データの読み込み
ストリーミング式は、CSV と TSV 形式のデータの読み取り、解析、変換、視覚化、読み込みをサポートしています。これらの関数は、データ準備に費やす時間を短縮し、データが Solr に読み込まれる前にデータ探索を開始できるように設計されています。
ファイルの読み取り
cat 関数を使用して、$SOLR_HOME の **userfiles** ディレクトリにあるファイルを読み取ることができます。このディレクトリはユーザーが作成する必要があります。cat 関数は 2 つの引数を取ります。
最初の引数は、コンマ区切りのパスリストです。パスリストにディレクトリが含まれている場合、cat はディレクトリとサブディレクトリ内のすべてのファイルをクロールします。パスリストにファイルのみが含まれている場合、cat は特定のファイルのみを読み取ります。
2 番目の引数である maxLines は、cat が合計で読み取る行数を指定します。maxLines が指定されていない場合、cat はクロールする各ファイルからすべての行を読み取ります。
cat 関数は、クロールされたファイル内の各行(maxLines まで)を読み取り、各行に対して 2 つのフィールドを持つタプルを出力します。
-
line: 行内のテキスト。 -
file:$SOLR_HOMEの下にあるファイルの相対パス。
以下は、maxLines を 5 とした iris.csv ファイルに対する cat の例です。
cat("iris.csv", maxLines="5")この式が /stream ハンドラに送信されると、次のように応答します。
{
"result-set": {
"docs": [
{
"line": "sepal_length,sepal_width,petal_length,petal_width,species",
"file": "iris.csv"
},
{
"line": "5.1,3.5,1.4,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.9,3,1.4,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.7,3.2,1.3,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.6,3.1,1.5,0.2,setosa",
"file": "iris.csv"
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}CSV ファイルと TSV ファイルの解析
parseCSV 関数と parseTSV 関数は cat 関数をラップし、CSV(コンマ区切り値)と TSV(タブ区切り値)を解析します。これらの関数はどちらも、各ファイルの先頭に CSV または TSV ヘッダーレコードを想定しています。
parseCSV と parseTSV はどちらも、ヘッダー値を各行の対応する値にマッピングしたタプルを出力します。
parseCSV(cat("iris.csv", maxLines="5"))この式が /stream ハンドラに送信されると、次のように応答します。
{
"result-set": {
"docs": [
{
"sepal_width": "3.5",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "5.1",
"id": "iris.csv_2",
"petal_length": "1.4"
},
{
"sepal_width": "3",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.9",
"id": "iris.csv_3",
"petal_length": "1.4"
},
{
"sepal_width": "3.2",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.7",
"id": "iris.csv_4",
"petal_length": "1.3"
},
{
"sepal_width": "3.1",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.6",
"id": "iris.csv_5",
"petal_length": "1.5"
},
{
"EOF": true,
"RESPONSE_TIME": 1
}
]
}
}視覚化
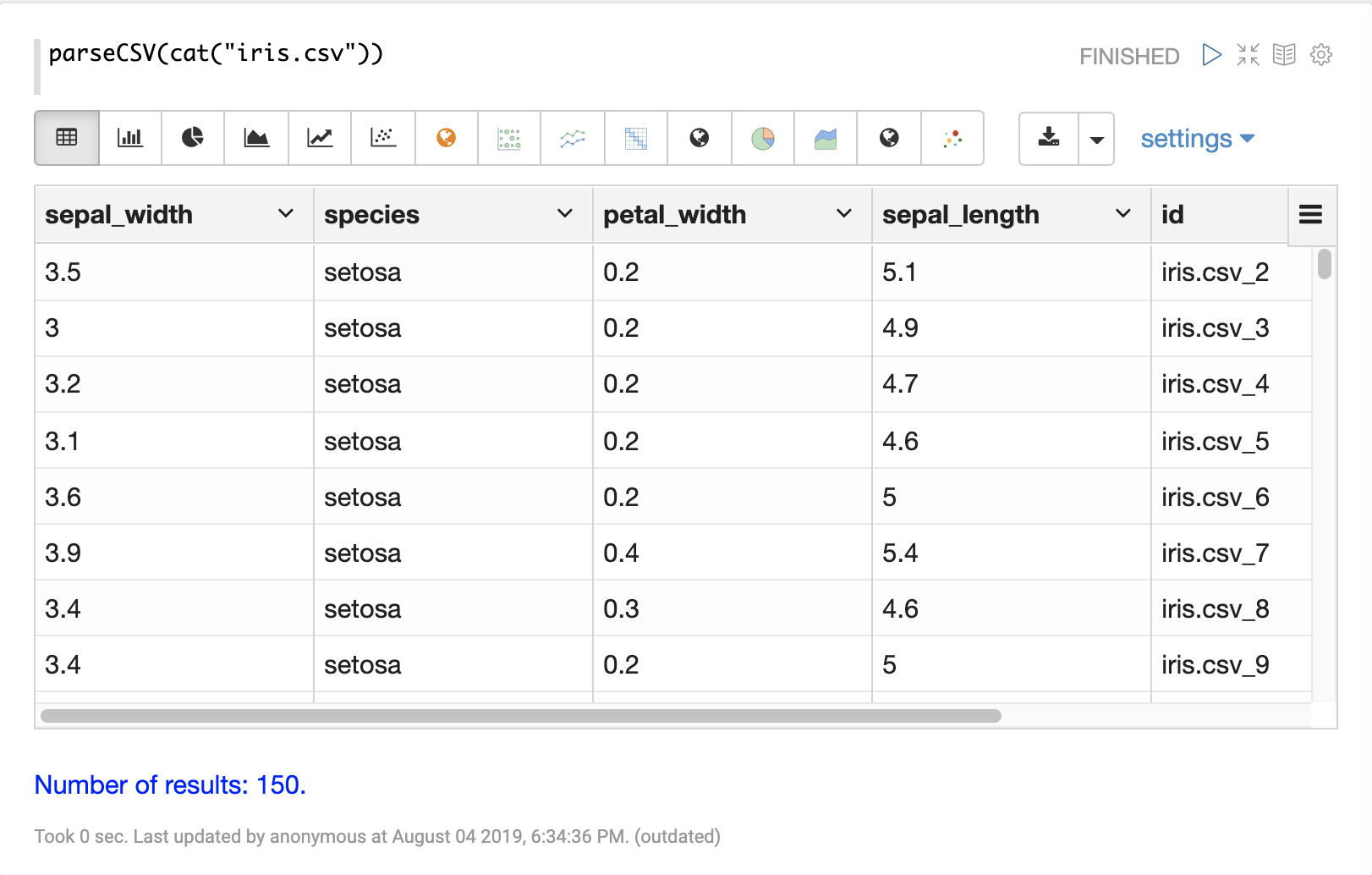
parseCSV または parseTSV でデータがタプルに解析されると、Zeppelin-Solr を使用して視覚化できます。
以下の例は、parseCSV 関数の出力をテーブルとして視覚化したものです。
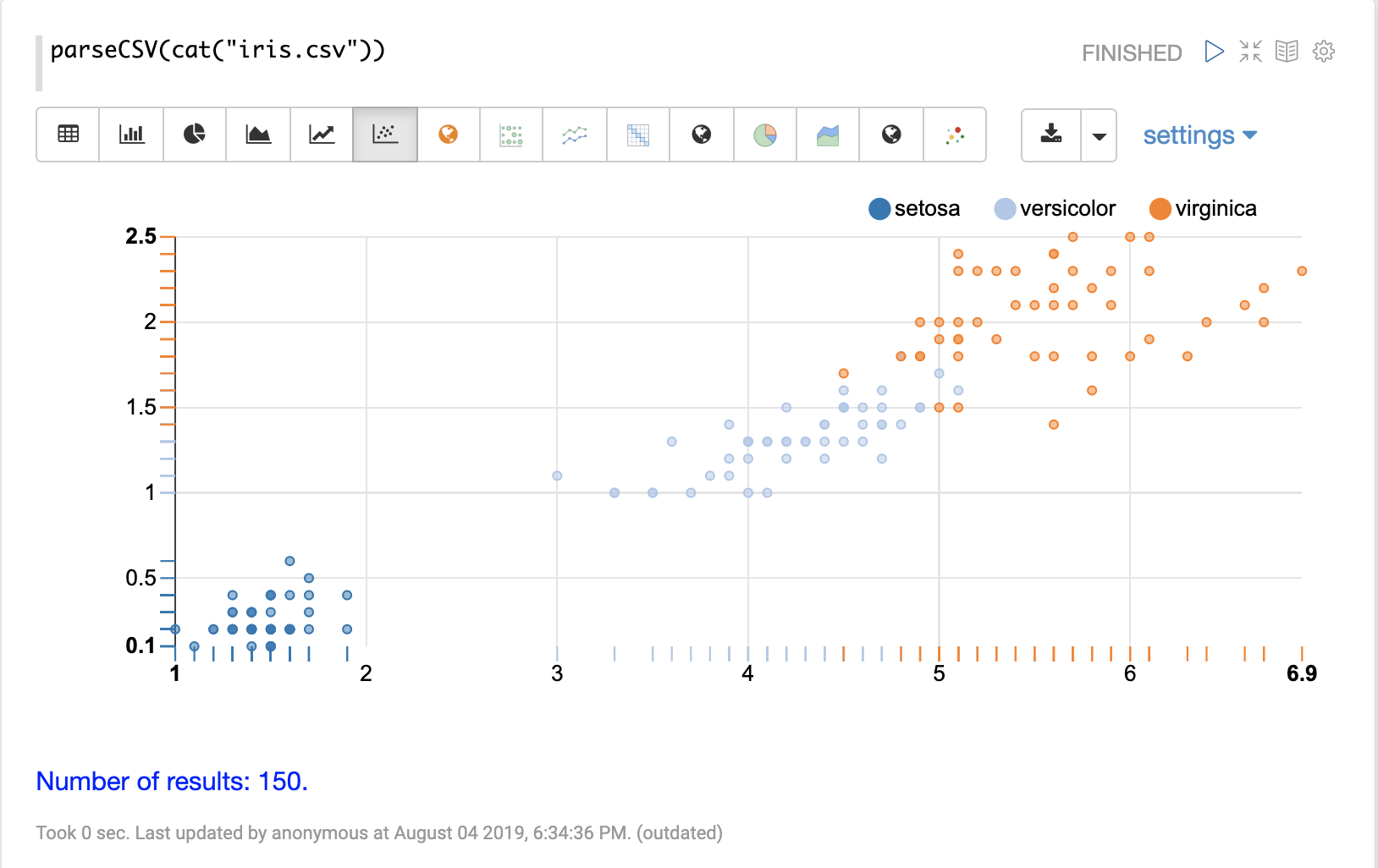
その後、テーブルの列を Apache Zeppelin の視覚化のいずれかを使用して視覚化できます。以下の例は、species ごとにグループ化された petal_length と petal_width の散布図を示しています。
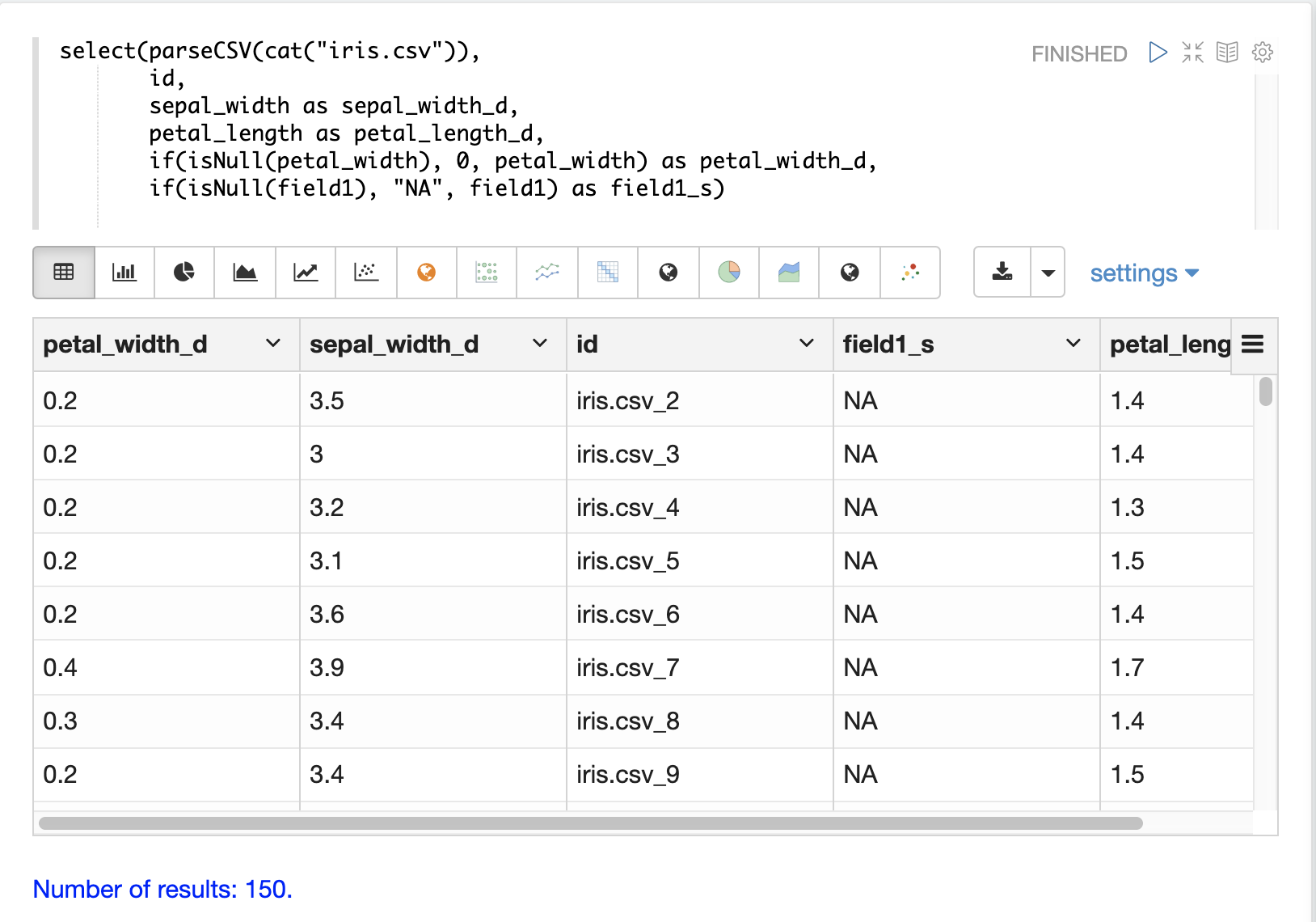
フィールドとフィールドタイプの選択
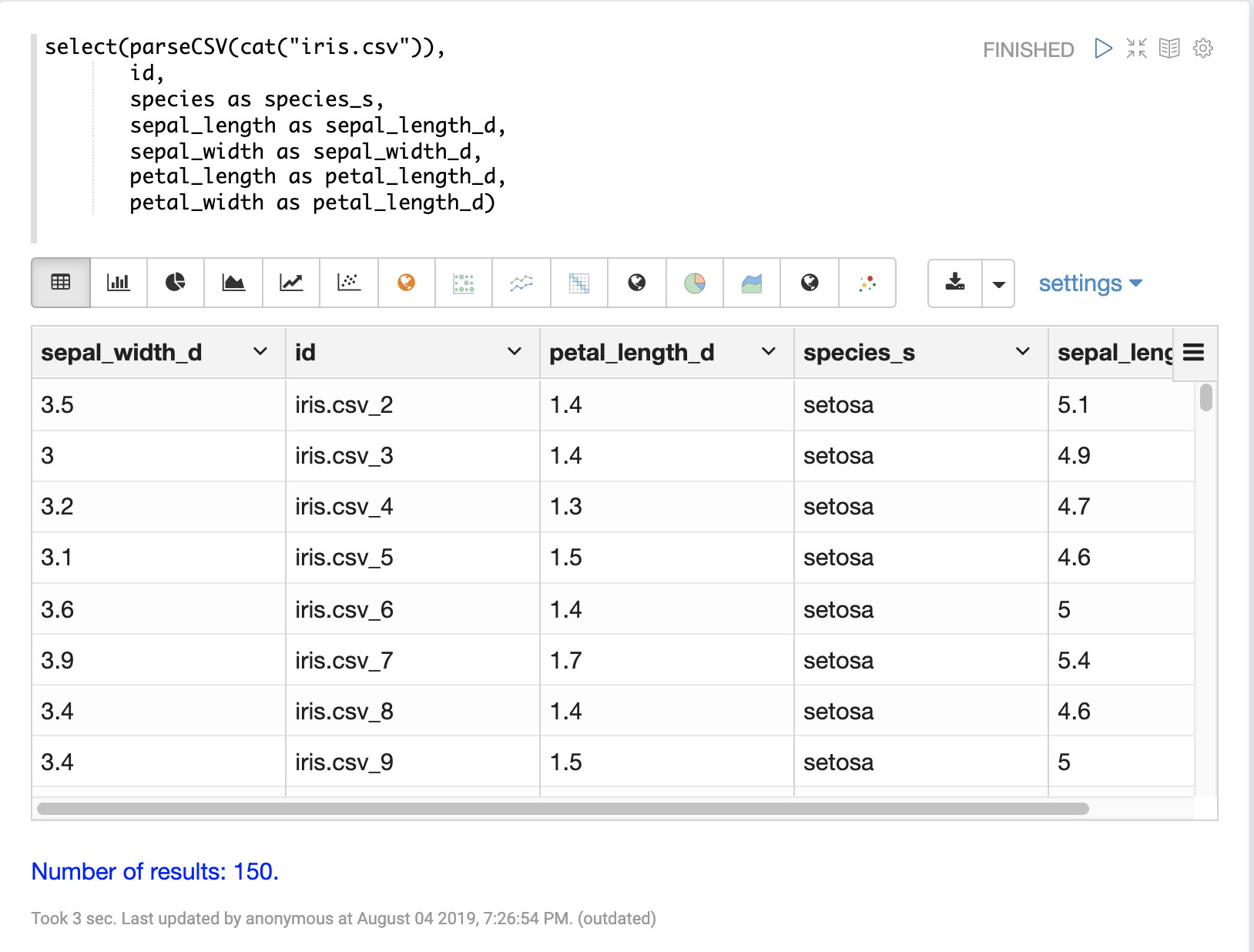
select 関数を使用して、CSV ファイルから特定のフィールドを選択し、インデックス作成のために新しいフィールド名にマッピングできます。
CSV ファイルのフィールドは、動的フィールドサフィックスを使用してフィールド名にマッピングできます。このアプローチにより、スキーマファイルを変更することなく、スキーマフィールドタイプを細かく制御できます。
以下は、フィールドを選択して特定のフィールドタイプにマッピングする例です。
データの読み込み
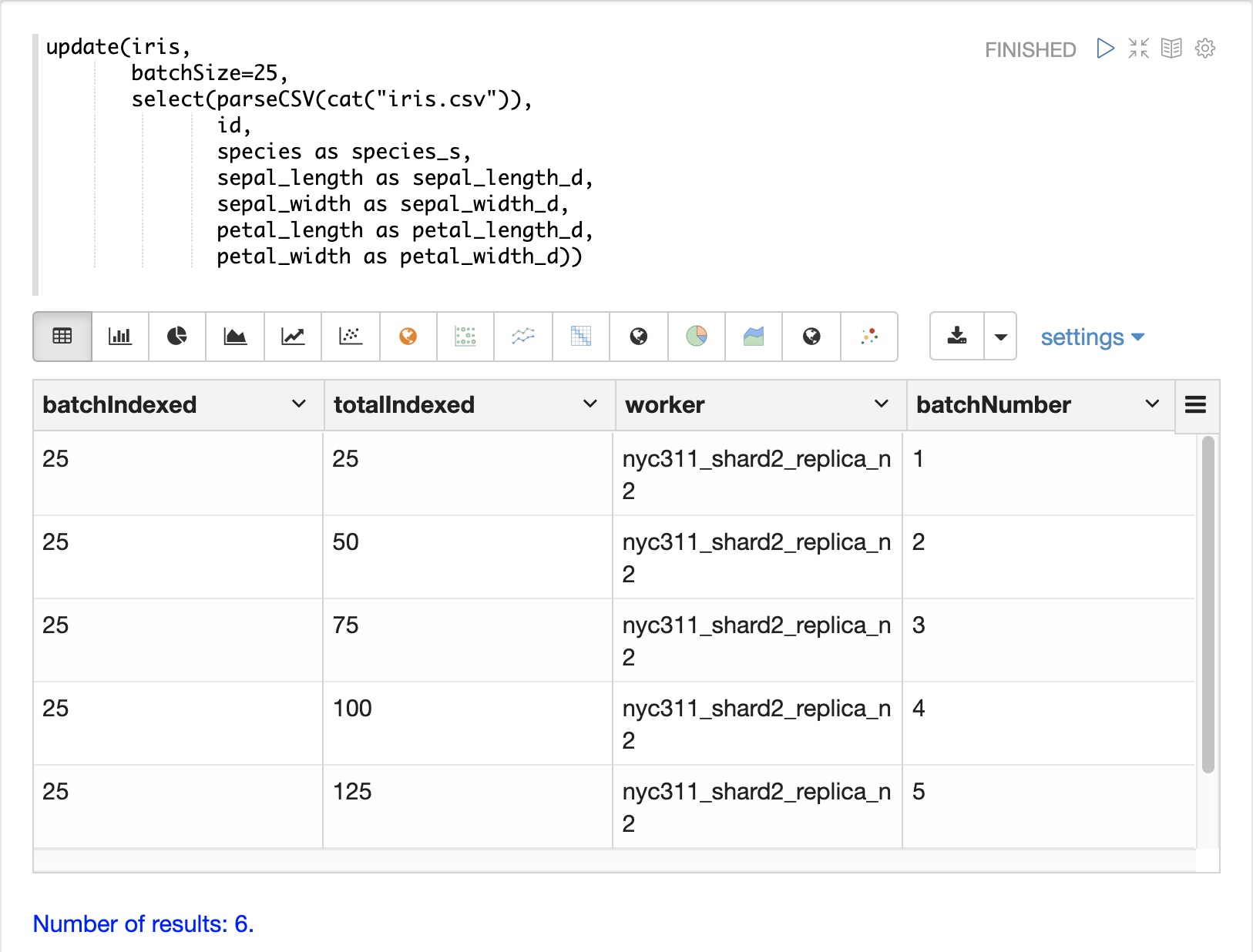
データのロード準備が整うと、update関数を用いてデータをSolrCloudコレクションに送信し、インデックスを作成できます。update関数はバッチ単位でSolrにドキュメントを追加し、各バッチの要約情報とロードに関するタプルを返します。
以下の例では、データセットが小さいため、Zeppelin-Solrを使用してupdate式を実行しています。大規模なロードの場合は、update関数の出力をディスクにスプールできるcurlコマンドからロードを実行することをお勧めします。
データの変換
ストリーミング式と算術式は、データを処理するための強力な関数セットを提供します。以下のセクションでは、CSVファイルとTSVファイルの分析、視覚化、ロード中に適用できるいくつかの有用な変換を示します。
一意ID
parseCSVとparseTSVの両方とも、データにidフィールドが存在しない場合、idフィールドを出力します。idフィールドは、ファイルパスと行番号の連結です。これは、ファイルにidが存在しない場合に、レコードが一貫したidを持つことを保証する便利な方法です。
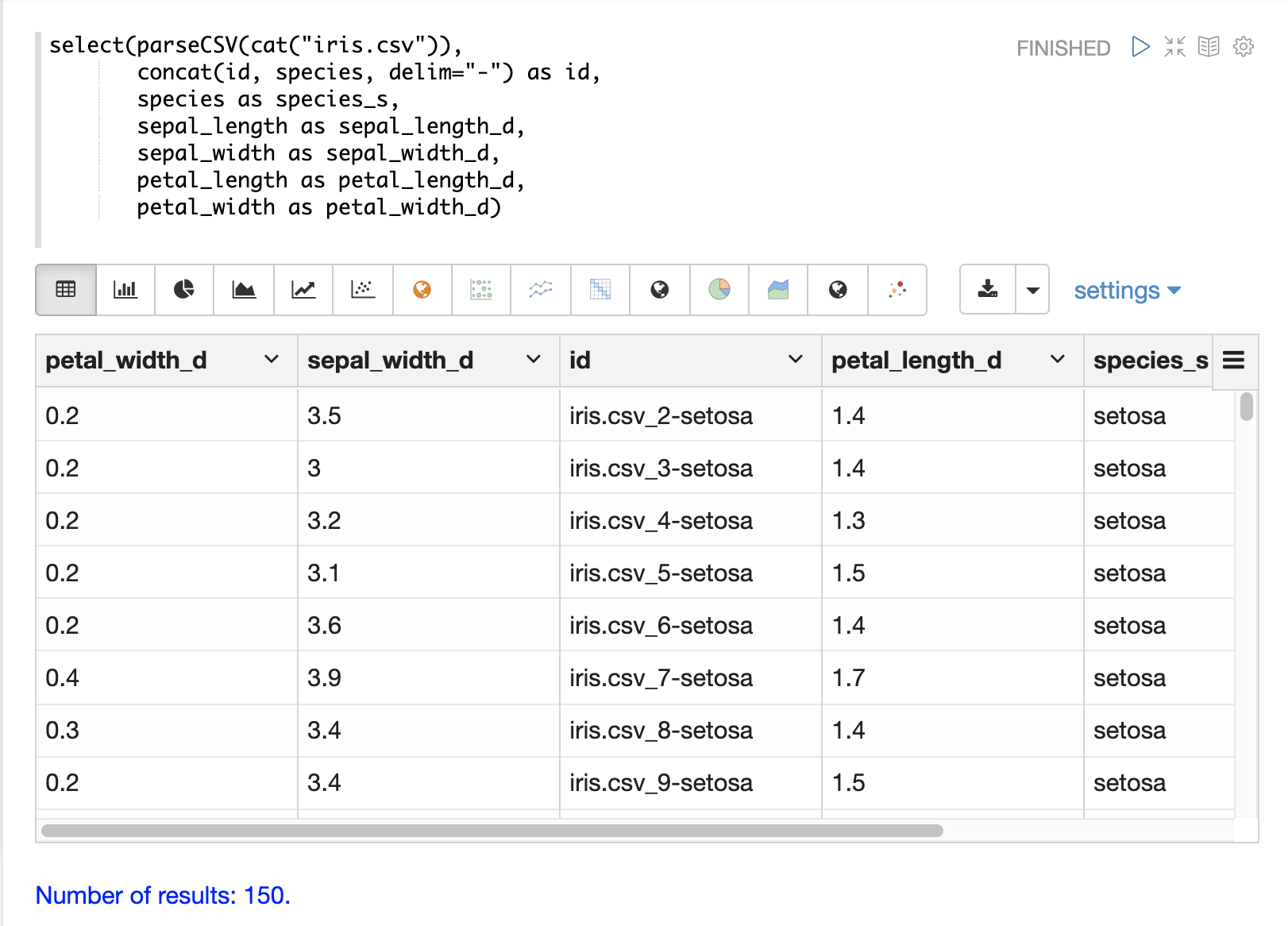
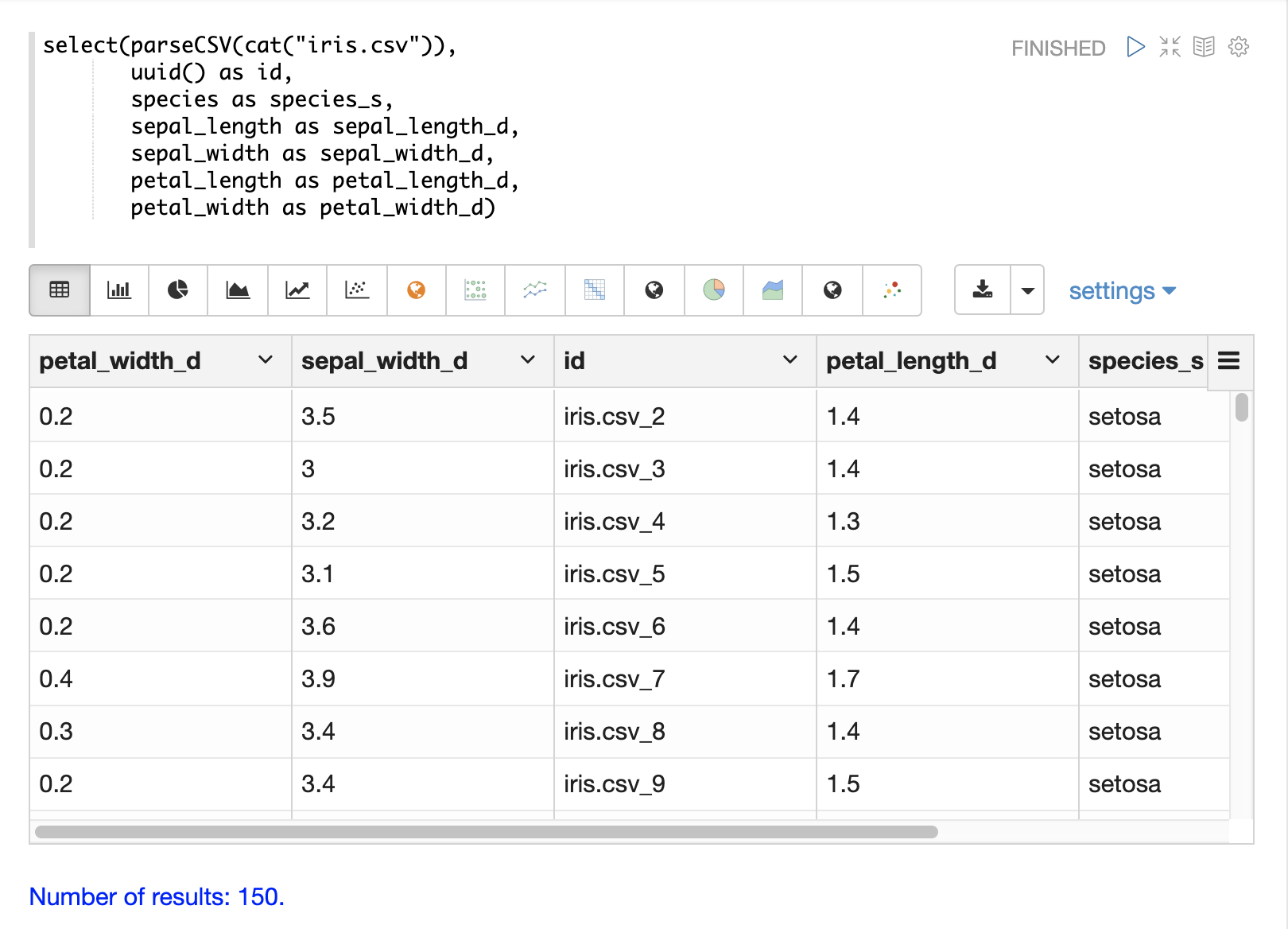
select関数を使用して、ファイル内の任意のフィールドをidフィールドにマッピングすることもできます。concat関数は、ファイル内の2つ以上のフィールドを連結してidを作成するために使用できます。または、uuid関数を用いてランダムな一意のidを作成することもできます。uuid関数が使用されている場合、uuid関数は後続のロードで各ドキュメントに対して同じidを生成しないため、データを削除せずに再ロードすることはできません。
以下は、concat関数を使用して新しいidを作成する例です。
以下は、uuid関数を使用して新しいidを作成する例です。
レコード番号
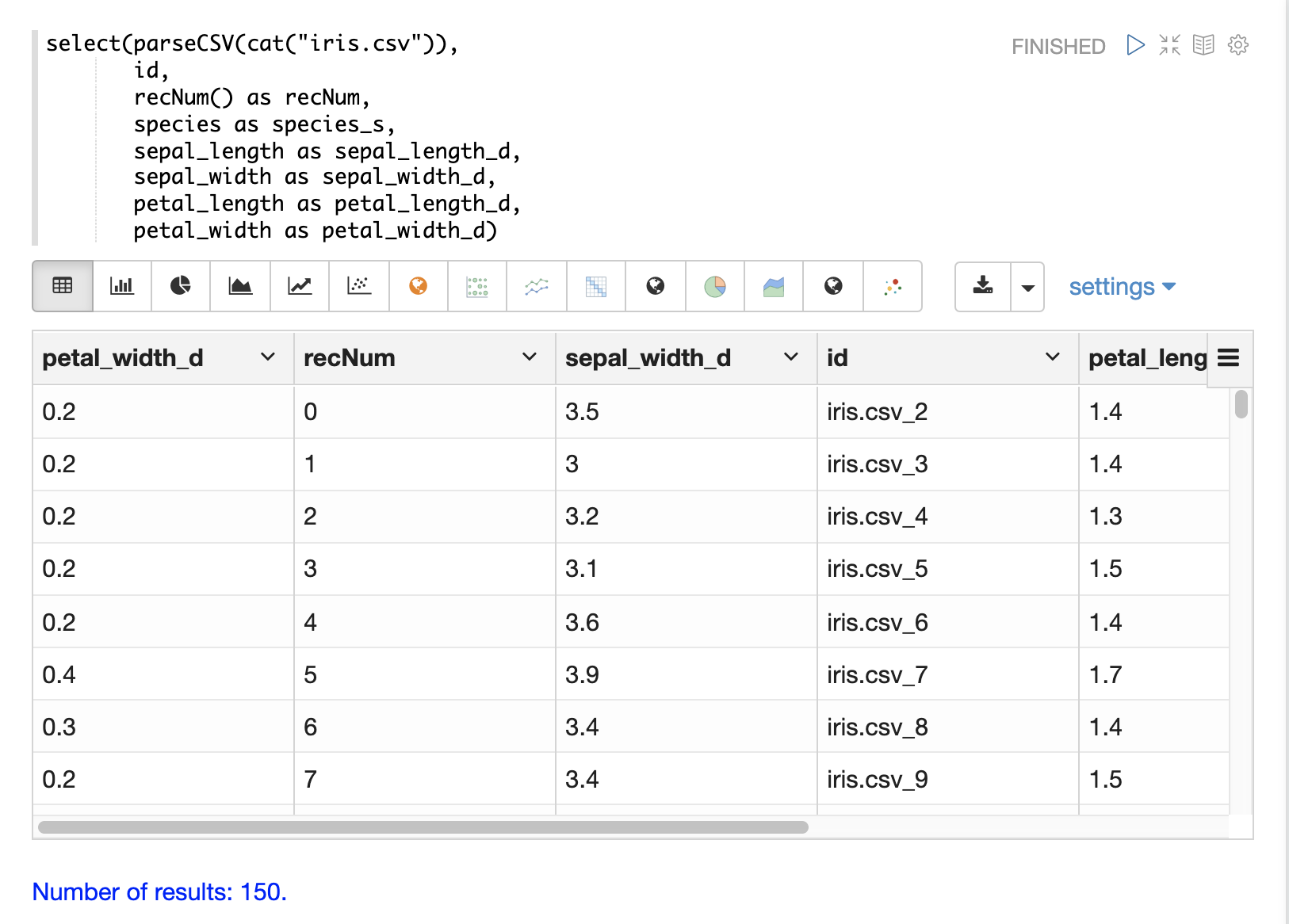
recNum関数はselect関数内で使用して、各タプルにレコード番号を追加できます。レコード番号は、結果セット内の場所を追跡するために役立ち、後述の結果のフィルタリングセクションで説明されているスキップ、ページング、ストライドなどのフィルタリング戦略に使用できます。
以下の例は、recNum関数の構文を示しています。
日付の解析
dateTime関数は、日付をSolrの日付フィールドにロードするために必要なISO-8601形式に解析するために使用できます。
まず、CSVファイルの日付時刻フィールドの形式を調べることができます。
select(parseCSV(cat("yr2017.csv", maxLines="2")),
id,
Created.Date)この式が /stream ハンドラに送信されると、次のように応答します。
{
"result-set": {
"docs": [
{
"id": "yr2017.csv_2",
"Created.Date": "01/01/2017 12:00:00 AM"
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}次に、dateTime関数を使用して日付時刻のフォーマットを行い、Solrの日付フィールドにマッピングできます。
dateTime関数は、3つのパラメーターを取ります。日付文字列を含むデータ内のフィールド、Java SimpleDateFormatテンプレートを使用して日付を解析するためのテンプレート、およびオプションのタイムゾーンです。
タイムゾーンが存在しない場合、タイムゾーンは、日付文字列自体に含まれていない限り、GMT時間にデフォルト設定されます。
以下は、上記の例の日付形式に適用されたdateTime関数の例です。
select(parseCSV(cat("yr2017.csv", maxLines="2")),
id,
dateTime(Created.Date, "MM/dd/yyyy hh:mm:ss a", "EST") as cdate_dt)この式が /stream ハンドラに送信されると、次のように応答します。
{
"result-set": {
"docs": [
{
"cdate_dt": "2017-01-01T05:00:00Z",
"id": "yr2017.csv_2"
},
{
"EOF": true,
"RESPONSE_TIME": 1
}
]
}
}文字列操作
upper、lower、split、valueAt、trim、concat関数は、select関数内で文字列を操作するために使用できます。
以下の例は、speciesフィールドを大文字にするために使用されるupper関数を示しています。
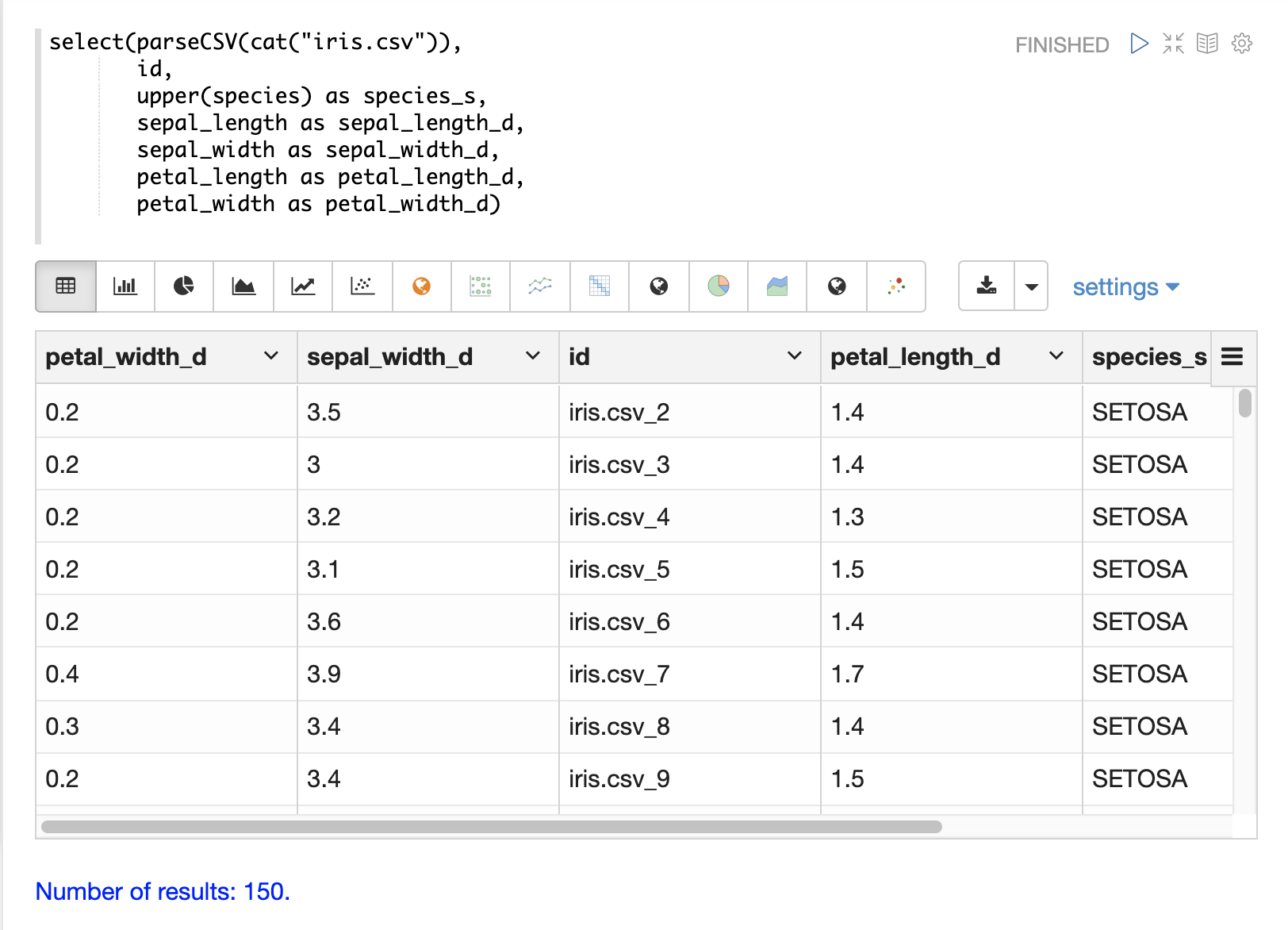
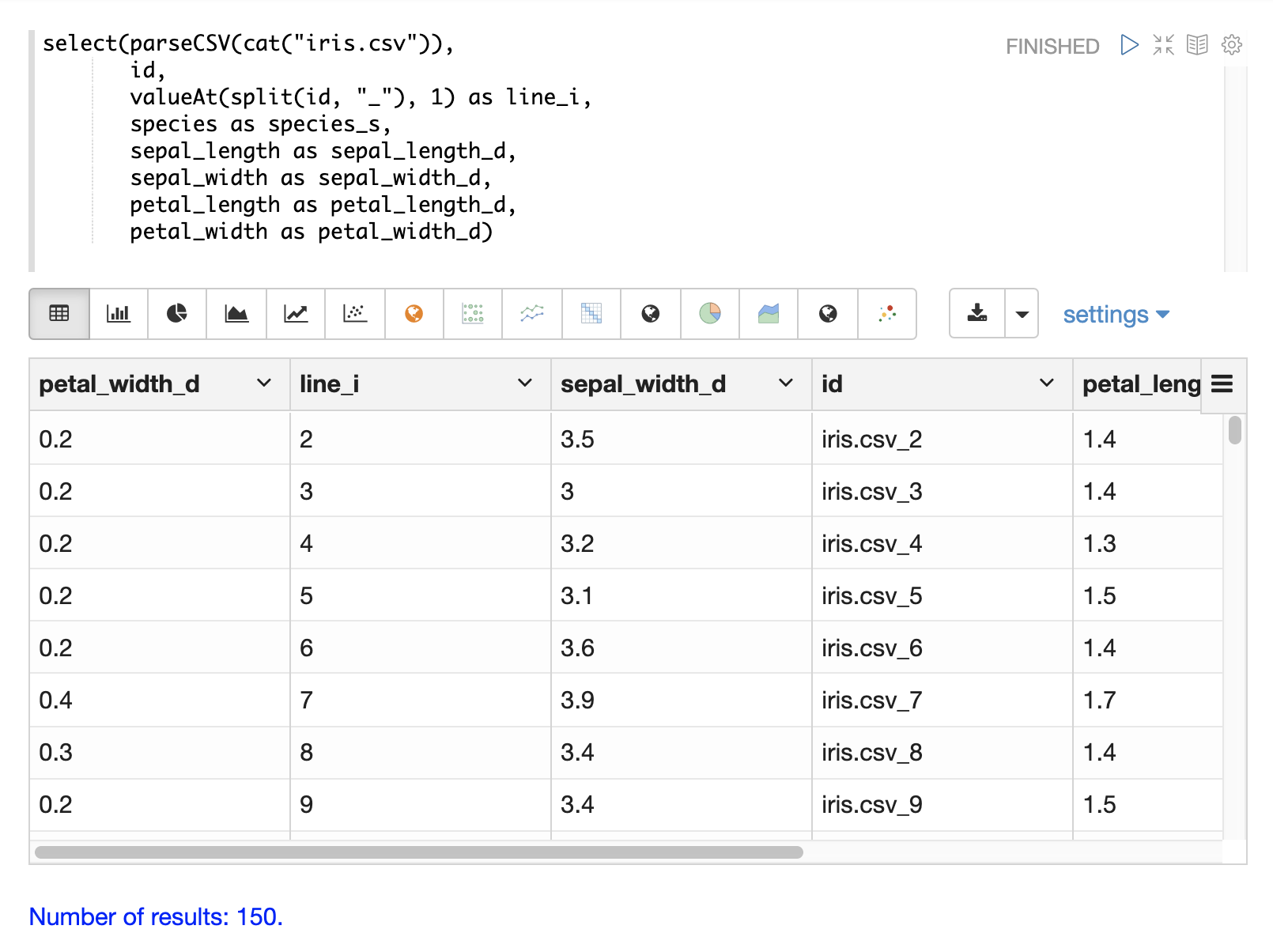
以下の例は、デリミタでフィールドを分割するsplit関数を示しています。これは、内部デリミタを持つフィールドから複数値フィールドを作成するために使用できます。
以下の例は、/streamハンドラへの直接呼び出しでこれを示しています。
select(parseCSV(cat("iris.csv")),
id,
split(id, "_") as parts_ss,
species as species_s,
sepal_length as sepal_length_d,
sepal_width as sepal_width_d,
petal_length as petal_length_d,
petal_width as petal_width_d)この式が /stream ハンドラに送信されると、次のように応答します。
{
"result-set": {
"docs": [
{
"petal_width_d": "0.2",
"sepal_width_d": "3.5",
"id": "iris.csv_2",
"petal_length_d": "1.4",
"species_s": "setosa",
"sepal_length_d": "5.1",
"parts_ss": [
"iris.csv",
"2"
]
},
{
"petal_width_d": "0.2",
"sepal_width_d": "3",
"id": "iris.csv_3",
"petal_length_d": "1.4",
"species_s": "setosa",
"sepal_length_d": "4.9",
"parts_ss": [
"iris.csv",
"3"
]
}]}}valueAt関数は、分割された配列から特定のインデックスを選択するために使用できます。
結果のフィルタリング
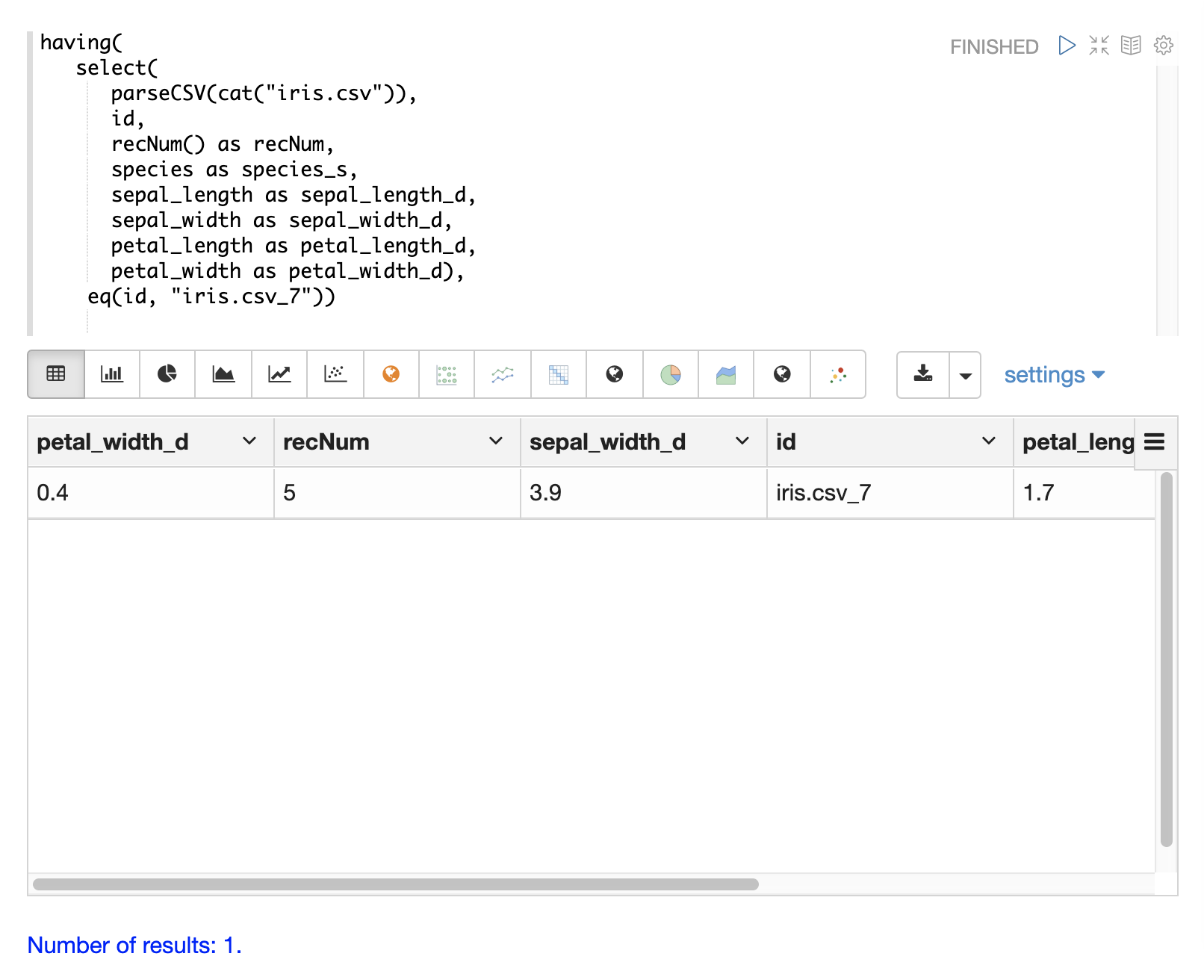
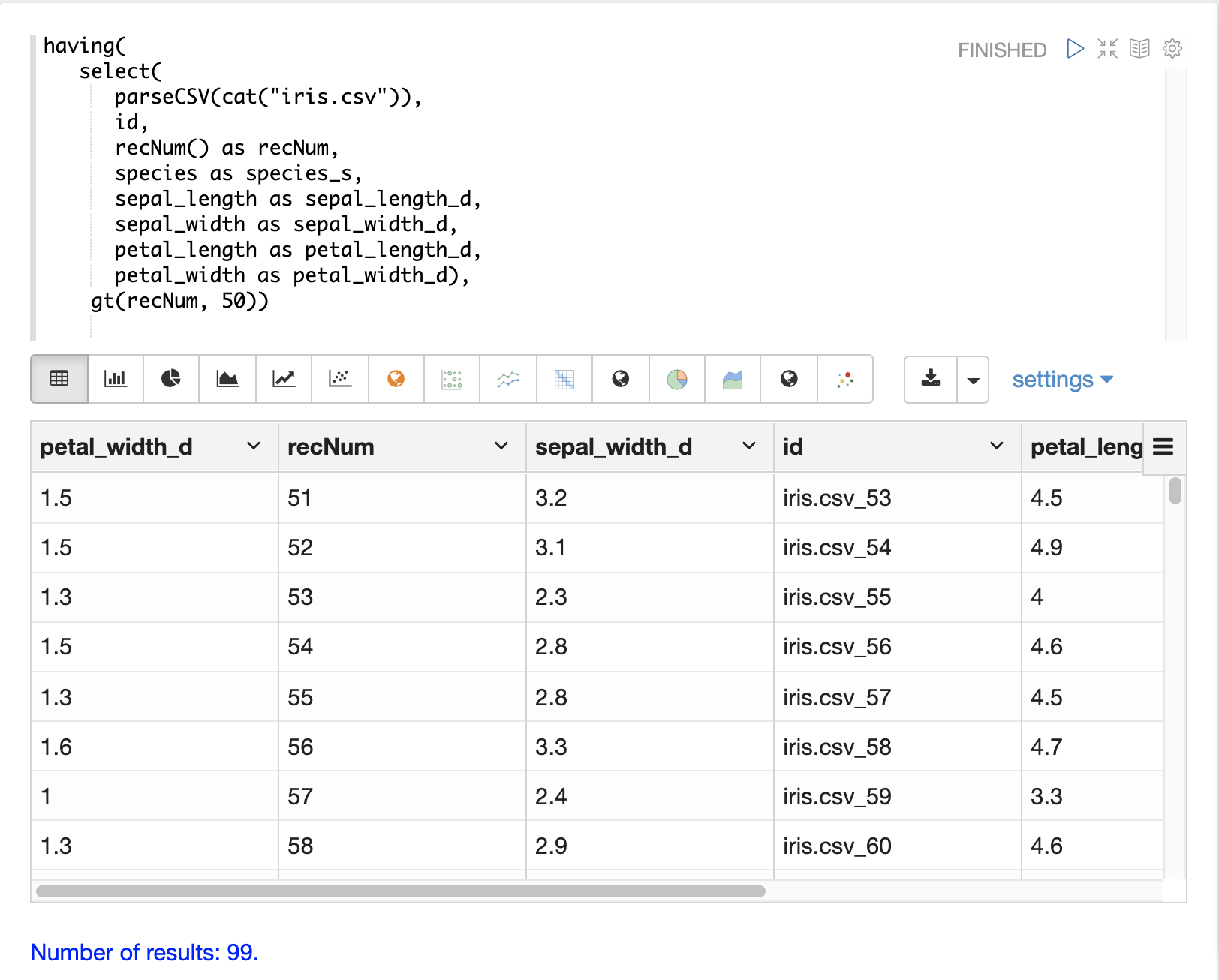
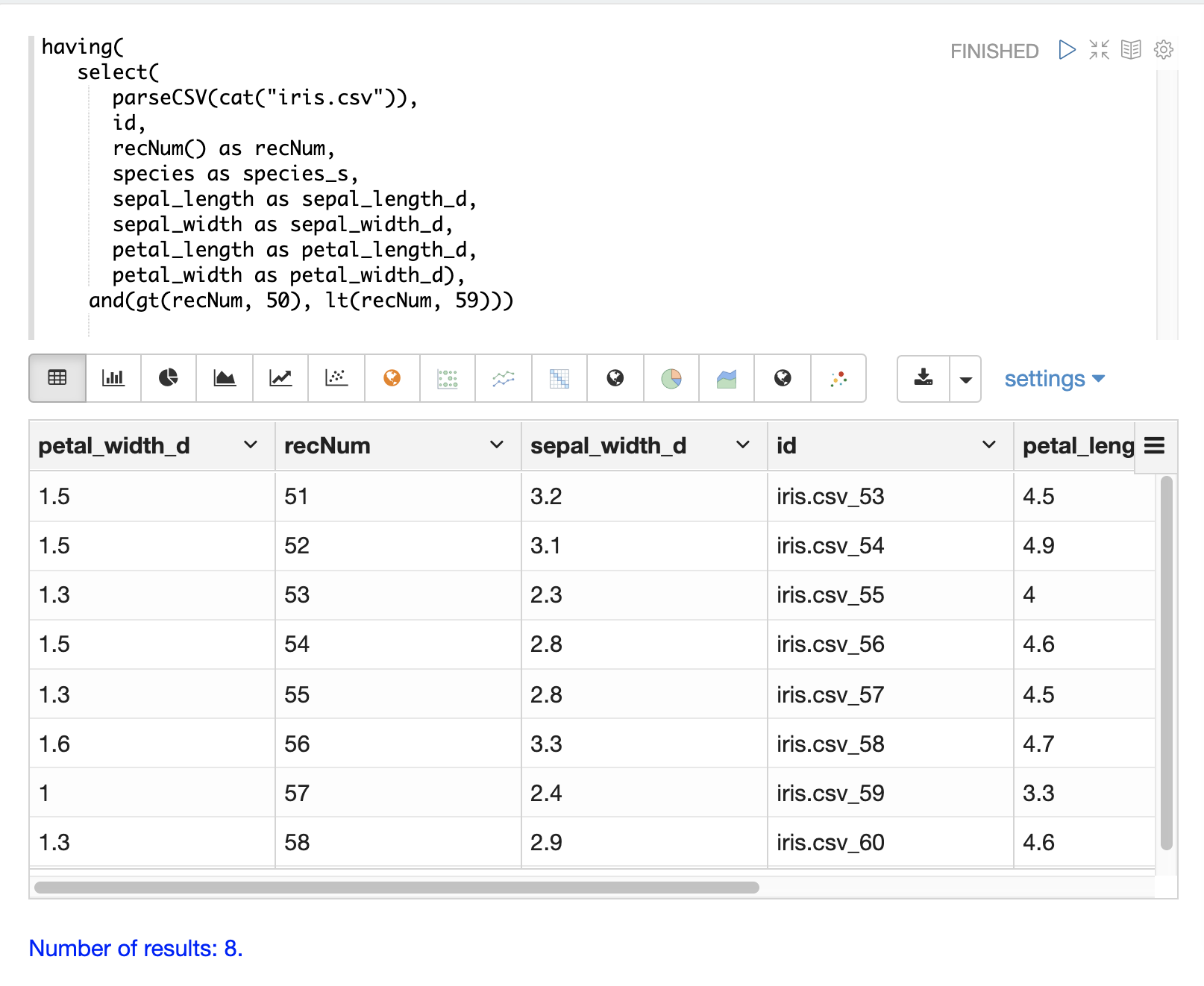
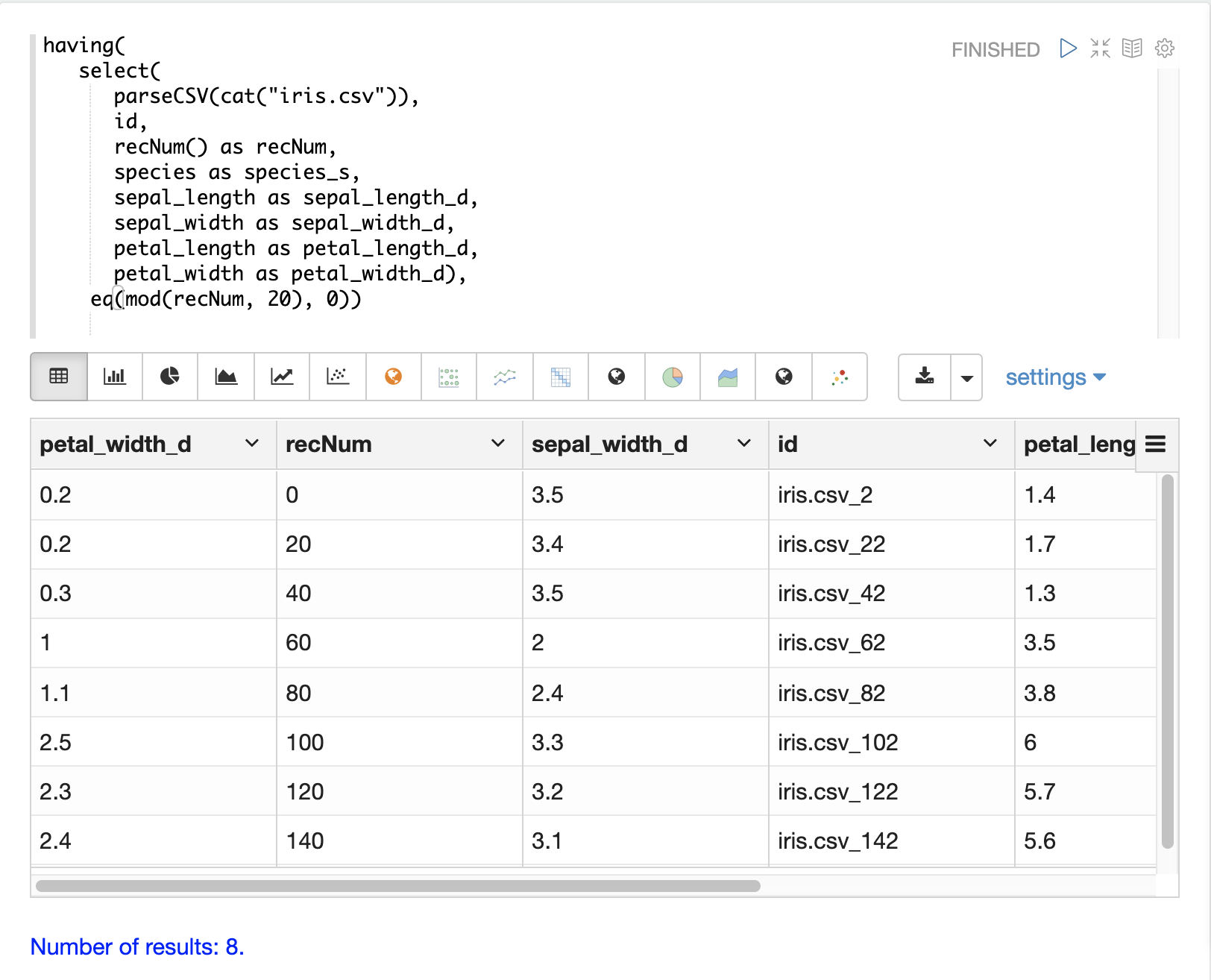
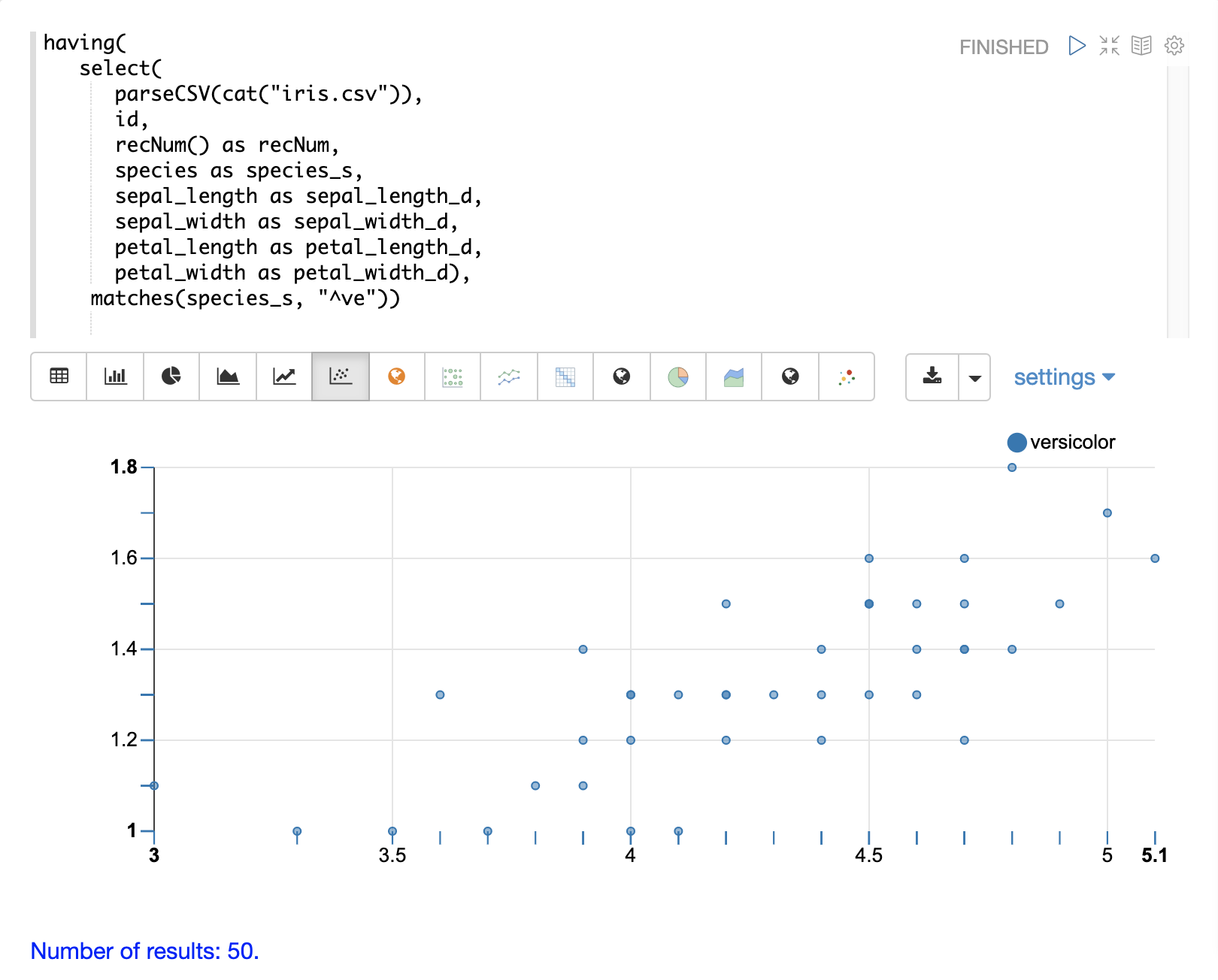
having関数は、レコードをフィルタリングするために使用できます。フィルタリングは、インデックス作成前に特定のレコードセットを体系的に調査したり、インデックス作成のために送信されるレコードをフィルタリングするために使用できます。having関数は別のストリームをラップし、各タプルにブール関数を適用します。ブール論理関数がtrueを返す場合、タプルが返されます。
次のブール関数がサポートされています:eq、gt、gteq、lt、lteq、matches、and、or、not、notNull、isNull。
以下は、having関数を使用してレコードをフィルタリングするためのいくつかの戦略です。
NULLの処理
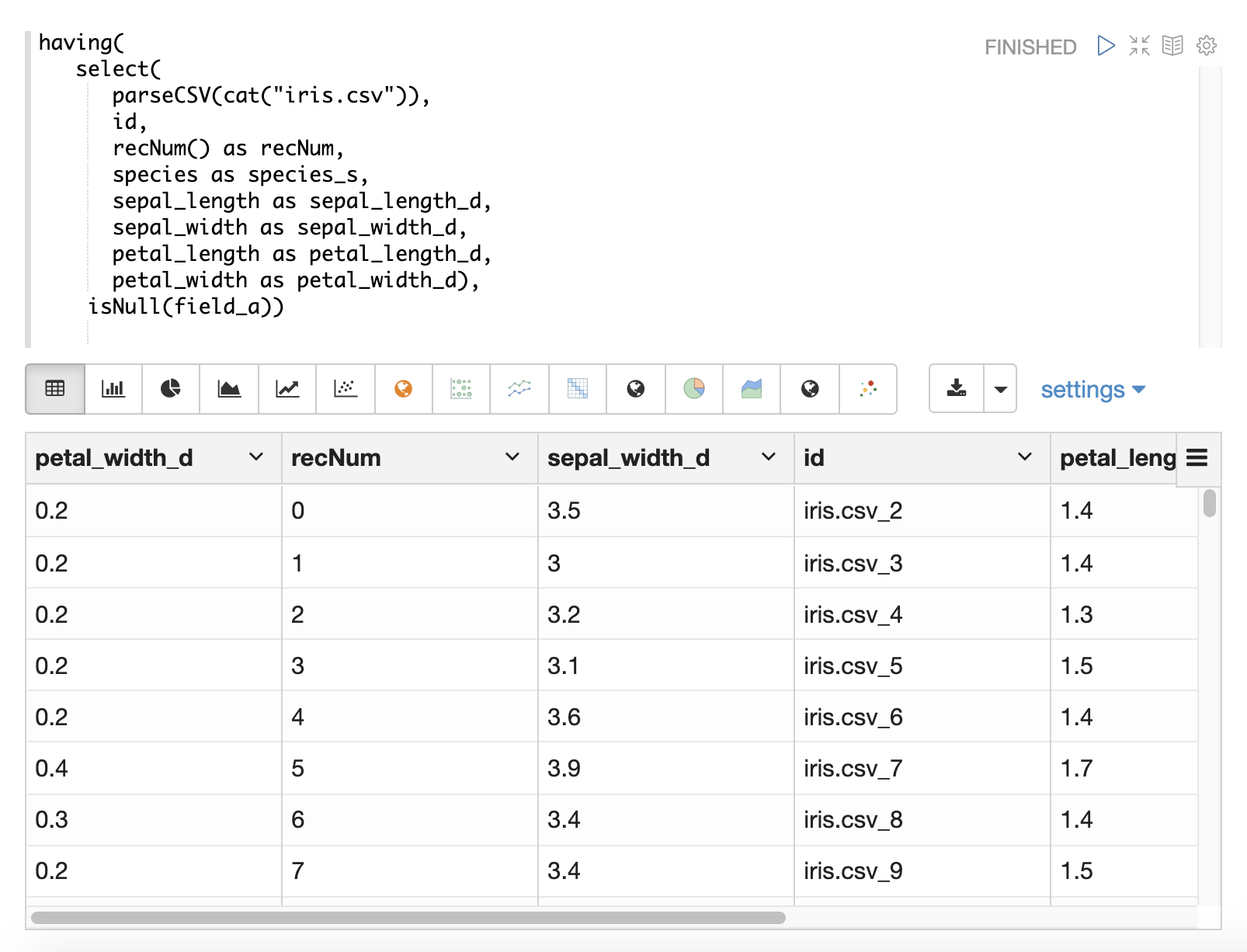
ほとんどの場合、ロード中にNULLを処理する必要がある特定のロジックがない限り、NULLを直接処理する必要はありません。
select関数は、NULL値を含むフィールドを出力しません。これは、データ内でNULLが検出されると、フィールドがタプルに含まれないことを意味します。
文字列操作関数はすべて、NULLが検出されるとNULLを返します。これは、NULLがselect関数に渡され、NULLを持つフィールドは単にレコードから省略されることを意味します。
特定のシナリオでは、NULLを直接フィルタリングまたは置換することが重要になる場合があります。以下のセクションでは、これらのシナリオについて説明します。

テキスト分析
analyze関数は、select関数内から使用して、使用可能なアナライザーでテキストフィールドを分析できます。analyzeの出力を分析されたトークンのリストとし、各タプルに複数値フィールドとして追加できます。
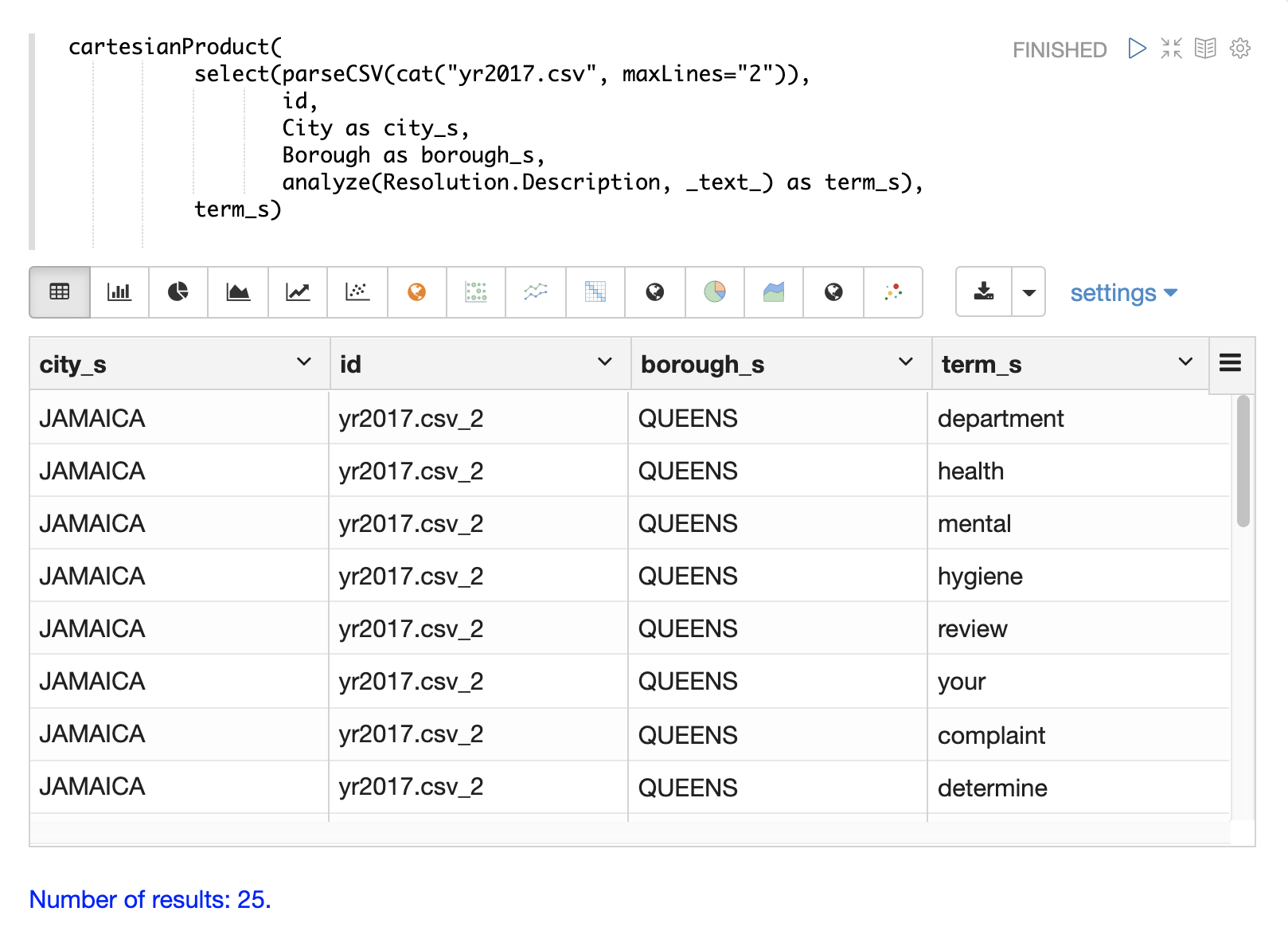
その後、複数値フィールドをSolrにインデックス作成のために送信するか、cartesianProduct関数を使用してトークンのリストをタプルのストリームに展開できます。
analyze関数には、いくつかの興味深いユースケースがあります。
-
インデックス作成前に、さまざまなアナライザーの出力をプレビューすること。
-
ドキュメントがインデックス作成パイプラインに到達する前に、NLPによって生成されたトークン(エンティティ抽出、名詞句など)でドキュメントに注釈を付けること。これにより、クエリも処理している可能性のあるサーバーからの負荷の高いNLP処理が削除されます。また、検索クラスタで使用できるよりも多くのコンピューティングリソースをNLPインデックスに適用できます。
-
cartesianProduct関数を使用すると、分析されたトークンは個々のドキュメントとしてインデックスされるため、Solrの集計式やグラフ式を使用して分析されたトークンを検索および分析できます。 -
また、
cartesianProductを使用して、インデックス作成の前に、分析されたトークンを集計、分析、および視覚化できます。
以下は、タプルのResolution.Descriptionフィールドに適用されたanalyze関数の例です。_text_フィールドアナライザーを使用してテキストを分析し、分析されたトークンはtoken_ssフィールドのドキュメントに追加されます。
select(parseCSV(cat("yr2017.csv", maxLines="2")),
Resolution.Description,
analyze(Resolution.Description, _text_) as tokens_ss)この式が /stream ハンドラに送信されると、次のように応答します。
{
"result-set": {
"docs": [
{
"Resolution.Description": "The Department of Health and Mental Hygiene will review your complaint to determine appropriate action. Complaints of this type usually result in an inspection. Please call 311 in 30 days from the date of your complaint for status",
"tokens_ss": [
"department",
"health",
"mental",
"hygiene",
"review",
"your",
"complaint",
"determine",
"appropriate",
"action",
"complaints",
"type",
"usually",
"result",
"inspection",
"please",
"call",
"311",
"30",
"days",
"from",
"date",
"your",
"complaint",
"status"
]
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}以下の例は、term_sフィールドの分析された用語をそれ自身のドキュメントに展開するcartesianProduct関数を示しています。ドキュメントの他のフィールドは各用語と共に保持されていることに注意してください。これにより、各用語を個別のドキュメントにインデックスできるため、用語と他のフィールド間の関係をグラフ式または集計を通じて調査できます。