SQLクエリ言語
Solr SQLモジュールは、SQLをSolrの全文検索機能とシームレスに組み合わせることで、SolrにSQLクエリの機能をもたらします。MapReduceスタイルとJSONファセットAPI集計の両方がサポートされており、SQLクエリは高クエリボリュームと高カーディナリティの両方のユースケースをサポートするために使用できます。
モジュール
これは、使用する前に有効にする必要があるsql Solrモジュールを介して提供されます。
SQLアーキテクチャ
SQLインターフェイスを使用すると、SQLクエリをSolrに送信し、ドキュメントを応答としてストリーミングバックさせることができます。内部では、SolrのSQLインターフェイスはApache Calcite SQLエンジンを使用して、SQLクエリをストリーミング式として実装された物理クエリプランに変換します。
SolrがSolrのSQLクエリをサポートする方法の詳細については、以下の構成セクションで説明します。
SolrコレクションとDBテーブル
SELECT <式> FROM <テーブル>のような標準のSELECTステートメントでは、テーブル名はSolrコレクション名に対応します。テーブル名は大文字と小文字が区別されません。
SQLクエリの列名は、クエリ対象のコレクションのSolrインデックスのフィールドに直接マッピングされます。これらの識別子は、大文字と小文字が区別されます。エイリアスはサポートされており、ORDER BY句で参照できます。
すべてのフィールドを示すSELECT *構文は、LIMIT句を持つクエリでのみサポートされています。scoreフィールドは、LIMIT句を含むクエリでのみ使用できます。
たとえば、Solrのサンプルドキュメントにインデックスを付けてから、次のようなSQLクエリを作成できます
SELECT name_exact as name, manu as mfr, price as retail FROM techproducts ORDER BY retail DESCSolrで使用しているコレクションは「techproducts」であり、「name_exact」、「manu」、「price」フィールドを返すように要求し、「retail」というエイリアス名で並べ替えて、最も高価な製品から最も安価な製品を表示しています。
Solr SQL構文
Solrは、広範囲のSQL構文をサポートしています。
|
SQLパーサーは大文字と小文字を区別しません
SolrがSQLステートメントを変換するために使用しているSQLパーサーは、大文字と小文字を区別しません。ただし、読みやすくするために、このページのすべての例では大文字のキーワードを使用しています。 |
|
SELECT *はLIMITを使用する場合のみサポートされます
一般的に、クエリごとに返す必要があるフィールドを明示的に指定し、 |
予約語のエスケープ
SQLパーサーは、予約語がSQLクエリで使用された場合、エラーを返します。予約語はバックティックを使用してエスケープし、クエリに含めることができます。例:
select `from` from emailsSELECTステートメント
Solrは、制限付きと無制限のSELECTクエリをサポートしています。2つのタイプのクエリ間の構文は、SQLステートメントのLIMIT句を除いて同一です。ただし、実行計画とデータの格納方法に対する要件は大きく異なります。以下のセクションでは、両方のタイプのクエリについて説明します。
WHERE句とブール述語
|
WHERE句では、述語の片側にフィールドが必要です。2つの定数( |
WHERE句では、Solrの検索構文をSQLクエリに注入できます。例:
WHERE fieldC = 'term1 term2'上記の述語は、fieldC内で「term1 term2」というフレーズの全文検索を実行します。
フレーズではないクエリを実行するには、単一引用符の中に括弧を追加するだけです。例:
WHERE fieldC = '(term1 term2)'上記の述語は、fieldC内でterm1 OR term2 を検索します。
Solrの範囲クエリ構文は、次のように使用できます。
WHERE fieldC = '[0 TO 100]'複雑なブールクエリは、次のように指定できます。
WHERE ((fieldC = 'term1' AND fieldA = 'term2') OR (fieldB = 'term3'))NOTクエリを指定するには、次のようにAND NOT構文を使用します。
WHERE (fieldA = 'term1') AND NOT (fieldB = 'term2')サポートされているWHERE演算子
SQLクエリインターフェースは、最も一般的なSQL演算子をサポートし、プッシュダウンします。具体的には以下のとおりです。
| 演算子 | 説明 | 例 | Solrクエリ |
|---|---|---|---|
= |
等しい |
|
|
<> |
等しくない |
|
|
> |
より大きい |
|
|
>= |
以上 |
|
|
< |
より小さい |
|
|
<= |
以下 |
|
|
IN |
複数の値を指定します(複数のOR句の省略形)。 |
|
|
LIKE |
文字列またはテキストフィールドに対するワイルドカード一致 |
|
|
BETWEEN |
範囲一致 |
|
|
IS NULL |
null値を持つ列を照合します |
|
(*:* -field:*) |
IS NOT NULL |
値を持つ列を照合します |
|
|
-
等しくない場合は、
!=ではなく<>を使用します。 -
IN、LIKE、BETWEENは、
fielda NOT LIKE 'day%'のように、条件が真でない行を見つけるためのNOTキーワードをサポートします。 -
文字列リテラルは単一引用符で囲む必要があります。二重引用符は、文字列リテラルではなくデータベースオブジェクトを示します。
-
field = 'sam*'のように、アスタリスクワイルドカードを使用した単純なLIKEを使用できます。これはSolr固有であり、SQL標準の一部ではありません。 -
IN句の最大値数は、コレクション用に設定されたmaxBooleanClausesによって制限されます。 -
多値フィールドに対してANDで結合された範囲クエリを実行する場合、Apache Calciteは、ANDで結合された述語が互いに素なセットであるように見える場合、結果がゼロになるようにショートサーキットします。たとえば、b_is <= 2 AND b_is >= 5は、Calciteには互いに素なセットのように見えます。これは、単一値フィールドの観点からすればそうです。ただし、多値フィールドでは、Solrがドキュメントを一致させる可能性があるため、そうでない場合があります。回避策は、括弧で囲まれた等号式の中でSolrクエリ構文を直接使用することです:b_is = '(+[5 TO *] +[* TO 2])'
ORDER BY句
ORDER BY句はSolrフィールドに直接マッピングされます。複数のORDER BYフィールドと方向がサポートされています。
scoreフィールドは、制限が指定されているクエリのORDER BY句で受け入れられます。
ORDER BY句にGROUP BY句の正確なフィールドが含まれている場合、返される結果に制限は課されません。ORDER BY句にGROUP BY句とは異なるフィールドが含まれている場合、100の制限が自動的に適用されます。この制限を増やすには、LIMIT句で値を指定する必要があります。
Order byフィールドは大文字と小文字が区別されます。
OFFSETとFETCH
ORDER BY句を指定するクエリでは、OFFSET(0ベースのインデックス)およびFETCH演算子を使用して結果をページングすることもできます。FETCHなしのOFFSETはサポートされておらず、例外が生成されます。たとえば、次のクエリは10件の結果の2番目のページを要求します。
ORDER BY ... OFFSET 10 FETCH NEXT 10 ROWS ONLYSQLを使用したページングは、分散クエリが各シャードからOFFSET + LIMITドキュメントを過剰にフェッチし、各シャードの結果をソートしてクライアントに返される結果のページを生成する必要があるという点で、startとrowsを使用したSolrクエリでのページングと同じパフォーマンスペナルティを受けます。したがって、この機能は、シャードあたり最大10,000ドキュメントのページングなど、小さなOFFSET / FETCHサイズでのみ使用する必要があります。Solr SQLはハード制限を強制しませんが、結果を深く掘り下げるほど、後続のページリクエストには時間がかかり、より多くのリソースが消費されます。深いページングのためのSolrのcursorMark機能はSQLではサポートされていません。代わりに、LIMITなしのSQLクエリを使用して、/exportハンドラーを介して大きな結果セットをストリーミングします。SQLのOFFSETは、深いページングタイプのユースケース向けではありません。
LIMIT句
結果セットを指定されたサイズに制限します。上記の例では、LIMIT 100句は結果セットを100レコードに制限します。
制限付きクエリと無制限クエリの間には、いくつかの違いがあります。
-
制限付きクエリは、フィールドリストと
ORDER BYでscoreをサポートします。無制限クエリはサポートしません。 -
制限付きクエリでは、フィールドリスト内の任意の格納フィールドを使用できます。無制限クエリでは、フィールドがDocValuesフィールドとして格納されている必要があります。
-
制限付きクエリでは、
ORDER BYリスト内の任意のインデックス付きフィールドを使用できます。無制限クエリでは、フィールドがDocValuesフィールドとして格納されている必要があります。 -
フィールドがインデックス付けされているが、格納されていない、またはdocValuesがない場合、そのフィールドでフィルタリングできますが、結果で返すことはできません。
SELECT DISTINCTクエリ
SQLインターフェースは、SELECT DISTINCTクエリに対して、MapReduceとFacetの両方の実装をサポートしています。
MapReduceの実装では、タプルをワーカーノードにシャッフルし、そこでDistinct操作が実行されます。この実装では、非常に高いカーディナリティフィールドに対してDistinct操作を実行できます。
Facetの実装では、JSON Facet APIを使用してDistinct操作を検索エンジンにプッシュダウンします。この実装は、低から中程度のカーディナリティフィールドでの高性能、高QPSシナリオ向けに設計されています。
aggregationModeパラメーターは、JDBCドライバーとHTTPインターフェースの両方で、基盤となる実装(map_reduceまたはfacet)を選択するために使用できます。SQL構文は両方の実装で同一です。
SELECT distinct fieldA as fa, fieldB as fb FROM tableA ORDER BY fa desc, fb desc統計関数
SQLインターフェースは、数値フィールドで計算された簡単な統計をサポートします。サポートされている関数は、COUNT(*)、COUNT(DISTINCT field)、APPROX_COUNT_DISTINCT(field)、MIN、MAX、SUM、およびAVGです。
これらの関数はデータのシャッフルを必要としないため、集計は検索エンジンにプッシュダウンされ、統計コンポーネントによって生成されます。
SELECT COUNT(*) as count, SUM(fieldB) as sum FROM tableA WHERE fieldC = 'Hello'APPROX_COUNT_DISTINCTメトリックは、SolrのHyperLogLog(hll)統計関数を使用して、指定されたフィールドの近似カーディナリティを計算します。クエリのパフォーマンスが重要で、正確なカウントが必要ない場合に使用する必要があります。
GROUP BY集計
SQLインターフェースは、GROUP BY集計クエリもサポートします。
SELECT DISTINCTクエリと同様に、SQLインターフェースはMapReduce実装とFacet実装の両方をサポートします。MapReduce実装は、非常に高いカーディナリティフィールドに対して集計を構築できます。Facet実装は、中程度のカーディナリティを持つフィールドに対して高性能な集計を提供します。
集計を使用した基本的なGROUP BY
次に、集計を要求するGROUP BYクエリの基本的な例を示します。
SELECT fieldA as fa, fieldB as fb, COUNT(*) as count, SUM(fieldC) as sum, AVG(fieldY) as avg
FROM tableA
WHERE fieldC = 'term1 term2'
GROUP BY fa, fb
HAVING sum > 1000
ORDER BY sum asc
LIMIT 100これを分解してみましょう。
列識別子とエイリアス
列識別子には、Solrインデックスのフィールドと集計関数の両方を含めることができます。サポートされている集計関数は次のとおりです。
-
COUNT(*):一連のバケットに対するレコード数をカウントします。 -
SUM(field):一連のバケットに対する数値フィールドを合計します。 -
AVG(field):一連のバケットに対する数値フィールドの平均を求めます。 -
MIN(field):一連のバケットに対する数値フィールドの最小値を返します。 -
MAX(field):一連のバケットに対する数値フィールドの最大値を返します。
フィールドリスト内の非関数フィールドは、集計を計算するフィールドを決定します。
COUNT(DISTINCT <field>)を使用して各グループ内の特定のフィールドの一意の値の数を計算することは、現在Solrではサポートされていません。COUNT(*)のみが各GROUP BYディメンションに対して計算できます。
HAVING句
HAVING句には、フィールドリストにリストされている任意の関数を含めることができます。次のような複雑なHAVING句がサポートされています。
SELECT fieldA, fieldB, COUNT(*), SUM(fieldC), AVG(fieldY)
FROM tableA
WHERE fieldC = 'term1 term2'
GROUP BY fieldA, fieldB
HAVING ((SUM(fieldC) > 1000) AND (AVG(fieldY) <= 10))
ORDER BY SUM(fieldC) ASC
LIMIT 100集計モード
SolrのSQL機能は、次の2つの方法で集計(結果のグループ化)を処理できます。
-
facet:これは、JSON Facet APIまたは集計用のStatsComponentを使用するデフォルトの集計モードです。このシナリオでは、集計ロジックは検索エンジンにプッシュダウンされ、集計のみがネットワーク経由で送信されます。これは、Solrの通常の動作モードです。これは、GROUP BYフィールドのカーディナリティが低いから中程度の場合に高速です。ただし、GROUP BYフィールドに高いカーディナリティフィールドがある場合は、機能しなくなります。 -
map_reduce:この実装では、タプルをワーカーノードにシャッフルし、ワーカーノードで集計を実行します。これには、結果セット全体をソートおよびパーティション化し、それをワーカーノードに送信することが含まれます。このアプローチでは、タプルはGROUP BYフィールドでソートされたワーカーノードに到着します。これにより、ワーカーノードは集計を一度に1グループずつロールアップできます。これにより、無制限のカーディナリティ集計が可能になりますが、結果セット全体をネットワーク経由でワーカーノードに送信するコストがかかります。
これらのモードは、Solrにリクエストを送信するときにaggregationModeプロパティで定義されます。
集計モードの選択は、操作対象のフィールドのカーディナリティに依存します。グループ化に使用するフィールドのカーディナリティが低いから中程度の場合、「facet」集計モードの方がパフォーマンスが高くなります。これは、最終的なグループのみが返されるため、現在のファセットの動作と非常によく似ています。ただし、フィールドのカーディナリティが高い場合は、ワーカーノードを使用した「map_reduce」集計モードの方がはるかに優れたパフォーマンスを提供します。
設定
SQLインターフェースで使用されるリクエストハンドラーは暗黙的にロードされるように設定されているため、この機能を使用開始するにあたって特別な操作はほとんど必要ありません。
/sql リクエストハンドラー
/sql ハンドラーは、Parallel SQLインターフェースのフロントエンドです。すべてのSQLクエリは、処理のために /sql ハンドラーに送信されます。また、このハンドラーは、map_reduce モードで GROUP BY および SELECT DISTINCT クエリを実行する際に、分散MapReduceジョブを調整します。デフォルトでは、/sql ハンドラーは、分散処理を処理するために自身のコレクションからワーカーノードを選択します。このデフォルトシナリオでは、/sql ハンドラーが存在するコレクションが、MapReduceクエリのデフォルトのワーカーコレクションとして機能します。
デフォルトでは、/sql リクエストハンドラーは暗黙的なハンドラーとして設定されています。つまり、すべてのSolrインストールで常に有効になっており、追加の設定は必要ありません。
SQLリクエストの認証
Solrクラスターがルールベース認証プラグインを使用するように設定されている場合、SQLクエリを実行するすべてのコレクションに対して、/sql, /select, および /export エンドポイントに対する GET および POST 権限を付与する必要があります。/select エンドポイントは LIMIT クエリに使用され、/export ハンドラーは LIMIT がないクエリに使用されるため、ほとんどの場合、両方へのアクセス権を付与することになります。/sql ハンドラーのワーカーコレクションを使用している場合は、データ層のコレクションではなく、ワーカーコレクションの /sql エンドポイントへのアクセス権のみを付与する必要があります。裏側では、SQLハンドラーは、コレクションのスキーマメタデータを取得するために、内部のSolrサーバーIDを使用して /admin/luke エンドポイントにもリクエストを送信します。したがって、ユーザーがSQLクエリを実行するために、/admin/luke エンドポイントへの明示的な権限を付与する必要はありません。
|
以下のベストプラクティスのセクションで説明するように、並列化されたSQLクエリ用に個別のコレクションを設定することもできます。カーディナリティの高いフィールドと大量のデータがある場合は、必ずそのセクションを確認し、個別のコレクションの使用を検討してください。 |
/stream および /export リクエストハンドラー
Streaming APIは、SolrCloud用の拡張可能な並列コンピューティングフレームワークです。Streaming Expressionsは、Streaming APIのクエリ言語とシリアル化フォーマットを提供します。
Streaming APIは、高速MapReduceのサポートを提供し、非常に大きなデータセットに対して並列リレーショナル代数を実行できます。内部では、SQLインターフェースはApache Calcite SQLパーサーを使用してSQLクエリを解析します。その後、クエリを並列クエリプランに変換します。並列クエリプランは、Streaming APIとStreaming Expressionsを使用して表現されます。
/sql リクエストハンドラーと同様に、/stream および /export リクエストハンドラーは暗黙的なハンドラーとして設定されているため、追加の設定は必要ありません。
フィールド
場合によっては、SQLクエリで使用されるフィールドは、DocValueフィールドとして設定する必要があります。クエリに制限がない場合、すべてのフィールドがDocValueフィールドである必要があります。クエリが制限されている場合(limit 句を使用)、フィールドでDocValuesを有効にする必要はありません。
|
複数値フィールド
プロジェクトリスト内の複数値フィールドは、値の |
JDBCドライバー
JDBCドライバーはSolrJに同梱されています。以下は、JDBCドライバーを使用して接続を作成し、クエリを実行するサンプルコードです。
Connection con = null;
try {
con = DriverManager.getConnection("jdbc:solr://" + zkHost + "?collection=collection1&aggregationMode=map_reduce&numWorkers=2");
stmt = con.createStatement();
rs = stmt.executeQuery("SELECT a_s, sum(a_f) as sum FROM collection1 GROUP BY a_s ORDER BY sum desc");
while(rs.next()) {
String a_s = rs.getString("a_s");
double s = rs.getDouble("sum");
}
} finally {
rs.close();
stmt.close();
con.close();
}接続URLには、zkHost と collection パラメーターを含める必要があります。コレクションは、指定されたZooKeeperホストにある有効なSolrCloudコレクションである必要があります。また、コレクションは /sql ハンドラーで設定する必要があります。aggregationMode パラメーターと numWorkers パラメーターはオプションです。
HTTPインターフェース
Solrは、/sql ハンドラーを介してSQLクエリを受け付けます。
以下は、ファセットモードでSQL集計クエリを実行するサンプルcurlコマンドです。
curl --data-urlencode 'stmt=SELECT to, count(*) FROM collection4 GROUP BY to ORDER BY count(*) desc LIMIT 10' https://:8983/solr/collection4/sql?aggregationMode=facet以下は、サンプル結果セットです。
{"result-set":{"docs":[
{"count(*)":9158,"to":"pete.davis@enron.com"},
{"count(*)":6244,"to":"tana.jones@enron.com"},
{"count(*)":5874,"to":"jeff.dasovich@enron.com"},
{"count(*)":5867,"to":"sara.shackleton@enron.com"},
{"count(*)":5595,"to":"steven.kean@enron.com"},
{"count(*)":4904,"to":"vkaminski@aol.com"},
{"count(*)":4622,"to":"mark.taylor@enron.com"},
{"count(*)":3819,"to":"kay.mann@enron.com"},
{"count(*)":3678,"to":"richard.shapiro@enron.com"},
{"count(*)":3653,"to":"kate.symes@enron.com"},
{"EOF":"true","RESPONSE_TIME":10}]}
}結果セットは、SQL列リストに一致するキーと値のペアを持つタプルの配列であることに注意してください。最後のタプルには、ストリームの終わりを示すEOFフラグが含まれています。
ベストプラクティス
個別のワーカーコレクション
/sql ハンドラー専用の個別のSolrCloudワーカーコレクションを作成することをお勧めします。このコレクションは、SolrCloudの標準コレクションAPIを使用して作成できます。
このコレクションは /sql リクエストを処理し、ワーカーノードのプールを提供する目的でのみ存在するため、データを保持する必要はありません。ワーカーノードは、/sql ハンドラーのコレクション内の使用可能なノードのプール全体からランダムに選択されます。したがって、このコレクションを動的に拡張するには、既存のシャードにレプリカを追加できます。新しいレプリカは、追加されると自動的に作業を開始します。
並列SQLクエリ
前のセクションでは、SQLインターフェースがSQLステートメントをストリーミング式に変換する方法について説明しました。リクエストのパラメーターの1つに aggregationMode があり、これは、クエリがMapReduceのようなシャッフル手法を使用するか、検索エンジンに操作をプッシュダウンするかを定義します。
並列化されたクエリ
Parallel SQLアーキテクチャは、SQL層、ワーカー層、およびデータテーブル層の3つの論理層で構成されています。デフォルトでは、SQL層とワーカー層は、同じ物理SolrCloudコレクションにまとめられています。
SQL層
SQL層は、/sql ハンドラーが存在する場所です。/sql ハンドラーはSQLクエリを取得し、それを並列クエリプランに変換します。次に、プランを実行するワーカーノードを選択し、並列で実行されるように各ワーカーノードにクエリプランを送信します。
ワーカーノードによってクエリプランが実行されると、/sql ハンドラーは、ワーカーノードによって返されたタプルの最終的なマージを実行します。
ワーカー層
ワーカー層のワーカーは、/sql ハンドラーからクエリプランを受け取り、並列クエリプランを実行します。並列実行プランには、データテーブル層で行う必要があるクエリと、クエリを満たすために必要なリレーショナル代数が含まれます。クエリに割り当てられた各ワーカーノードは、データテーブルからのタプルの1/Nをシャッフルします。ワーカーノードはクエリプランを実行し、タプルをワーカーノードにストリーミングバックします。
データテーブル層
データテーブル層は、テーブルが存在する場所です。各テーブルは、独自のSolrCloudコレクションです。データテーブル層は、ワーカーノードからクエリを受け取り、タプル(検索結果)を出力します。データテーブル層は、ワーカーに送信されるタプルの初期ソートとパーティション分割も処理します。これは、タプルがネットワークに到達する前に、常にソートおよびパーティション分割されることを意味します。パーティション分割されたタプルは、削減の準備が整った状態で、正しいソート順で正しいワーカーノードに直接送信されます。
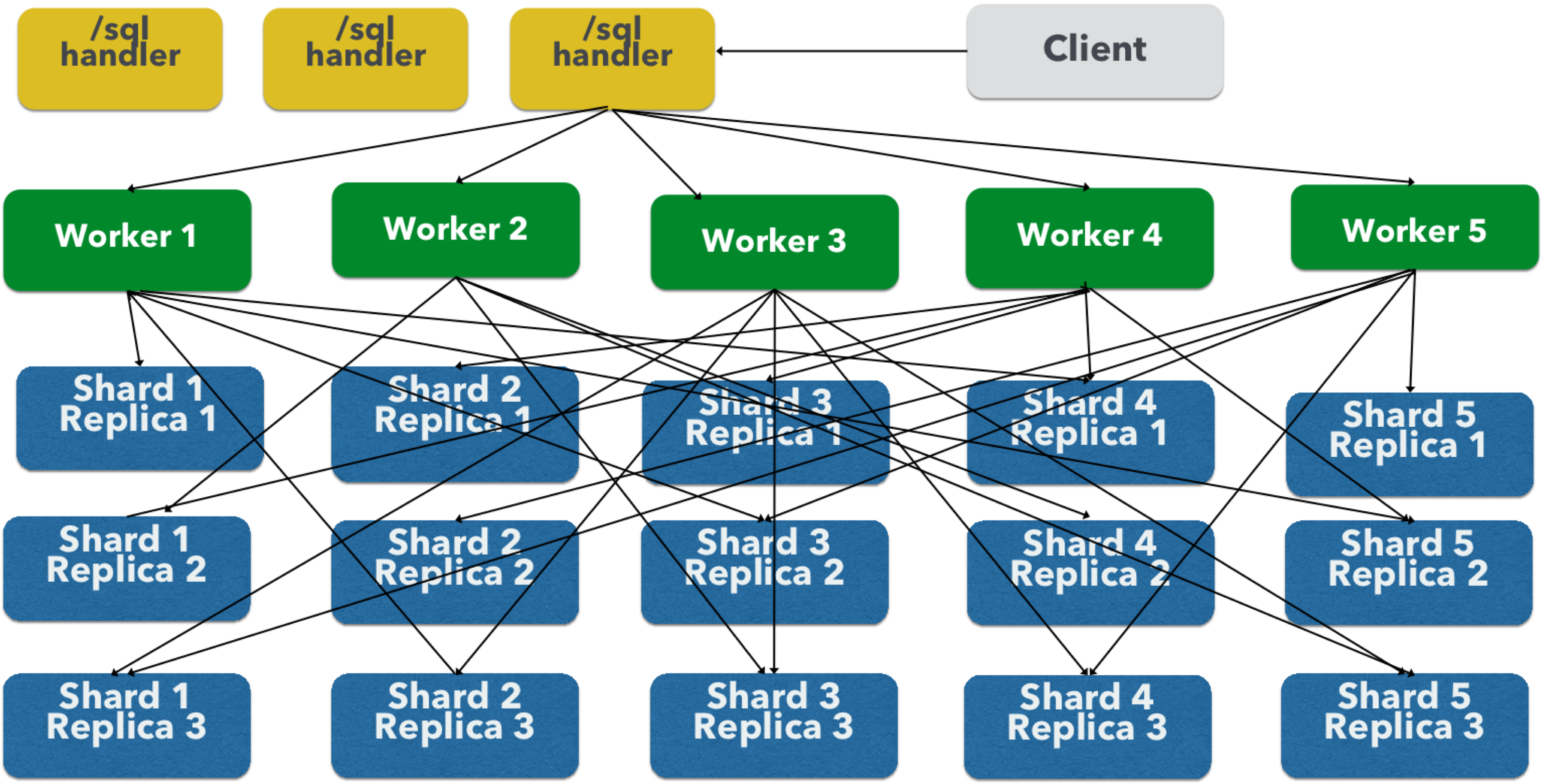
上の図は、分かりやすくするために、3つの層を異なるSolrCloudコレクションに分割して示しています。実際には、/sql ハンドラーとワーカーコレクションは、デフォルトで同じコレクションを共有しています。
図は、単一の並列SQLクエリ(MapReduce上のSQL)のネットワークフローを示しています。このネットワークフローは、GROUP BY 集計または SELECT DISTINCT クエリで map_reduce 集計モードが使用される場合に使用されます。従来のSolrCloudネットワークフロー(ワーカーなし)は、facet 集計モードが使用される場合に使用されます。 |
以下は、フローの説明です。
-
クライアントは、
/sqlハンドラーにSQLクエリを送信します。リクエストは、単一の/sqlハンドラーインスタンスによって処理されます。 -
/sqlハンドラーは、SQLクエリを解析し、並列クエリプランを作成します。 -
クエリプランは、ワーカーノード(緑色)に送信されます。
-
ワーカーノードは、プランを並行して実行します。図は、各ワーカーノードがデータテーブル層(青色)のコレクションに接続している様子を示しています。
-
データテーブル層のコレクションは、SQLクエリからのテーブルです。コレクションには、それぞれ3つのレプリカを持つ5つのシャードがあることに注意してください。
-
各ワーカーが各シャードから1つのレプリカに接続していることに注意してください。5つのワーカーがあるため、各ワーカーには、各シャードからの検索結果の1/5が返されます。パーティション分割はデータテーブル層内で行われるため、ネットワーク間でデータが重複することはありません。
-
また、この設計では、データ層のすべてのレプリカが同時にデータをシャッフル(ソートとパーティション分割)していることにも注意してください。シャード、レプリカ、ワーカーの数が増えるにつれて、この設計により、単一のクエリに膨大な計算能力を適用できます。
-
ワーカーノードは、データテーブル層から返されたタプルを並行して処理します。ワーカーノードは、クエリプランを満たすために必要なリレーショナル代数を実行します。
-
ワーカーノードは、タプルを
/sqlハンドラーにストリーミングバックします。/sqlハンドラーでは、最終的なマージが行われ、最終的にタプルがクライアントにストリーミングバックされます。
SQLクライアントとデータベース視覚化ツール
SQLインターフェースは、SQLクライアントおよびデータベース視覚化ツールから送信されたクエリをサポートします。
このガイドには、次のツールとクライアントを設定するためのドキュメントが含まれています。
汎用クライアント
ほとんどのJavaベースのクライアントでは、次のjarをクライアントのクラスパスに配置する必要があります。
-
$SOLR_TIP/server/solr-webapp/webapp/WEB-INF/lib/*および$SOLR_TIP/server/lib/ext/*にあるSolrJ依存関係の.jar。Solrディストリビューションでは、これらの依存関係はSolrの依存関係から分離されていないため、すべてを含めるか、必要な正確なセットを手動で選択する必要があります。お使いのバージョンに必要な正確な依存関係については、mavenリリースを参照してください。 -
$SOLR_TIP/server/solr-webapp/webapp/WEB-INF/lib/solr-solrj-<version>.jarにあるSolrJ.jar。
Mavenを使用している場合は、org.apache.solr.solr-solrj アーティファクトに必要なjarが含まれています。
jarがクラスパスで使用可能になると、Solr JDBCドライバー名は org.apache.solr.client.solrj.io.sql.DriverImpl になり、次の接続文字列形式で接続できます。
jdbc:solr://SOLR_ZK_CONNECTION_STRING?collection=COLLECTION_NAME接続文字列には、aggregationMode や numWorkers のように、オプションで追加できる他のパラメーターもあります。