [
{
"b": [
[
1.4054651081081644,
0,
0,
1.4054651081081644
],
[
0,
1.4054651081081644,
1.4054651081081644,
0
]
]
},
{
"EOF": true,
"RESPONSE_TIME": 5
}
]
}
}ノイズの制限
用語ベクトルを扱う際の重要な課題の1つは、テキストにはしばしば大量のノイズが含まれており、データの重要な用語を覆い隠してしまう可能性があることです。termVectors 関数には、重要性の低い用語を除外するために設計されたパラメータがいくつかあります。ノイズとなる用語を除外することで、用語ベクトル行列をメモリに収まる程度に小さく保つことができるため、これも重要です。
用語ベクトル行列からノイズとなる用語を除外するために設計された4つのパラメータがあります。
minTermLength-
オプション
デフォルト:
3行列に用語を含めるために必要な最小用語長。
minDocFreq-
オプション
デフォルト:
.05インデックスに含めるために、用語が出現する必要がある文書の最小割合(
0から1までの数値で表す)。 maxDocFreq-
オプション
デフォルト:
.5インデックスに含めるために、用語が出現できる文書の最大割合(
0から1までの数値で表す)。 exclude-
オプション
デフォルト:なし
用語を除外するために使用される、カンマ区切りの文字列リスト。用語に除外文字列のいずれかが含まれている場合、その用語は用語ベクトルから除外されます。