分析画面
スキーマでフィールドタイプを定義し、適用する分析手順を指定したら、期待通りに動作することを確認するためにテストする必要があります。
幸いなことに、Solr管理UIには、まさにそれを実行できる非常に便利なページがあります。任意のテキストフィールドのアナライザーを起動し、サンプル入力を入力し、結果のトークンストリームを表示できます。
たとえば、bin/solr -e techproductsのサンプル設定で使用可能な「テキスト」フィールドタイプをいくつか見て、分析画面(https://:8983/solr/#/techproducts/analysis)を使用して、「Running an Analyzer」という文のインデックス作成時に生成されたトークンが、「run my analyzer」というわずかに異なるクエリテキストとどのように一致するかを比較してみましょう。
最も単純化されたテキストフィールドタイプの1つであるtext_wsから始めましょう。
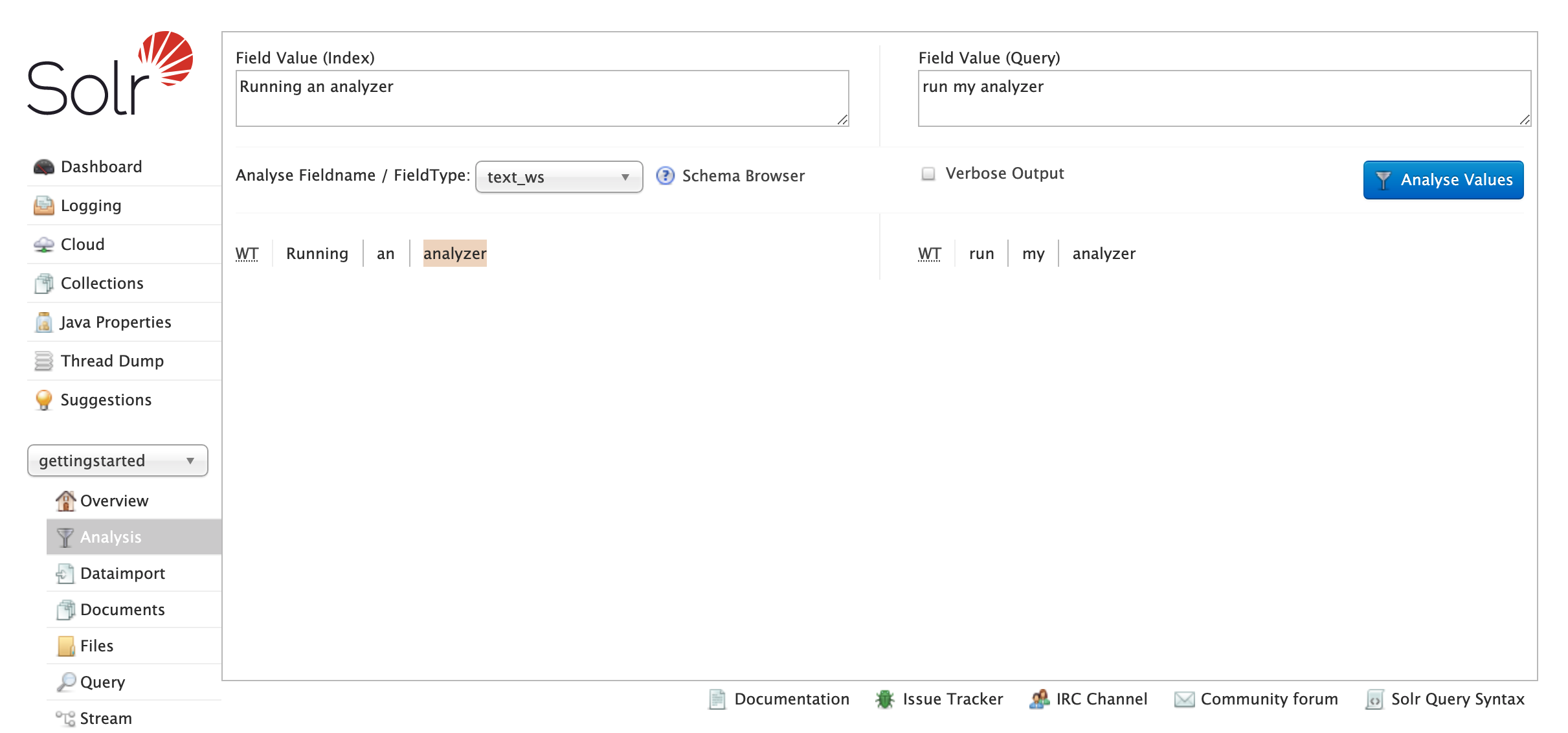
これは、分析の各ステップ(この場合は単一ステップ)で生成されたトークンのみの単純な出力を示しています。トークナイザーは省略形で表示されます。完全な名前を確認するには、マウスオーバーまたはクリックしてください。
チェックボックスをオンにして**詳細出力**を有効にすると、詳細が表示されます。
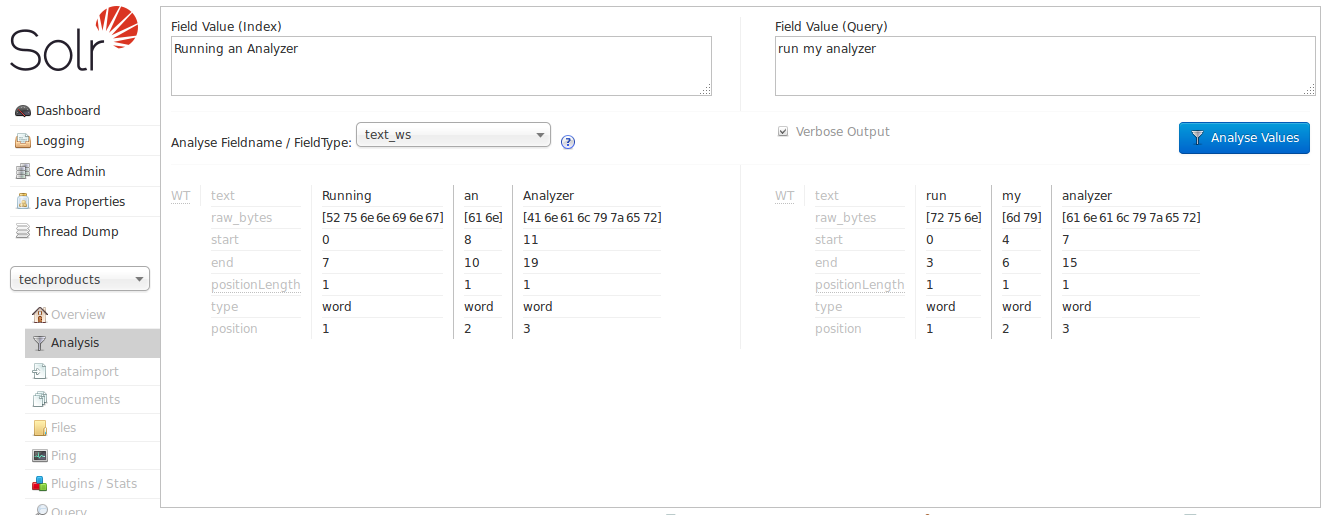
各用語の開始位置と終了位置を見ると、このフィールドタイプが行う唯一のことは、空白でテキストをトークン化することであることがわかります。この画像では、「Running」という用語の開始位置は0、終了位置は7、「an」の開始位置は8、終了位置は10、「Analyzer」の開始位置は11、終了位置は19です。用語間の空白も含まれている場合、カウントは21になります。19なので、空白がこのクエリから削除されていることがわかります。
また、インデックス付き用語とクエリ用語は依然として大きく異なっていることにも注意してください。「Running」は「run」と一致せず、「Analyzer」は「analyzer」と一致せず(コンピューターにとっては)、明らかに「an」と「my」はまったく異なる単語です。「run my analyzer」のようなクエリで「Running an Analyzer」のようなインデックス付きテキストを照合できるようにするには、入力の処理をより多く行うインデックス時およびクエリ時のテキスト分析を備えた別のフィールドタイプを選択する必要があります。
特に、次のことが必要です。
-
大文字と小文字を区別しないように、「Analyzer」と「analyzer」が一致するようにします。
-
ステミングを行い、「Run」や「Running」のような単語が同等の用語と見なされるようにします。
-
ストップワードの削除を行い、「an」や「my」のような小さな単語がクエリに影響しないようにします。
次の試みとして、text_generalフィールドタイプを試してみましょう。
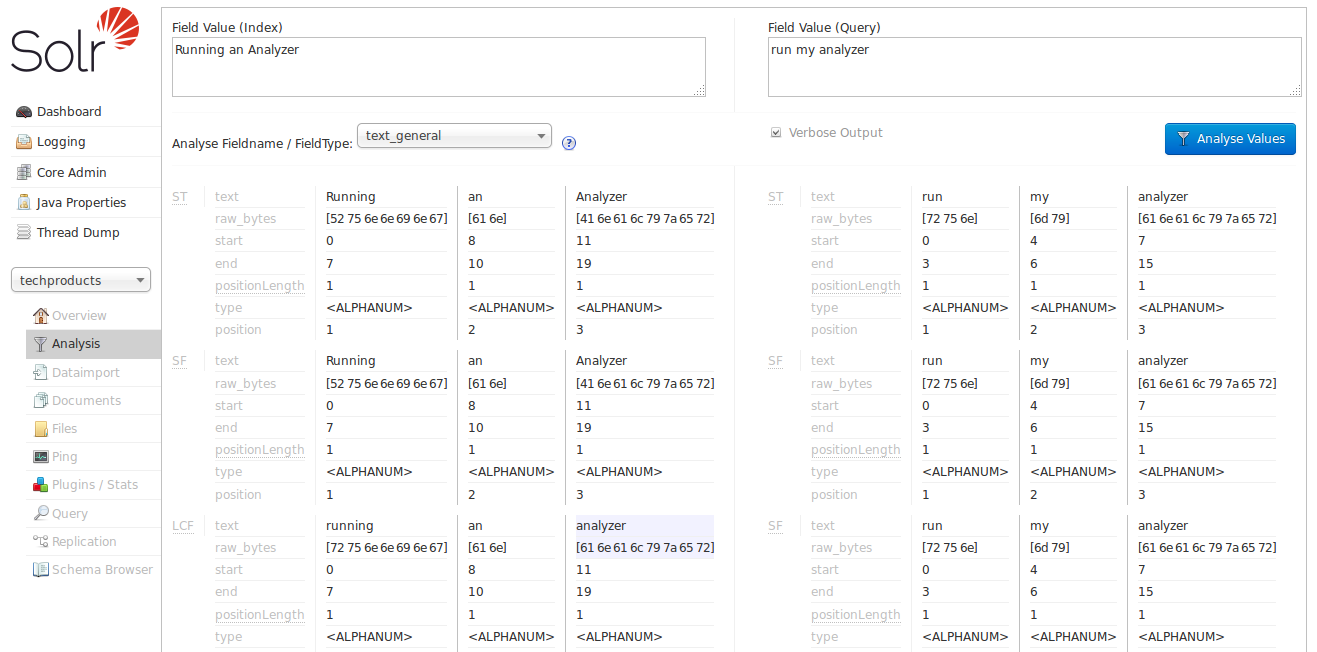
詳細出力を有効にすると、新しいアナライザーの各ステージが、トークンを次のステージに渡す前にどのように変更するかを確認できます。最後までスクロールダウンすると、各入力文字列から「analyzer」の一致が得られ始めていることがわかります。これは、マウスオーバーするとLowerCaseFilterである「LCF」ステージのおかげです。
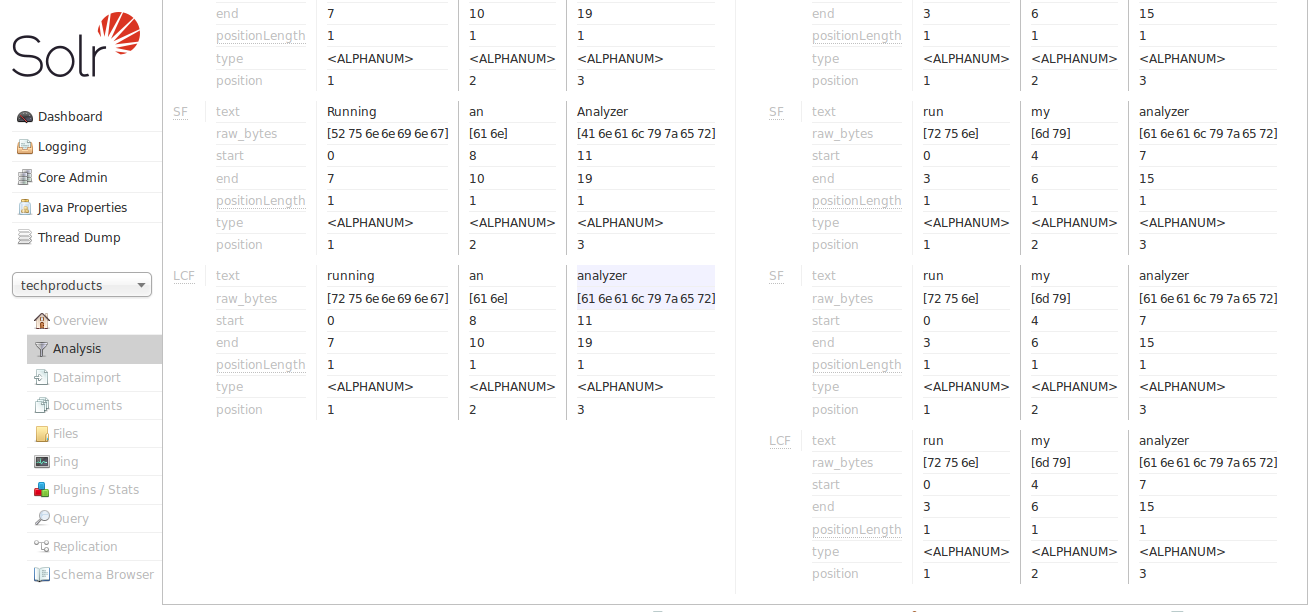
text_generalフィールドタイプは、どの言語でも一般的に役立つように設計されており、最初の例でtext_wsよりも、大文字と小文字の区別の問題を解決することで、目標に近づきました。それでも、ステミングやストップワードルールが適用されていないため、まだ求めているものではありません。それでは、text_enフィールドタイプを試してみましょう。
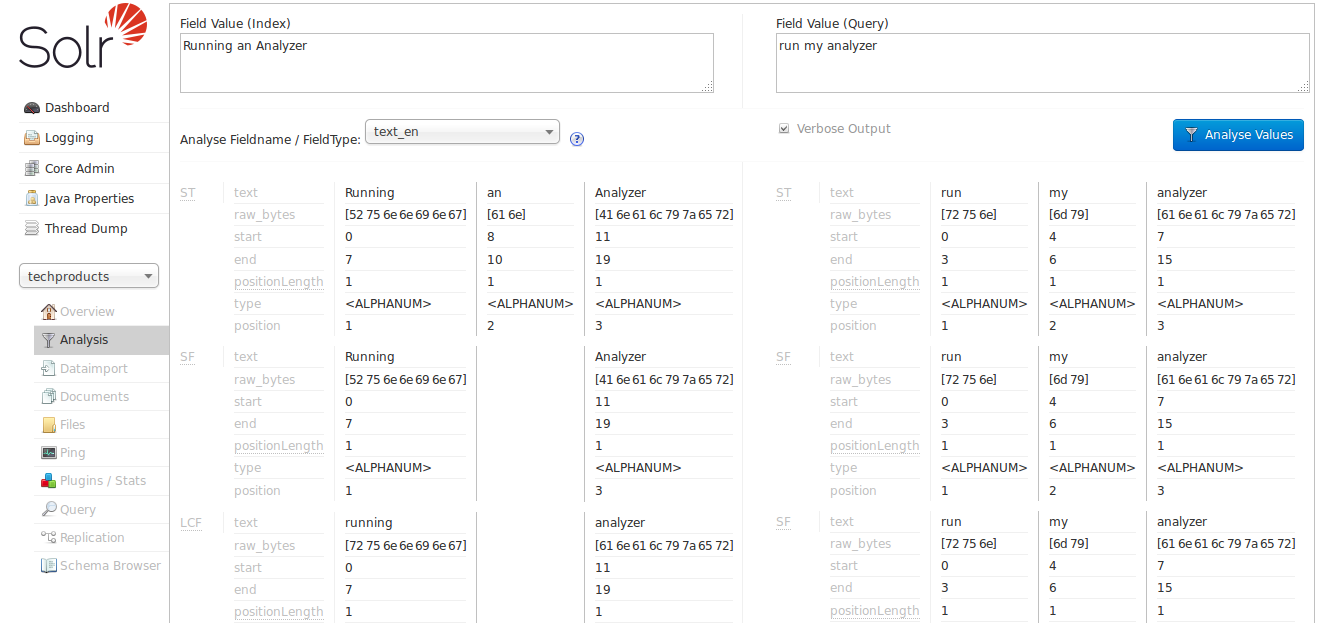
これで、アナライザーの「SF」(StopFilter)ステージがストップワード(「an」)を削除する問題を解決していることがわかります。下にスクロールすると、「PSF」(PorterStemFilter)ステージが英語入力に適したステミングルールを適用していることもわかります。「index analyzer」によって生成された用語と「query analyzer」によって生成された用語が期待どおりに一致します。

この時点で、フィールドタイプの構成を繰り返し調整しながら、追加の入力で実験を続けることができます。アナライザーが期待通りに一致するトークンを生成すること、また、一致しないことが予想される場合は異なるトークンを生成することを検証します。