インデックスセグメントとマージ
Lucene インデックスはセグメントに格納され、Solr は新しいセグメントの書き込み方法とセグメントのマージ時期を制御するためのいくつかのパラメーターを提供します。
Lucene インデックスは「1 回書き込み」ファイルです。セグメントが永続ストレージ (ディスク) に書き込まれると、変更されることはありません。つまり、インデックスは実際には、フルインデックスのサブセットであるいくつかのファイルで構成されています。インデックスの永続的な断片化を防ぐために、セグメントは定期的にマージされます。
solrconfig.xml の <indexConfig>
solrconfig.xml の <indexConfig> セクションでは、Lucene インデックスライターの低レベルの動作を定義します。
デフォルトでは、設定は Solr に含まれるサンプルの solrconfig.xml でコメントアウトされています。これは、デフォルトが使用されることを意味します。ほとんどの場合、デフォルトで問題ありません。
<indexConfig>
...
</indexConfig>新しいセグメントの書き込み
次の要素は、<indexConfig> 要素の下で定義でき、新しいセグメントがディスクに書き込まれる (「フラッシュ」される) タイミングを定義します。
ramBufferSizeMB
累積されたドキュメントの更新がこのメモリ空間 (メガバイト単位で定義) を超えると、保留中の更新がフラッシュされます。これにより、新しいセグメントが作成されたり、マージがトリガーされたりすることもあります。この設定を使用することをお勧めします。maxBufferedDocs よりも優先されます。maxBufferedDocs と ramBufferSizeMB の両方が solrconfig.xml で設定されている場合、いずれかの制限に達するとフラッシュが発生します。デフォルトは 100 MB です。
<ramBufferSizeMB>100</ramBufferSizeMB>maxBufferedDocs
新しいセグメントとしてフラッシュされる前にメモリにバッファリングするドキュメント更新の数を設定します。これにより、マージがトリガーされることもあります。デフォルトの Solr 構成では、RAM 使用量 (ramBufferSizeMB) でフラッシュするように設定されています。
<maxBufferedDocs>1000</maxBufferedDocs>useCompoundFile
新しく書き込まれた (まだマージされていない) インデックスセグメントが 複合ファイルセグメント形式を使用するかどうかを制御します。デフォルトは false です。
<useCompoundFile>false</useCompoundFile>インデックスセグメントのマージ
次の設定では、セグメントがマージされるタイミングを定義します。
mergePolicyFactory
セグメントのマージ方法を定義します。
Solr のデフォルトは TieredMergePolicy を使用することです。これは、階層ごとのセグメントの許容数に応じて、ほぼ同じサイズのセグメントをマージします。
その他の利用可能なポリシーは、LogByteSizeMergePolicy および LogDocMergePolicy です。これらのポリシーの詳細については、MergePolicy javadocs を参照してください。
<mergePolicyFactory class="org.apache.solr.index.TieredMergePolicyFactory">
<int name="maxMergeAtOnce">10</int>
<int name="segmentsPerTier">10</int>
<double name="forceMergeDeletesPctAllowed">10.0</double>
<double name="deletesPctAllowed">33.0</double>
</mergePolicyFactory>セグメントサイズの制御
TieredMergePolicy (または LogByteSizeMergePolicy) の構成に対してユーザーが行う最も一般的な調整は、「マージファクター」です。これは、一度にマージする必要があるセグメントの数と、TieredMergePolicy の場合は、マージされたセグメントの最大サイズを変更するためのものです。
TieredMergePolicy の場合、これは maxMergeAtOnce (デフォルト 10)、segmentsPerTier (デフォルト 10)、および maxMergedSegmentMB (デフォルト 5000) オプションを設定することで制御されます。
LogByteSizeMergePolicy には、単一の mergeFactor オプション (デフォルト 10) があります。
これらのオプションが重要な理由を理解するために、LogByteSizeMergePolicy を使用してインデックスを更新した場合に何が起こるかを考えてみましょう。ドキュメントは常に、最も最近開かれたセグメントに追加されます。セグメントがいっぱいになると、新しいセグメントが作成され、後続の更新がそこに配置されます。
新しいセグメントを作成すると、最下位レベルのセグメント数がmergeFactorの値を超えてしまう場合、それらのセグメントはすべて結合されて、単一の大きなセグメントを形成します。したがって、マージファクターが10の場合、各マージは、10個の構成要素のそれぞれよりも約10倍大きい単一のセグメントの作成につながります。これらの大きなセグメントが10個存在すると、それらはさらに大きな単一のセグメントに結合されます。このプロセスは、無期限に継続できます。
TieredMergePolicyを使用する場合、プロセスは同じですが、単一のmergeFactor値の代わりに、segmentsPerTier設定がマージを行うべきかどうかを決定するためのしきい値として使用され、maxMergeAtOnce設定はマージに含めるセグメント数を決定します。
最適なマージファクターの選択は、一般的にインデックス作成速度と検索速度のトレードオフです。インデックス内のセグメント数を少なくすると、検索場所が減るため、通常は検索が高速化されます。また、ディスク上の物理ファイル数も少なくなる可能性があります。ただし、セグメント数を少なく保つために、マージがより頻繁に発生し、システムへの負荷が増加し、インデックスの更新が遅くなる可能性があります。
逆に、セグメント数を多くすると、マージの発生頻度が少なくなり、更新がマージを引き起こす可能性が低くなるため、インデックス作成が高速化される可能性があります。しかし、検索は計算コストが高くなり、検索語句をより多くのインデックスセグメントで検索する必要があるため、速度が低下する可能性があります。インデックスの更新が速いということは、コミットのターンアラウンドタイムが短くなることも意味し、よりタイムリーな検索結果が得られることにつながります。
削除済みドキュメントの割合の制御
ドキュメントが削除または更新されると、ドキュメントは削除済みとしてマークされますが、セグメントがマージされるまでインデックスから削除されません。デフォルトのTieredMergePolicyを使用する場合、インデックス内の削除済みドキュメント数に影響を与える可能性のある2つのパラメーターを調整できます。
forceMergeDeletesPctAllowed-
オプション
デフォルト:
10.0外部
expungeDeletesコマンドが発行されると、このパーセントを超える削除済みドキュメントを持つセグメントは新しいセグメントにマージされ、削除済みドキュメントに関連付けられたデータは消去されます。0.0の値にすると、expungeDeletesは実質的にoptimizeと同じように動作します。 deletesPctAllowed-
オプション
デフォルト:
33.0通常のセグメントマージ中、インデックス内の削除済みドキュメントの合計パーセンテージがこのしきい値を下回るように最善の努力が払われます。有効な設定値は20%から50%の間です。33%がデフォルトとして選択されたのは、この設定が20%に近づくと、システムにかなりの負荷がかかるためです。
マージポリシーのカスタマイズ
組み込みのマージポリシーの設定オプションがユースケースに完全には適していない場合、設定で指定するカスタムのマージポリシーファクトリを作成するか、wrapped.prefix設定オプションを使用して、ラップするファクトリの設定方法を制御するマージポリシーラッパーを設定することで、カスタマイズできます。
<mergePolicyFactory class="org.apache.solr.index.SortingMergePolicyFactory">
<str name="sort">timestamp desc</str>
<str name="wrapped.prefix">inner</str>
<str name="inner.class">org.apache.solr.index.TieredMergePolicyFactory</str>
<int name="inner.maxMergeAtOnce">10</int>
<int name="inner.segmentsPerTier">10</int>
</mergePolicyFactory>上記の例は、SolrのSortingMergePolicyFactoryが、マージされたセグメント内のドキュメントを"timestamp desc"でソートするように構成されており、TieredMergePolicyFactoryをラップして、SortingMergePolicyFactoryのwrapped.prefixオプションによって定義されたinnerプレフィックスを介して、maxMergeAtOnce=10とsegmentsPerTier=10の値を使用するように構成されていることを示しています。SortingMergePolicyFactoryの使用の詳細については、segmentTerminateEarlyパラメーターを参照してください。
mergeScheduler
マージスケジューラーは、マージの実行方法を制御します。デフォルトのConcurrentMergeSchedulerは、別のスレッドを使用してバックグラウンドでマージを実行します。代替のSerialMergeSchedulerは、別のスレッドを使用してマージを実行しません。
ConcurrentMergeSchedulerには、次の構成可能な属性があります。これらの属性のデフォルトは、基盤となるディスクドライブが回転ディスクであるかどうかに基づいて動的に設定されます。詳細については、ConcurrentMergeSchedulerの動的デフォルトを参照してください。
maxMergeCount-
オプション
デフォルト: なし
許可される同時マージの最大数。マージが必要だが、すでにこの数のスレッドが実行中の場合、マージスレッドが完了するまでインデックス作成スレッドはブロックされます。Solrは、一度に最小の
maxThreadCountマージのみを実行することに注意してください。 maxThreadCount-
オプション
デフォルト: なし
一度に実行する必要がある同時マージスレッドの最大数。これは
maxMergeCountより小さくする必要があります。 ioThrottle-
オプション
デフォルト: なし
I/Oスロットリングを明示的に制御するためのブール値(
trueまたはfalse)。デフォルトではスロットリングが有効になっており、CMSは、他の(検索、インデックス作成)に余裕を持たせるために、マージ時のI/Oスループットを制限します。
<mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler"/><mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler">
<int name="maxMergeCount">9</int>
<int name="maxThreadCount">4</int>
</mergeScheduler>mergedSegmentWarmer
ニアリアルタイムユースケースにSolrを使用する場合、マージされたセグメントウォーマーを構成して、マージのコミット前に、新しくマージされたセグメントのリーダーをウォームアップできます。これはニアリアルタイム検索には必須ではありませんが、マージ完了後に新しいニアリアルタイムリーダーを開く際の検索レイテンシーを削減します。
<mergedSegmentWarmer class="org.apache.lucene.index.SimpleMergedSegmentWarmer"/>複合ファイルセグメント
各Luceneセグメントは、通常、10数個のファイルで構成されています。Solrは、Luceneセグメントのすべてのファイルを、.cfsというファイル拡張子を持つ単一の複合ファイルにバンドルするように構成できます。これは「複合ファイルセグメント」を意味します。
CFSセグメントは、ランタイム環境によっては、さまざまな理由でわずかなパフォーマンス低下が発生する可能性があります。たとえば、ファイルシステムバッファーは通常、オープンファイル記述子に関連付けられており、これにより各インデックスで使用できる合計キャッシュスペースが制限される可能性があります。
プロセスごとに許可されるオープンファイル数が制限されているシステムでは、CFSは制限に達するのを回避できる可能性があります。オープンファイルの制限は、Linux/Unixのulimitコマンドや、他のオペレーティングシステムの場合は同様のコマンドを使用して、OSで調整することもできます。
|
CFS: 新しいセグメントとマージされたセグメント
新しく書き込まれたセグメントでCFSを使用するかどうかを構成するには、上記で説明した 多くのマージポリシー実装では、大きなセグメントに複合ファイルが使用されないようにするデフォルト値を持つ |
セグメント情報画面
管理UIのセグメント情報画面では、このコアの基盤となるLuceneインデックスのさまざまなセグメントを視覚化し、各セグメントのサイズ(バイト単位とドキュメント数)と、それらのセグメントに関するその他の基本的なメタデータを確認できます。最も目立つのは削除されたドキュメントの数ですが、セグメントにマウスカーソルを合わせると、追加の数値の詳細が表示されます。
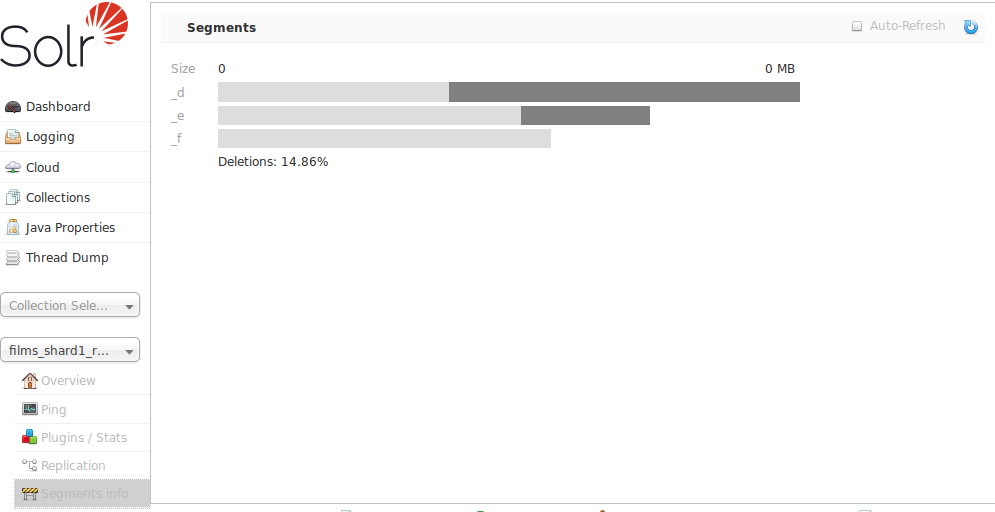
この情報は、データに最適なマージ設定について意思決定を行うのに役立つ可能性があります。
インデックスロック
lockType
LockFactoryオプションは、使用するロックの実装を指定します。
有効なロックタイプのオプションのセットは、構成したDirectoryFactoryによって異なります。
以下にリストされている値は、StandardDirectoryFactory (デフォルト) でサポートされています。
-
native(デフォルト) は、NativeFSLockFactoryを使用してネイティブOSのファイルロックを指定します。2番目のSolrプロセスがディレクトリにアクセスしようとすると、失敗します。複数のSolr Webアプリケーションが単一のインデックスを共有しようとしている場合は使用しないでください。NativeFSLockFactory javadocsも参照してください。 -
simpleは、SimpleFSLockFactoryを使用して、ロック用のプレーンファイルを指定します。SimpleFSLockFactory javadocsも参照してください。 -
single(エキスパート) は、SingleInstanceLockFactoryを使用します。読み取り専用のインデックスディレクトリの場合、または複数のプロセスがインデックスを (順次でも) 変更しようとする可能性がない特別な状況で使用します。このタイプは、同じJVM内の複数のコアが同じインデックスにアクセスしようとするのを防ぎます。異なるJVM内の複数のSolrインスタンスがインデックスを変更する場合、このタイプはインデックスの破損を防ぎません。 SingleInstanceLockFactory javadocsも参照してください。
-
hdfsは、HdfsLockFactoryを使用して、HDFSファイルシステムに対するインデックスファイルおよびトランザクションログファイルの読み取りと書き込みをサポートします。この機能の使用に関する詳細については、HDFS上のSolrセクションを参照してください。
<lockType>native</lockType>その他のインデックス作成設定
実装用に構成することが重要な可能性のあるいくつかのパラメーターがあります。これらの設定は、インデックスへの更新方法またはタイミングに影響します。
deletionPolicy
ロールバックの場合のコミットの保持方法を制御します。デフォルトはSolrDeletionPolicyで、次のパラメーターを使用します。
maxCommitsToKeep-
オプション
デフォルト: なし
保持するコミットの最大数。
maxOptimizedCommitsToKeep-
オプション
デフォルト: なし
保持する最適化されたコミットの最大数。
maxCommitAge-
オプション
デフォルト: なし
保持するコミットの最大経過時間。これは
DateMathParser構文をサポートしています。
<deletionPolicy class="solr.SolrDeletionPolicy">
<str name="maxCommitsToKeep">1</str>
<str name="maxOptimizedCommitsToKeep">0</str>
<str name="maxCommitAge">1DAY</str>
</deletionPolicy>