演習 2: 映画データのインデックス作成
演習 2: スキーマの変更と映画データのインデックス作成
この演習では、前の演習を基に、インデックススキーマと Solr の強力なファセット機能を紹介します。
Solr の再起動
前回の演習の後、Solr を停止しましたか?いいえ?その場合は、次のセクションに進みます。
停止した場合は、Solr を再起動するために、次のコマンドを実行します。
$ bin/solr start -c -p 8983 -s example/cloud/node1/solrこれにより、最初のノードが起動します。完了したら、2 番目のノードを起動し、ZooKeeper への接続方法を指定します。
$ bin/solr start -c -p 7574 -s example/cloud/node2/solr -z localhost:9983solr.in.sh/solr.in.cmdでZK_HOSTを定義している場合(Solr インクルードファイルの更新を参照)、上記のコマンドから-z <zk host string>を省略できます。 |
新規コレクションの作成
この演習ではまったく新しいデータセットを使用するため、以前のものを使用する代わりに、新しいコレクションを作成する方が良いでしょう。
その理由の1つは、Solr の「フィールド推測」機能を使用するためです。この機能では、Solr はインデックス作成中にフィールド内のデータの種類を推測しようとします。また、受信ドキュメントに表示される新しいフィールドのスキーマに新しいフィールドを自動的に作成します。このモードは「スキーマレス」と呼ばれます。このアプローチのメリットとデメリットを確認して、実際のアプリケーションでどのように使用するかを決定するのに役立てましょう。
最初の演習でSolrを最初に起動したとき、使用するconfigsetを選択できました。私たちが選択したconfigsetには、後でインデックスを作成したデータに対して事前に定義されたスキーマがありました。今回は、非常に最小限のスキーマを持つconfigsetを使用し、Solrがデータから追加するフィールドを判断させます。
インデックスを作成するデータは映画に関するものなので、_default configsetを使用する「films」というコレクションを作成することから始めます。
$ bin/solr create -c films -s 2 -rf 2ちょっと待ってください。configsetを指定していません!大丈夫です。_default はデフォルトなので、何も指定しないとこれが使用されます。
ただし、-s と -rf の2つのパラメータを設定しました。これらは、コレクションを分割するシャード数(2)と、作成するレプリカ数(2)です。これは、最初の演習のインタラクティブな例で使用したオプションと同じです。
次のような出力が表示されます。
WARNING: Using _default configset. Data driven schema functionality is enabled by default, which is
NOT RECOMMENDED for production use.
To turn it off:
bin/solr config -c films -p 7574 -action set-user-property -property update.autoCreateFields -value false
Connecting to ZooKeeper at localhost:9983 ...
INFO - 2017-07-27 15:07:46.191; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 ready
Uploading /{solr-full-version}/server/solr/configsets/_default/conf for config films to ZooKeeper at localhost:9983
Creating new collection 'films' using command:
https://:7574/solr/admin/collections?action=CREATE&name=films&numShards=2&replicationFactor=2&collection.configName=films
{
"responseHeader":{
"status":0,
"QTime":3830},
"success":{
"192.168.0.110:8983_solr":{
"responseHeader":{
"status":0,
"QTime":2076},
"core":"films_shard2_replica_n1"},
"192.168.0.110:7574_solr":{
"responseHeader":{
"status":0,
"QTime":2494},
"core":"films_shard1_replica_n2"}}}コマンドが最初に表示したのは、本番環境でこのconfigsetを使用しないという警告です。これは、すぐに説明するいくつかの制限によるものです。
それ以外では、コレクションが作成されているはずです。 https://:8983/solr/#/films/collection-overview の管理UIにアクセスすると、概要画面が表示されます。
映画データのスキーマレスの準備
_default configsetに付属するスキーマでは、2つのことが並行して発生しています。
まず、「マネージドスキーマ」を使用しています。これは、SolrのスキーマAPIによってのみ変更されるように構成されています。つまり、どの編集がどのソースから来たのかが混乱しないように、手動で編集すべきではありません。SolrのスキーマAPIを使用すると、フィールド、フィールドタイプ、その他のタイプのスキーマルールを変更できます。
次に、「フィールド推測」を使用しています。これはsolrconfig.xmlファイル(Solrの様々な構成設定の大部分を備えています)で構成されています。フィールド推測は、ドキュメントをインデックスしようとする前に、ドキュメントに含まれると思われるすべてのフィールドを定義しなくてもSolrを使用できるように設計されています。そのため、「スキーマレス」と呼んでいます。迅速に開始し、Solrがドキュメント内で遭遇したときにフィールドを作成させることができるからです。
素晴らしいですね!まあ、実際にはそうでもありません。制限があります。少々乱暴な方法であり、推測が間違っていた場合、データがインデックスされた後では、フィールドについて変更できることはほとんどありません。再インデックスが必要になります。数千件のドキュメントしかない場合は問題ないかもしれませんが、数百万件ものドキュメントがある場合、あるいは最悪、元のデータにアクセスできなくなった場合は、大きな問題になる可能性があります。
これらの理由から、Solrコミュニティでは、自分で定義したスキーマなしで本番環境に移行することを推奨していません。これは、スキーマレス機能は開始時には問題ありませんが、スキーマがデータのインデックス作成方法とユーザーによるクエリ方法に関する期待に常に合致するようにする必要があることを意味します。
スキーマレス機能と定義済みのスキーマを混在させることができます。スキーマAPIを使用すると、制御したいフィールドをいくつか定義し、重要でないフィールドや、満足のいくように推測されると確信している(テスト済み)フィールドをSolrが推測させることができます。ここでは、そうします。
"names"フィールドの作成
インデックスを作成する映画データには、映画ごとにID、監督名、映画名、公開日、ジャンルなどの少数のフィールドがあります。
example/filmsのファイルの1つを見ると、最初の映画は.45という名前で、2006年に公開されています。データセットの最初のドキュメントとして、Solrはレコード内のデータに基づいてフィールドタイプを推測します。このデータをインデックス付けすると、最初の映画名はSolrに対してフィールドタイプが「float」数値フィールドであることを示し、「name」フィールドをタイプFloatPointFieldで作成します。このレコード以降のすべてのデータはfloatであることが期待されます。
さて、これはうまくいきません。A Mighty WindやChicken Runなど、文字列であるタイトルがあります。数値でもfloatでもありません。Solrが「name」フィールドをfloatと推測させると、後のタイトルでエラーが発生し、インデックス作成が失敗します。これはあまり役に立ちません。
Solrが常に文字列として解釈するように、データをインデックスする前にSolrで「name」フィールドを設定できます。コマンドラインで、次のcurlコマンドを入力します。
$ curl -X POST -H 'Content-type:application/json' --data-binary '{"add-field": {"name":"name", "type":"text_general", "multiValued":false, "stored":true}}' https://:8983/solr/films/schemaこのコマンドは、スキーマAPIを使用して、「name」という名前でフィールドタイプが「text_general」(テキストフィールド)のフィールドを明示的に定義します。複数の値を持つことは許可されませんが、保存されます(クエリで取得できます)。
管理UIを使用してフィールドを作成することもできますが、フィールドのプロパティに対する制御は少し少なくなります。ただし、私たちのケースでは機能します。
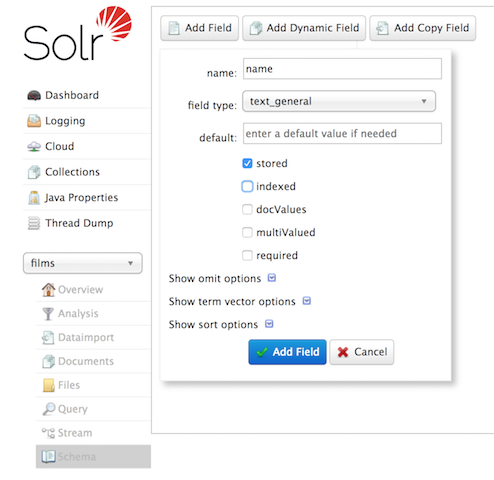
"catchall"コピーフィールドの作成
インデックス作成を開始する前に、もう1つ変更を加える必要があります。
最初の演習でインデックスを作成したドキュメントをクエリしたとき、フィールドを指定する必要はありませんでした。使用した構成は、フィールドをtextフィールドにコピーするように設定されており、他のフィールドがクエリで定義されていない場合、そのフィールドがデフォルトになっていました。
現在使用している構成にはそのルールがありません。すべてのクエリに対して検索するフィールドを定義する必要があります。ただし、すべてのフィールドからすべてのデータを取得し、_text_という名前のフィールドにインデックスするコピーフィールドを定義することで、「catchallフィールド」を設定できます。今すぐそれを行いましょう。
管理UIまたはスキーマAPIのいずれかを使用できます。
コマンドラインで、スキーマAPIを使用してコピーフィールドを定義します。
$ curl -X POST -H 'Content-type:application/json' --data-binary '{"add-copy-field" : {"source":"*","dest":"_text_"}}' https://:8983/solr/films/schema管理UIで、コピーフィールドの追加を選択し、このスクリーンショットのようにフィールドのソースと宛先を入力します。
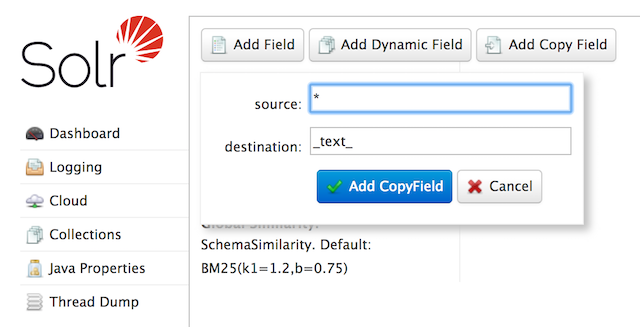
これにより、すべてのフィールドのコピーが作成され、データが"_text_"フィールドに格納されます。
| 本番データでこれを行うことは非常に高価になる可能性があります。これは、Solrが事実上すべてのものを2回インデックス付けするように指示するためです。インデックス作成が遅くなり、インデックスが大きくなります。本番データを使用する場合は、アプリケーションにとって本当に必要なフィールドのみをコピーするようにしてください。 |
さて、データをインデックスして操作を開始する準備ができました。
サンプル映画データのインデックス作成
インデックスを作成する映画データは、インストールのexample/filmsディレクトリにあります。JSON、XML、CSVの3つの形式があります。形式のいずれかを選択し、「films」コレクションにインデックスを作成します(各例で、1つのコマンドはUnix/MacOS用、もう1つはWindows用です)。
Linux/Mac
$ bin/solr post -c films example/films/films.jsonWindows
$ bin/solr post -c films example\films\films.jsonLinux/Mac
$ bin/solr post -c films example/films/films.xmlWindows
$ java -jar -Dc=films -Dauto example\exampledocs\post.jar example\films\*.xmlLinux/Mac
$ bin/solr post -c films example/films/films.csv -params "f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=|"Windows
$ java -jar -Dc=films -Dparams=f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=| -Dauto example\exampledocs\post.jar example\films\*.csv各コマンドには、次の主要パラメータが含まれています。
-
-c films:データのインデックスを作成するSolrコレクションです。 -
example/films/films.json(またはfilms.xmlまたはfilms.csv):インデックスを作成するデータファイルへのパスです。このファイルが存在するディレクトリを指定するだけで済みますが、インデックスを作成する形式がわかっているので、その形式の正確なファイルを指定する方が効率的です。
CSVコマンドには追加のパラメータが含まれていることに注意してください。これは、「genre」と「directed_by」列の複数値エントリをパイプ(|)文字で分割するために必要です。このファイルでは区切り文字として使用されています。Solrにこれらの列をこのように分割するように指示することで、データの適切なインデックス作成が保証されます。
各コマンドは、JSONのインデックス作成中に表示されるものと同様の出力を生成します。
$ bin/solr post -c films example/films/films.json
Posting files to [base] url https://:8983/solr/films/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file films.json (application/json) to [base]/json/docs
1 files indexed.
COMMITting Solr index changes to https://:8983/solr/films/update...
Time spent: 0:00:00.878やったー!
filmsの管理UIのクエリ画面(https://:8983/solr/#/films/query)にアクセスしてクエリの実行をクリックすると、1100件の結果が表示され、最初の10件が画面に表示されます。
「catchall」フィールドが正しく機能しているかどうかを確認するためにクエリを実行してみましょう。qボックスに「comedy」と入力し、クエリの実行をもう一度クリックします。417件の結果が表示されるはずです。ファセットに移る前に、他の検索を試してみてください。
ファセッティング
Solrで最も人気のある機能の1つはファセッティングです。ファセッティングにより、検索結果をサブセット(またはバケット、カテゴリ)に整理し、各サブセットのカウントを提供できます。ファセッティングには、フィールド値、数値および日付範囲、ピボット(決定ツリー)、任意のクエリファセッティングなど、いくつかの種類があります。
フィールドファセット
Solrクエリは、検索結果を提供することに加えて、結果セット全体で一意の値を含むドキュメントの数を返すことができます。
管理UIのクエリタブで、facetチェックボックスをオンにすると、いくつかのファセット関連のオプションが表示されます。

すべてのドキュメントからのファセットカウントを表示するには(q=*:*):ファセッティングをオンにし(facet=true)、facet.fieldパラメータを使用してファセット対象のフィールドを指定します。ファセットのみが必要で、ドキュメントの内容は不要な場合は、rows=0を指定します。次のcurlコマンドは、genre_strフィールドのファセットカウントを返します。
$ curl "https://:8983/solr/films/select?q=\*:*&rows=0&facet=true&facet.field=genre_str"`ターミナルには、次のようなものが表示されます。
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":11,
"params":{
"q":"*:*",
"facet.field":"genre_str",
"rows":"0",
"facet":"true"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"genre_str":[
"Drama",552,
"Comedy",389,
"Romance Film",270,
"Thriller",259,
"Action Film",196,
"Crime Fiction",170,
"World cinema",167]},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{}}}ここでは出力を少し切り詰めましたが、facet_countsセクションには、デフォルトではインデックス内のすべてのジャンルについて、各ジャンルを使用しているドキュメントの数が表示されます。Solrには、特定の数のドキュメントを含むファセットのみに制限するために使用できるfacet.mincountパラメータがあります(このパラメータはUIには表示されません)。あるいは、すべてのファセットが必要で、アプリケーションのフロントエンドでユーザーへの表示方法を制御する場合もあります。
バケット内のアイテム数を制御したい場合は、次のようにします。
$ curl "https://:8983/solr/films/select?=&q=\*:*&facet.field=genre_str&facet.mincount=200&facet=on&rows=0"4つのファセットのみが表示されます。
Solrがファセットとファセットリストを作成する方法を制御するのに役立つ、他にも多くのパラメータがあります。この演習ではいくつか説明しますが、ファセッティングセクションで詳細を確認することもできます。
範囲ファセット
数値や日付の場合、ファセットカウントを個別の値ではなく範囲に分割するのが望ましいことがよくあります。前の演習の例として使用したtechproductsデータを使用した数値範囲ファセッティングの代表的な例はpriceです。映画データには映画の公開日が含まれており、これを使用して日付範囲ファセットを作成できます。これは範囲ファセットの別の一般的な用途です。
Solr管理UIはまだ範囲ファセットオプションをサポートしていないため、次の例ではcurlまたは同様のコマンドラインツールを使用する必要があります。
次のようなクエリを作成した場合
$ curl "https://:8983/solr/films/select?q=*:*&rows=0\
&facet=true\
&facet.range=initial_release_date\
&facet.range.start=NOW/YEAR-25YEAR\
&facet.range.end=NOW\
&facet.range.gap=%2B1YEAR"これにより、すべての映画が要求され、25年前(最も古い公開日は2000年)から今日までを年別にグループ化して要求されます。このクエリでは、+が%2BとしてURLエンコードされていることに注意してください。
ターミナルには次のようなものが表示されます。
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":8,
"params":{
"facet.range":"initial_release_date",
"facet.limit":"300",
"q":"*:*",
"facet.range.gap":"+1YEAR",
"rows":"0",
"facet":"on",
"facet.range.start":"NOW-25YEAR",
"facet.range.end":"NOW"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{
"initial_release_date":{
"counts":[
"1997-01-01T00:00:00Z",0,
"1998-01-01T00:00:00Z",0,
"1999-01-01T00:00:00Z",0,
"2000-01-01T00:00:00Z",80,
"2001-01-01T00:00:00Z",94,
"2002-01-01T00:00:00Z",112,
"2003-01-01T00:00:00Z",125,
"2004-01-01T00:00:00Z",166,
"2005-01-01T00:00:00Z",167,
"2006-01-01T00:00:00Z",173,
"2007-01-01T00:00:00Z",45,
"2008-01-01T00:00:00Z",13,
"2009-01-01T00:00:00Z",5,
"2010-01-01T00:00:00Z",1,
"2011-01-01T00:00:00Z",0,
"2012-01-01T00:00:00Z",0,
"2013-01-01T00:00:00Z",2,
"2014-01-01T00:00:00Z",0,
"2015-01-01T00:00:00Z",1,
"2016-01-01T00:00:00Z",0],
"gap":"+1YEAR",
"start":"1997-01-01T00:00:00Z",
"end":"2017-01-01T00:00:00Z"}},
"facet_intervals":{},
"facet_heatmaps":{}}}ピボットファセット
別のファセットの種類として、ピボットファセット(「決定木」とも呼ばれます)があり、複数のフィールドをネストしてあらゆる組み合わせを表示できます。「映画」データを使用すると、ピボットファセットを使用して、「ドラマ」カテゴリ(genre_strフィールド)の映画が何本の監督によって監督されているかを確認できます。このシナリオの生データを取得する方法は次のとおりです。
$ curl "https://:8983/solr/films/select?q=\*:*&rows=0&facet=on&facet.pivot=genre_str,directed_by_str"これにより、次の応答が生成されます。これは、カテゴリと監督の組み合わせごとにファセットを示しています。
{"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":1147,
"params":{
"q":"*:*",
"facet.pivot":"genre_str,directed_by_str",
"rows":"0",
"facet":"on"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{},
"facet_pivot":{
"genre_str,directed_by_str":[{
"field":"genre_str",
"value":"Drama",
"count":552,
"pivot":[{
"field":"directed_by_str",
"value":"Ridley Scott",
"count":5},
{
"field":"directed_by_str",
"value":"Steven Soderbergh",
"count":5},
{
"field":"directed_by_str",
"value":"Michael Winterbottom",
"count":4}}]}]}}}この出力も短縮しています。画面上には多くのジャンルと監督が表示されます。
演習2 まとめ
この演習では、Solrがインデックス内でデータをどのように整理するか、そしてスキーマAPIを使用してスキーマファイルを操作する方法について少し学びました。また、Solrのファセットについても学びました。範囲ファセットとピボットファセットを含みます。これら2つのことについては、利用可能なオプションのごく一部しか触れていません。想像できることなら、実現できるかもしれません!
前の演習と同様に、このデータはニーズに合致しない場合があります。作業をクリーンアップするには、コレクションを削除します。そのためには、コマンドラインで次のコマンドを実行します。
$ bin/solr delete -c films