その他のクエリパーサー
メインのクエリパーサーに加えて、特定の目的のためにメインのパーサーの代わりに、またはそれらと組み合わせて使用できるいくつかの他のクエリパーサーがあります。
このセクションでは、その他のパーサーについて詳しく説明し、それらの使用方法の例を示します。
これらのパーサーの多くは、ローカルパラメーターと同じように表現されます。
ブロック結合クエリパーサー
ブロック結合クエリパーサーは、ネストされたドキュメントで親や子をクエリするために使用されます。
これらのパーサーの詳細については、ブロック結合クエリパーサーのセクションで説明しています。
ブールクエリパーサー
BoolQParserは、他のクエリのブール組み合わせであるLucene BooleanQueryを作成します。サブクエリとそれらの型付き出現は、ドキュメントがどのように一致し、スコアリングされるかを示します。
パラメーター
must-
オプション
デフォルト: none
一致するドキュメントに必ず出現し、スコアに貢献するクエリのリスト。
must_not-
オプション
デフォルト: none
一致するドキュメントに絶対に出現してはならないクエリのリスト。
should-
オプション
デフォルト: none
一致するドキュメントに出現するべきクエリのリスト。
mustクエリのないBooleanQueryの場合、BooleanQueryが一致するためには、1つ以上のshouldクエリがドキュメントと一致する必要があります。 filter-
オプション
デフォルト: none
一致するドキュメントに必ず出現するクエリのリスト。ただし、
mustとは異なり、フィルタークエリのスコアは無視されます。また、これらのクエリはフィルターキャッシュにキャッシュされます。キャッシングを避けるには、ローカルパラメーターとしてcache=falseを追加するか、基になるクエリDSLオブジェクトに"cache":"false"プロパティを追加します。 mm-
オプション
デフォルト:
0一致する必要があるオプションの句の数。デフォルトでは、一致にオプションの句は必要ありません(必須の句がない場合を除く)。このパラメーターを設定すると、指定された数の
should句が必要になります。このパラメーターが設定されていない場合、ブールクエリに関する通常のルールが検索時に適用されます。つまり、必須の句が含まれていないブールクエリは、少なくとも1つのオプションの句と一致する必要があります。 excludeTags-
オプション
デフォルト: none
上記のパラメーターからクエリを除外するための、カンマ区切りのタグのリスト。下記の説明を参照してください。
例
{!bool must=foo must=bar}{!bool filter=foo should=bar}{!bool should=foo should=bar should=qux mm=2}パラメーターは、複数の値の参照である場合もあります。上記の最初の例は、以下と同等です
q={!bool must=$ref}&ref=foo&ref=bar参照されるクエリは、タグを介して除外される場合があります。全体的な考え方は、ファセットでfqを除外するのと同様です。
q={!bool must=$ref excludeTags=t2}&ref={!tag=t1}foo&ref={!tag=t2}bar後のクエリはt2を介して除外されるため、結果のクエリは以下と同等です
q={!bool must=foo}ブーストクエリパーサー
BoostQParserは、QParserPluginを拡張し、入力値からブーストされたクエリを作成します。メインの値は、元のクエリと一致するドキュメントだけが、このパーサーによって生成された最終クエリと一致するような、「ラップ」および「ブースト」されるクエリです。パラメーターbは、元のクエリと一致する各ドキュメントに対して評価される関数であり、関数の結果は、そのドキュメントの最終スコアに掛けられます。
ブーストクエリパーサーの例
name:foo というクエリを作成し、関数クエリ log(popularity) でブースト(スコアを乗算)します。
q={!boost b=log(popularity)}name:fooname:foo というクエリを作成し、数値フィールド price の逆数をスコアに乗算します。これにより、高い price を持つドキュメントの最終スコアを下げて、事実上「降格」させます。
// NOTE: we "add 1" to the denominator to prevent divide by zero
q={!boost b=div(1,add(1,price))}name:fooquery(…) 関数は、メインクエリに一致する各ドキュメントのスコアを、別のクエリからそのドキュメントが得るスコアで乗算(または除算)したい場合に特に役立ちます。
この例では、ローカルパラメーター変数を使用して、独立して指定されたクエリ category:electronics のスコアによってブーストされる name:foo のクエリを作成します。
q={!boost b=query($my_boost)}name:foo
my_boost=category:electronicsCollapsing Query Parser
CollapsingQParser は、結果セット内の異なるグループの数が多い場合に、Solr の標準的なアプローチよりもパフォーマンスの高いフィールドの折りたたみを提供する、実際にはポストフィルターです。
このパーサーは、結果セットをグループごとに単一のドキュメントに折りたたんでから、残りの検索コンポーネントに結果セットを転送します。したがって、すべてのダウンストリームコンポーネント(ファセット、ハイライトなど)は、折りたたまれた結果セットで動作します。
CollapsingQParser の使用に関する詳細は、「結果の折りたたみと展開」のセクションをご覧ください。
Complex Phrase Query Parser
ComplexPhraseQParser は、Lucene の ComplexPhraseQueryParser を使用して、フレーズクエリ内でワイルドカードや OR などが使えるようにサポートを提供します。
内部的には、このクエリパーサーは、spanNear、spanOrなどのSpanクエリグループを利用しており、そのファミリーまたはパーサーと同じ制限を受けます。
パラメーター
inOrder-
オプション
デフォルト:
trueフレーズクエリが指定された順序で用語を一致させるように強制する場合は、
trueに設定します。 df-
オプション
デフォルト: none
デフォルトの検索フィールド。
例
{!complexphrase inOrder=true}name:"Jo* Smith"{!complexphrase inOrder=false}name:"(john jon jonathan~) peters*"順序付きと順序なしの複合フレーズクエリの組み合わせ
+_query_:"{!complexphrase inOrder=true}manu:\"a* c*\"" +_query_:"{!complexphrase inOrder=false df=name}\"bla* pla*\""複合フレーズパーサーの制限事項
パフォーマンスは、パターンに関連付けられている一意の用語の数に左右されます。たとえば、「a*」を検索すると、単一の文字「a」で始まる指定されたフィールドのインデックスにあるすべての用語について、大きな OR 句(技術的には多くの用語を含む SpanOr)が形成されます。ワイルドカードは、少なくとも2文字、できれば3文字以上のプレフィックスに制限することが賢明でしょう。非常に短いプレフィックスを許可すると、多数の低品質のドキュメントが返される可能性があります。
先頭のワイルドカード「*a」もサポートしており、その結果、パフォーマンスに影響があることに注意してください。インデックス時の分析でReversedWildcardFilterFactoryを適用することが通常は良い方法です。
複合フレーズパーサーでの MaxBooleanClauses
上記のような用語展開の結果として、solrconfig.xml で MaxBooleanClauses を増やす必要があるかもしれません。
<maxBooleanClauses>4096</maxBooleanClauses>このプロパティの詳細については、「クエリのサイズ設定とウォーミング」のセクションで説明しています。
複合フレーズパーサーでのストップワード
このクエリパーサーでストップワードの削除を使用することは推奨されません。
コレクションの stopwords.txt に the、up、および to という用語を追加し、「features」というフィールドに「Stores up to 15,000 songs, 25,00 photos, or 150 yours of video」というテキストを含むドキュメントをインデックス付けすると仮定します。
以下のクエリはこのパーサーを使用しませんが
q=features:"Stores up to 15,000"ドキュメントが返されます。次のクエリは、このクエリのように、複合フレーズクエリパーサーを使用します。
q=features:"sto* up to 15*"&defType=complexphraseSpanNearQueryには、PhraseQueryに類似した方法でストップワードを処理する適切な方法がないため、そのドキュメントを返しません。ユースケースでストップワードを削除する必要がある場合は、カスタムフィルターファクトリを使用するか、指定されたストップワードを不可能トークンに減らすカスタマイズされた同義語フィルターを使用してください。
Field Query Parser
FieldQParser は QParserPlugin を拡張し、テキスト分析を適用し、必要に応じてフレーズクエリを構築することで、入力値からフィールドクエリを作成します。パラメータ f はクエリ対象のフィールドです。
例
{!field f=myfield}Foo Barこの例では、「foo」の後に「bar」が続くフレーズクエリを作成します(myfield のアナライザーが、空白で分割し、用語を小文字にするアナライザーを持つテキストフィールドであると仮定します)。これは一般に、Lucene クエリパーサー式 myfield:"Foo Bar" と同等です。
Filters Query Parser
構文は次のとおりです。
q={!filters param=$fqs excludeTags=sample}field:text&
fqs=COLOR:Red&
fqs=SIZE:XL&
fqs={!tag=sample}BRAND:Foo
これは以下と同等です。
q=+field:text +COLOR:Red +SIZE:XL
param ローカルパラメーターは、「$」構文を使用していくつかのクエリを参照します。ここで、excludeTags はそれらの一部を省略できます。
Function Query Parser
FunctionQParser は QParserPlugin を拡張し、入力値から関数クエリを作成します。これは、Solr で関数クエリを使用する1つの方法にすぎません。別のより統合されたアプローチについては、「関数クエリ」のセクションを参照してください。
例
{!func}log(foo)Function Range Query Parser
FunctionRangeQParser は QParserPlugin を拡張し、関数に対して範囲クエリを作成します。これは、以下の例に見られるように frange とも呼ばれます。
パラメーター
l-
オプション
デフォルト: none
下限。
u-
オプション
デフォルト: none
上限。
incl-
オプション
デフォルト:
true下限を含めます。
incu-
オプション
デフォルト:
true上限を含めます。
例
{!frange l=1000 u=50000}myfield fq={!frange l=0 u=2.2} sum(user_ranking,editor_ranking)これらの両方の例では、宣言されたフィールドまたは関数クエリで見つかった値の範囲によって結果が制限されます。2番目の例では、合計計算を行い、0〜2.2の間の値のみがユーザーに返されるように定義しています。
関数に対する範囲クエリの詳細については、Yonik Seeley の入門ブログ記事「Solr 1.4 での関数に対する範囲」を参照してください。
Graph Query Parser
graph クエリパーサーは、ラップされたクエリによって識別される開始ルートドキュメントのセットから「到達可能」なすべてのドキュメントの幅優先の周期的認識グラフトラバーサルを実行します。
グラフは、クエリの一部として指定する from フィールドと to フィールドに見つかった用語に基づいて、ドキュメント間のリンクに従って構築されます。
サポートされているフィールドタイプは、docValuesが有効になっているポイントフィールド、またはindexed=trueまたはdocValues=trueの文字列フィールドです。
indexed=falseおよびdocValues=trueの文字列フィールドの場合は、SortedDocValuesField.newSlowSetQuery()のjavadocでそのパフォーマンス特性を参照してください。ほとんどのユースケースではindexed=trueの方がパフォーマンスが向上します。 |
グラフクエリパラメータ
to-
オプション
デフォルト:
edge_idsグラフトラバーサルのための送信エッジを識別するために検査する、一致するドキュメントのフィールド名。
from-
オプション
デフォルト:
node_id受信グラフエッジを識別するために検査する候補ドキュメント内のフィールド名。
traversalFilter-
オプション
デフォルト: none
トラバースするドキュメントの範囲を制限するために提供できるオプションのクエリ。
maxDepth-
オプション
デフォルト:
-1(無制限)初期クエリから始まるグラフの幅優先検索の深さを指定する整数。
returnRoot-
オプション
デフォルト:
true元のクエリに一致したドキュメント(グラフの開始点を定義するため)を最終結果に含めるかどうかを示すブール値。
returnOnlyLeaf-
オプション
デフォルト:
falseクエリの結果をフィルタリングして、送信エッジのないドキュメントのみが返されるようにするかどうかを示すブール値。
useAutn-
オプション
デフォルト:
false幅優先検索の各反復でオートマトンをコンパイルする必要があるかどうかを示すブール値。一部のグラフでは高速になる場合があります。
グラフクエリの制限事項
graph パーサーは、単一ノードの Solr インストールでのみ、または正確に 1 つのシャードを使用する SolrCloud およびユーザー管理クラスターでのみ機能します。
グラフクエリの例
グラフパーサーの仕組みを理解するために、8つのノード(A〜H)と9つのエッジ(1〜9)を含む次の有向環状グラフを考えてみましょう。
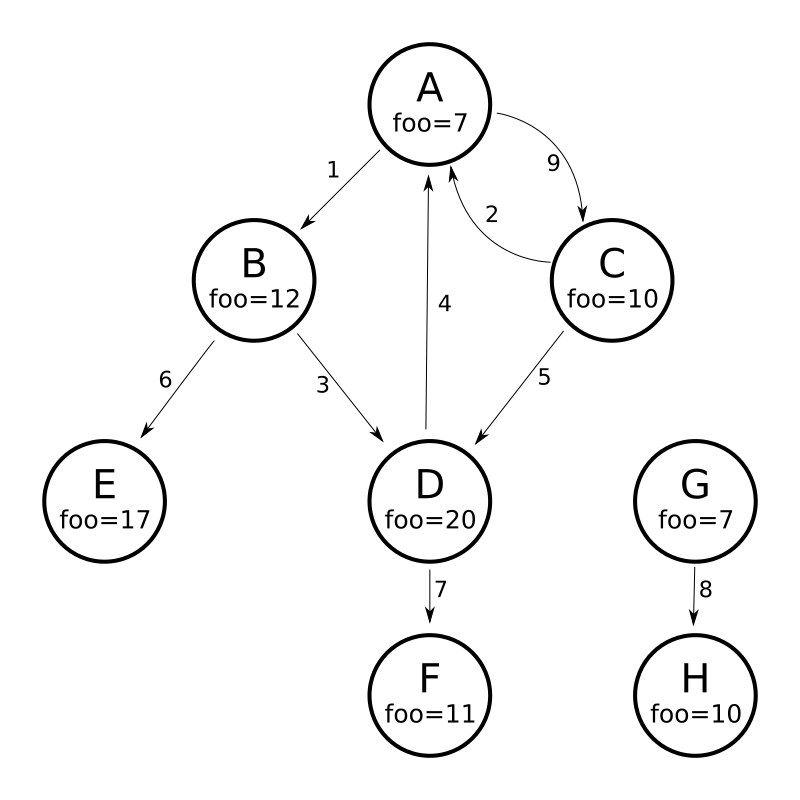
このグラフを Solr ドキュメントとしてモデル化する1つの方法は、ノードごとに1つのドキュメントを作成し、各ノードの受信エッジと送信エッジを識別する多値フィールドを使用することです。
curl -H 'Content-Type: application/json' 'https://:8983/solr/my_graph/update?commit=true' --data-binary '[
{"id":"A","foo": 7, "out_edge":["1","9"], "in_edge":["4","2"] },
{"id":"B","foo": 12, "out_edge":["3","6"], "in_edge":["1"] },
{"id":"C","foo": 10, "out_edge":["5","2"], "in_edge":["9"] },
{"id":"D","foo": 20, "out_edge":["4","7"], "in_edge":["3","5"] },
{"id":"E","foo": 17, "out_edge":[], "in_edge":["6"] },
{"id":"F","foo": 11, "out_edge":[], "in_edge":["7"] },
{"id":"G","foo": 7, "out_edge":["8"], "in_edge":[] },
{"id":"H","foo": 10, "out_edge":[], "in_edge":["8"] }
]'上記のモデルでは、次のクエリはノードAから到達可能なすべてのノードの単純なトラバーサルを示しています。
https://:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge}id:A"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"E" },
{ "id":"F" } ]
}traversalFilterを使用して、グラフトラバーサルをfooフィールドの最大値が15のノードのみに制限することもできます。この場合、D、E、Fは除外されます。Fにはfoo=11の値がありますが、トラバーサルがDをスキップしたため、到達できません。
https://:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge+traversalFilter='foo:[*+TO+15]'}id:A...
"response":{"numFound":3,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" } ]
}これまで示した例ではすべて、グラフトラバーサルのルートノードとして単一のドキュメント("id:A")のクエリを使用しましたが、任意のクエリを使用して、ルートノードとして使用する複数のドキュメントを識別できます。次の例では、maxDepthパラメーターを使用して、fooフィールドの値が10以下のルートノードから最大1つのエッジ離れたすべてのノードを検索する方法を示しています。
https://:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge+maxDepth=1}foo:[*+TO+10]...
"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"G" },
{ "id":"H" } ]
}簡略化されたモデル
上記の例で使用したドキュメントとフィールドのモデリングでは、「from」および「to」パラメーターの正確な動作を示すために、各ノードのすべての送信エッジと受信エッジを明示的に列挙し、可能なことのアイデアを提供しました。受信エッジと送信エッジを識別するためのこのような複数のフィールドセットを使用すると、コレクション内の一部のドキュメントまたはすべてのドキュメントを含む多くの独立した有向グラフをモデル化できます。
しかし、多くの場合、使用されるモデルを大幅に簡略化することも可能です。
たとえば、上記の図に示す同じグラフは、各ノードを表し、受信リンクに関する何も知らずに、リンク先のノードのIDのみを知っているSolrドキュメントでモデル化できます。
curl -H 'Content-Type: application/json' 'https://:8983/solr/alt_graph/update?commit=true' --data-binary '[
{"id":"A","foo": 7, "out_edge":["B","C"] },
{"id":"B","foo": 12, "out_edge":["E","D"] },
{"id":"C","foo": 10, "out_edge":["A","D"] },
{"id":"D","foo": 20, "out_edge":["A","F"] },
{"id":"E","foo": 17, "out_edge":[] },
{"id":"F","foo": 11, "out_edge":[] },
{"id":"G","foo": 7, "out_edge":["H"] },
{"id":"H","foo": 10, "out_edge":[] }
]'この代替ドキュメントモデルを使用すると、「from」パラメーターを「in_edge」フィールドを「id」フィールドに置き換えるだけで、上記で説明したすべての同じクエリを実行できます。
https://:8983/solr/alt_graph/query?fl=id&q={!graph+from=id+to=out_edge+maxDepth=1}foo:[*+TO+10]...
"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"G" },
{ "id":"H" } ]
}Hash Range Query Parser
ハッシュ範囲クエリパーサーは、特定の範囲にハッシュされる値を含むフィールドを持つドキュメントを返します。これは、method=crossCollectionを使用する場合に、結合クエリパーサーによって使用されます。ハッシュ範囲クエリパーサーには、このクエリパーサーが動作するフィールドごとにセグメントごとのキャッシュがあります。
ハッシュ範囲クエリパーサーで最小/最大ハッシュ範囲とフィールド名を指定すると、その範囲にハッシュされるフィールド値を含むドキュメントのみが返されます。非常に大きな結果セットをクエリする場合は、さまざまなハッシュ範囲をクエリして、各範囲リクエストでドキュメントの一部を返すことができます。
コレクション間結合の場合、ハッシュ範囲クエリパーサーは、各シャードがそのシャードで最終的に結合キーのセットのみを取得するようにするために使用されます。
このクエリパーサーは、MurmurHash3_x86_32を使用します。これは、Solrのデフォルトの複合IDルーターのデフォルトのハッシュと同じです。
Joinクエリパーサー
Joinクエリパーサーを使用すると、ユーザーはSQLスタイルの結合と同様に、ドキュメント間の関係を正規化するクエリを実行できます。
このクエリパーサーの詳細については、「Joinクエリパーサー」セクションを参照してください。
Learning To Rankクエリパーサー
LTRQParserPluginは、機械学習モデルに基づいた、より複雑なランキングクエリを使用して、単純なクエリの上位結果を再ランキングするための特別なパーサーです。
例
{!ltr model=myModel reRankDocs=100}LTRQParserPluginの使用に関する詳細は、「Learning To Rank」セクションにあります。
Max Scoreクエリパーサー
MaxScoreQParserはLuceneQParserを拡張しますが、句から最大スコアを返します。これは、すべてのSHOULD句をtie=1.0のDisjunctionMaxQueryでラップすることで行われます。MUSTまたはPROHIBITED句は、そのまま渡されます。数値範囲などの非ブールクエリは、LuceneQParserパーサーの動作にフォールスルーします。
例
{!maxscore tie=0.01}C OR (D AND E)MinHashクエリパーサー
MinHashQParserは、MinHashFilterFactoryで分析されたフィールドのクエリを構築します。このクエリは、クエリ文字列とMinHashフィールド間のJaccard類似度を測定し、必要に応じて高速で近似的なマッチングを可能にします。パーサーは2つの動作モードをサポートしています。1つ目は、通常の分析によってテキストからトークンが生成される場合です。2つ目は、明示的なトークンが提供される場合です。
現在、クエリによって返されるスコアは、一致するトップレベル要素の数を反映しており、0と1の間で正規化されて**いません**。
sim-
必須
デフォルト: none
最小類似度。デフォルトの動作は、ゼロよりも大きい類似度を見つけることです。
0.0と1.0の間の数値。 tp-
オプション
デフォルト:
1.0必要な真陽性率。
1.0よりも低い値の場合、最適化された高速なバンド化クエリを使用できます。バンド化の動作は、要求されたsimとtpの値によって異なります。 field-
オプション
デフォルト: none
MinHash値がインデックス化されるフィールド。このフィールドは通常、クエリパーサーに提供されるテキストを分析するために使用されます。これは、クエリフィールドにも使用されます。
sep-
オプション
デフォルト: " " (空文字列)
区切り文字列。空でない区切り文字列が提供される場合、クエリ文字列は、区切り文字列で区切られた事前分析された値のリストとして解釈されます。この場合、文字列の他の分析は実行されません。トークンは検出されたとおりに使用されます。
analyzer_field-
オプション
デフォルト: none
このパラメーターを使用すると、クエリフィールドとは別に、テキストの分析方法を定義できます。事前分析された文字列の
fieldを使用してMinHash値を格納する場合、クエリテキストを分析するために使用されます。以下の例を参照してください。
このクエリパーサーは、min_hashという名前で登録されています。
分析されたフィールドの例
典型的な分析
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUFoldingFilterFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" maxShingleSize="5" tokenSeparator=" "/>
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" bucketCount="512" hashSetSize="1" hashCount="1"/>
</analyzer>
</fieldType>
...
<field name="min_hash_analysed" type="text_min_hash" multiValued="false" indexed="true" stored="false" />ここで、入力テキストは空白で分割され、トークンが正規化され、結果のトークンストリームがすべての5ワードシングルのストリームにアセンブルされ、ハッシュ化されます。各512バケットの最低ハッシュが保持され、出力トークンとして生成されます。
このフィールドへのクエリは、少なくとも1つのシングルを生成する必要があるため、5つの異なるトークンが必要です。
クエリの例
{!min_hash field="min_hash_analysed"}At least five or more tokens
{!min_hash field="min_hash_analysed" sim="0.5"}At least five or more tokens
{!min_hash field="min_hash_analysed" sim="0.5" tp="0.5"}At least five or more tokens事前分析されたフィールドの例
ここで、MinHashは事前に計算されます。ほとんどの場合、以下に示すように、Lucene分析をインラインで使用します。スキーマからアナライザーを取得する方が賢明です。
ICUTokenizerFactory factory = new ICUTokenizerFactory(Collections.EMPTY_MAP);
factory.inform(null);
Tokenizer tokenizer = factory.create();
tokenizer.setReader(new StringReader(text));
ICUFoldingFilterFactory filter = new ICUFoldingFilterFactory(Collections.EMPTY_MAP);
TokenStream ts = filter.create(tokenizer);
HashMap<String, String> args = new HashMap<>();
args.put("minShingleSize", "5");
args.put("outputUnigrams", "false");
args.put("outputUnigramsIfNoShingles", "false");
args.put("maxShingleSize", "5");
args.put("tokenSeparator", " ");
ShingleFilterFactory sff = new ShingleFilterFactory(args);
ts = sff.create(ts);
HashMap<String, String> args2 = new HashMap<>();
args2.put("bucketCount", "512");
args2.put("hashSetSize", "1");
args2.put("hashCount", "1");
MinHashFilterFactory mhff = new MinHashFilterFactory(args2);
ts = mhff.create(ts);
CharTermAttribute termAttribute = ts.getAttribute(CharTermAttribute.class);
ts.reset();
while (ts.incrementToken())
{
char[] buff = termAttribute.buffer();
...
}
ts.end();スキーマは、分析時に使用する多値の文字列値とオプションのフィールドを定義するだけです(上記と同様)。
<field name="min_hash_string" type="strings" multiValued="true" indexed="true" stored="true"/>
<!-- Optional -->
<field name="min_hash_analysed" type="text_min_hash" multiValued="false" indexed="true" stored="false"/>
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" multiValued="true"/>
<!-- Optional -->
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUFoldingFilterFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" maxShingleSize="5" tokenSeparator=" "/>
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" bucketCount="512" hashSetSize="1" hashCount="1"/>
</analyzer>
</fieldType>クエリの例
{!min_hash field="min_hash_string" sep=","}HASH1,HASH2,HASH3
{!min_hash field="min_hash_string" sim="0.9" analyzer_field="min_hash_analysed"}Lets hope the config and code for analysis are in sync既知のハッシュを使用して、分析されたフィールドをクエリすることもできます (上記とは逆)
{!min_hash field="min_hash_analysed" analyzer_field="min_hash_string" sep=","}HASH1,HASH2,HASH3事前分析されたフィールドとは、ハッシュ値を再ハッシュするのではなく、ドキュメントごとに回復できることを意味します。MinHash格納フィールドを返す初期クエリステージの後に、類似のドキュメントを見つけるためのmin_hashクエリを続けることができます。
バンド化クエリ
上記の構成が与えられた場合、クエリパーサーのデフォルトの動作は、ブールクエリを生成し、512個の定数スコアタームクエリを一緒にORすることです。各ハッシュに対して1つです。この場合、1つのハッシュが一致する場合はスコア1を生成し、すべて一致する場合はスコア512を生成します。
バンド化されたクエリは、連言と離言を混在させます。2つのクエリを一緒にAND結合した256のバンド、4つのハッシュを一緒にAND結合した128のバンドなどを持つことができます。バンド数が少ないほど、クエリのパフォーマンスは向上しますが、一部の一致を見逃す可能性があります。速度と精度の間にトレードオフがあります。64のバンドでは、スコアは0から64の範囲になります (一緒にOR結合されたバンドの数)。
必要な類似度と許容可能な真陽性率が与えられた場合、クエリパーサーは適切なバンドサイズ[1]を計算します。以下を条件として、最小バンド数を検索します。
クエリの最後のバンドを埋めるのに十分なハッシュがない場合は、先頭にラップされます。
参考文献
一般的な入門については、「Mining of Massive Datasets」[1]を参照してください。
約1500語のドキュメントの場合、インデックスサイズのオーバーヘッドは約10%になると予想されます。ただし、実際には異なる場合があります。512個のハッシュは、約2500語をうまく表現することが期待されます。
MinHash値のセットを使用することは、最初の論文[2]で提案されましたが、Jaccard類似度の偏った推定を提供します。その偏りが良い場合もあるかもしれません。同様に、回転や短いドキュメントの場合も同様です。実装は、後の研究[3]で提案された偏りのない方法から派生しています。
[1] Leskovec, Jure; Rajaraman, Anand & Ullman, Jeffrey D. 「Mining of Massive Datasets」、Cambridge University Press; 第2版 (2014年12月29日)、第3章、ISBN: 9781107077232。
[2] Broder, Andrei Z. (1997), 「On the resemblance and containment of documents」、Compression and Complexity of Sequences: Proceedings, Positano, Amalfitan Coast, Salerno, Italy, June 11-13, 1997 (PDF), IEEE, pp. 21–29, doi:10.1109/SEQUEN.1997.666900。
[3] Shrivastava, Anshumali & Li, Ping (2014), 「Improved Densification of One Permutation Hashing」、第30回人工知能の不確実性に関する会議(UAI)、ケベックシティ、ケベック、カナダ、2014年7月23~27日、AUAI, pp. 225-234, http://www.auai.org/uai2014/proceedings/individuals/225.pdf
More Like Thisクエリパーサー
MLTQParserを使用すると、特定のドキュメントに類似したドキュメントを取得できます。これは、Luceneの既存のMoreLikeThisロジックを使用し、SolrCloudモードでも動作します。このクエリパーサーの使用方法については、「MoreLikeThis」のドキュメント、「MoreLikeThisクエリパーサー」セクションを参照してください。
ネストされたクエリパーサー
NestedParserはQParserPluginを拡張し、ローカルパラメーターを介してそのタイプを再定義できるネストされたクエリを作成します。これは、構成でデフォルトを指定し、クライアントが間接的にそれらを参照できるようにする場合に便利です。
例
{!query defType=func v=$q1}q1パラメーターがpriceの場合、クエリはpriceフィールドの関数クエリになります。q1パラメーターが\{!lucene}inStock:true}}の場合、inStock=trueのドキュメントに一致するLucene構文文字列からタームクエリが作成されます。これらのパラメーターは、solrconfig.xmlのdefaultsセクションで定義されます。
<lst name="defaults">
<str name="q1">{!lucene}inStock:true</str>
</lst>ネストされたクエリの可能性の詳細については、Yonik Seeleyのブログ投稿「Nested Queries in Solr」を参照してください。
ペイロードクエリパーサー
これらのクエリパーサーは、インデックス作成中にタームにエンコードされたペイロードを利用します。ペイロードは、DelimitedPayloadTokenFilterまたはNumericPayloadTokenFilterを使用してタームにエンコードできます。
ペイロードスコアパーサー
PayloadScoreQParserは、一致する各タームの数値 (整数または浮動小数点) ペイロードをスコアに組み込みます。メインクエリは、以下のoperatorパラメーターの値に基づいて、フィールドタイプのクエリ分析からSpanQueryに解析されます。
このパーサーは、次のパラメーターを受け入れます。
f-
必須
デフォルト: none
使用するフィールド。
func-
必須
デフォルト: none
ペイロード関数。オプションは、
min、max、average、またはsumです。 operator-
オプション
デフォルト: none
検索演算子。オプションは次のとおりです。*
orは、発行されたトークンの数に応じて、SpanTermQueryまたはSpanOrQueryを生成します。*phraseは、発行されたトークンの数に応じて、SpanTermQueryまたは順序付けられたゼロスロップSpanNearQueryを生成します。 includeSpanScore-
オプション
デフォルト:
falsetrueの場合、計算されたペイロード係数に元のクエリのスコアを乗算します。falseの場合、計算されたペイロード係数がスコアになります。
例
{!payload_score f=my_field_dpf v=some_term func=max}{!payload_score f=payload_field func=sum operator=or}A B Cペイロードチェックパーサー
PayloadCheckQParser は、一致する用語がペイロードに対して指定された関係を持つ場合にのみ一致します。デフォルトの関係は equals ですが、不等号一致も実行できます。これらのパーサーの両方にとって、メインクエリは、フィールドタイプのクエリ分析からSpanQueryへと直接的に解析されます。生成されるSpanQueryは、トークンがいくつ出力されるかによって、SpanTermQueryまたは順序付けされたゼロスロップのSpanNearQueryのいずれかになります。その結果、メインクエリは常に標準のLuceneパーサーにおけるフレーズクエリと同様の動作をします(したがって、q.opの値は無視されます)。
フィールド分析がクエリに適用される際、トークン数が変更された場合、最終的なトークン数はpayloadsパラメータで提供されたペイロード数と一致する必要があります。クエリトークン数とこのクエリで提供されたペイロード値の数との間に不一致がある場合、クエリは一致しません。 |
このパーサーは、次のパラメーターを受け入れます。
f-
必須
デフォルト: none
使用するフィールド。
payloads-
必須
デフォルト: none
ドキュメント内の一致するトークンのペイロードと比較される、スペースで区切られたペイロードのリスト。指定された各ペイロードは、マッチング前にフィールドタイプから決定されたエンコーダーを使用してエンコードされます。整数、浮動小数点、およびID(文字列)エンコーディングは、
DelimitedPayloadTokenFilterと同じ意味でサポートされています。 op-
オプション
デフォルト:
eqペイロードチェックに適用する不等号演算。すべての操作は、クエリの分析から派生した連続するトークンがドキュメント内の連続するトークンと一致し、さらに、ドキュメントトークンのペイロードが以下でなければならないことを要求します。*
eq:指定されたペイロードと等しい *gt:指定されたペイロードより大きい *lt:指定されたペイロードより小さい *gte:指定されたペイロード以上 *lte:指定されたペイロード以下
例
「searching stuff」というフレーズが含まれ、"searching" のペイロードが "VERB" であり、"stuff" のペイロードが "NOUN" であるすべてのドキュメントを検索します。
{!payload_check f=words_dps payloads="VERB NOUN"}searching stuff"foo" が含まれ、"foo" のペイロードの値が 0.75 以上であるすべてのドキュメントを検索します。
{!payload_check f=words_dpf payloads="0.75" op="gte"}foo「foo bar」というフレーズが含まれ、"foo" という用語のペイロードが 9 より大きく、"bar" のペイロードが 5 より大きいすべてのドキュメントを検索します。
{!payload_check f=words_dpi payloads="9 5" op="gt"}foo bar
プレフィックスクエリパーサー
PrefixQParserは、入力値からプレフィックスクエリを作成することにより、QParserPluginを拡張します。現在、このプレフィックスクエリを作成するために、分析や値変換は行われません。
パラメータはf(フィールド)です。プレフィックス宣言の後の文字列は、ワイルドカードクエリとして扱われます。
例
{!prefix f=myfield}fooこれは一般的に、Luceneクエリパーサー式myfield:foo*と同等です。
ロークエリパーサー
RawQParserは、テキスト分析や変換なしに入力値からタームクエリを作成することにより、QParserPluginを拡張します。これは、デバッグ時や、タームコンポーネントからロータームが返される場合(これはデフォルトではありません)に役立ちます。
唯一のパラメータはfであり、検索するフィールドを定義します。
例
{!raw f=myfield}Foo Barこの例では、クエリTermQuery(Term("myfield","Foo Bar"))を構築します。
ファセットでドリルダウンするための簡単なフィルター構築には、TermQParserPluginをお勧めします。
テキストフィールドを含むすべてのフィールドで完全に分析するには、FieldQParserPluginを使用することを推奨します。
ランキングクエリパーサー
RankQParserPluginは、FunctionQParserのランキング関連機能のより高速な実装であり、RankFieldsタイプの特別なフィールドと連携できます。
以下のようなクエリが可能です
https://:8983/solr/techproducts?q=memory _query_:{!rank f='pagerank', function='log' scalingFactor='1.2'}リランキングクエリパーサー
ReRankQParserPluginは、より複雑なランキングクエリを使用して、単純なクエリの上位結果をリランキングするための特殊なパーサーです。
ReRankQParserPluginの使用に関する詳細は、クエリリランキングセクションを参照してください。
シンプルクエリパーサー
Solrのシンプルクエリパーサーは、LuceneのSimpleQueryParserに基づいています。このクエリパーサーは、ユーザーが好きなようにクエリを入力できるように設計されており、クエリを解釈し、結果を返すために最善を尽くします。
このパーサーは、次のパラメータを取ります
q.operators-
オプション
デフォルト:説明を参照
有効にする解析演算子の名前をコンマ区切りで指定したリスト。デフォルトでは、すべての操作が有効になっており、このパラメータを使用して、リストから除外することで、必要に応じて特定の操作を効果的に無効にできます。このパラメータに空の文字列を渡すと、すべての演算子が無効になります。
名前 演算子 説明 クエリ例 AND+ANDを指定します
token1+token2OR|ORを指定します
token1|token2NOT-NOTを指定します
-token3PREFIX*プレフィックスクエリを指定します
term*PHRASE"フレーズを作成します
"term1 term2"PRECEDENCE( )優先順位を指定します。括弧内のトークンは最初に分析されます。それ以外の場合、通常の順序は左から右です。
token1 + (token2 | token3)ESCAPE\演算子の前に置いて、文字通り一致させます
C+\+WHITESPACEスペースまたは
[\r\t\n]空白でトークンを区切ります。有効にしない場合、分析前に空白分割は実行されません。通常、最も望ましい動作です。
空白を分割しないことは、複数語の同義語を機能させるこのパーサーのユニークな機能です。ただし、同義語が、特定の同義語に一致するすべてに拡張するのではなく、正規化するように構成されていない限り、実際には機能しない可能性があります。このような構成では、インデックス時とクエリ時の両方で同義語を正規化する必要があります。Solrの分析画面が役立ちます。
term1 term2FUZZY~~N用語の最後に、ファジー検索を指定します。
"N"はオプションであり、"1"または"2"(デフォルト)のいずれかです
term~1NEAR~Nフレーズの最後に、NEAR検索を指定します
"term1 term2"~5 q.op-
オプション
デフォルト:
ORユーザーによって定義されていない場合に使用するデフォルトの演算子を定義します。許可される値は
ANDとORです。何も指定されていない場合はORが使用されます。 qf-
オプション
デフォルト: none
クエリを構築するときに使用するクエリフィールドとブーストのリスト。
df-
オプション
デフォルト: none
スキーマで何も定義されていない場合、デフォルトのフィールドを定義するか、すでに定義されている場合はデフォルトのフィールドを上書きします。
構文エラーはすべて無視され、クエリパーサーはできる限り最善を尽くしてクエリを解釈します。ただし、場合によっては奇妙な結果になる可能性があります。
空間クエリパーサー
Solrには、geofiltとbboxという2つの空間QParserがあります。ただし、空間的にクエリする方法は他にもあります。距離関数を持つfrangeパーサーを使用したり、標準(lucene)のクエリパーサーを範囲構文で使用して長方形の角を選択したり、RPTとBBoxFieldを使用すると、標準のクエリパーサーを使用できますが、空間述語を選択できる特別な構文を引用符内で使用できます。
これらのオプションはすべて、空間検索セクションで詳しく説明されています。
Surroundクエリパーサー
SurroundQParserは、近接検索機能を提供するSurroundクエリ構文を有効にします。2つの位置演算子があります。wは順序付きスパンクエリを作成し、nは順序なしスパンクエリを作成します。両方の演算子は、2つの用語間の距離を示す数値を受け取ります。デフォルトは1で、最大値は99です。
クエリ文字列は、いかなる方法でも分析されないことに注意してください。
例
{!surround} 3w(foo, bar)この例では、「foo」と「bar」という用語が互いに3つ以下の用語の距離(つまり、それらの間に2つ以下の用語)であるドキュメントを検索します。
このクエリパーサーは、ブール演算子(AND、OR、およびNOT、大文字または小文字のいずれか)、ワイルドカード、フレーズ検索の引用符、およびブーストも受け入れます。wおよびn演算子は、大文字または小文字で表現することもできます。
非単項演算子(NOTを除くすべて)は、中置記法(a AND b AND c)と前置記法AND(a, b, c)の両方をサポートします。
Switchクエリパーサー
SwitchQParserは、「スイッチ」または「case」ステートメントのように機能するQParserPluginです。
プライマリ入力文字列はトリミングされ、パーサーのローカルパラメータで「スイッチケース」を検索するためのキーとして使用するために、case.というプレフィックスが付けられます。一致するローカルパラメータが見つかった場合、結果のパラメータ値はサブクエリとして解析され、解析結果として返されます。
caseローカルパラメータは、オプションで、欠落している(または空白の)入力文字列に一致するスイッチケースとして指定できます。defaultローカルパラメータは、入力文字列が他のスイッチケースローカルパラメータと一致しない場合に使用するデフォルトケースとしてオプションで指定できます。defaultが指定されていない場合、スイッチケースローカルパラメータと一致しない入力は構文エラーになります。
以下の例では、各クエリの結果は「XXX」です。
{!switch case.foo=XXX case.bar=zzz case.yak=qqq}foo}とbarの間の余分な空白は自動的にトリミングされます。{!switch case.foo=qqq case.bar=XXX case.yak=zzz} bar{!switch case.foo=qqq case.bar=zzz default=XXX}asdfcaseの値を使用します。{!switch case=XXX case.bar=zzz case.yak=qqq}このパーサーの実用的な使用法は、SearchHandlerの構成でappendsフィルタークエリ(fq)パラメータを指定し、カスタムパラメータ名を使用するクライアントに固定されたフィルターオプションのセットを提供することです。
以下の構成例を使用すると、クライアントはオプションでカスタムパラメータin_stockとshippingを指定して、デフォルトのフィルタリング動作を上書きできますが、特定の法的値(shipping=any|free、in_stock=yes|no|all)のセットに制限されます。
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="in_stock">yes</str>
<str name="shipping">any</str>
</lst>
<lst name="appends">
<str name="fq">{!switch case.all='*:*'
case.yes='inStock:true'
case.no='inStock:false'
v=$in_stock}</str>
<str name="fq">{!switch case.any='*:*'
case.free='shipping_cost:0.0'
v=$shipping}</str>
</lst>
</requestHandler>タームクエリパーサー
TermQParserは、readableToIndexed()と同等の入力値から単一のタームクエリを作成することにより、QParserPluginを拡張します。これは、ファセットまたはタームコンポーネントによって返された外部の人間が読めるタームからフィルタークエリを生成するのに役立ちます。唯一のパラメータは、フィールド用のfです。
例
{!term f=weight}1.5テキストフィールドの場合、ファセットコンポーネントとタームコンポーネントからすでに生のタームが返されているため、分析は行われません。テキストフィールドにも分析を適用するには、上記のフィールドクエリパーサーを参照してください。
どのタイプのフィールドでも分析や変換が不要な場合は、上記のロークエリパーサーを参照してください。
タームクエリパーサー
TermsQParserはタームクエリパーサーと同様に機能しますが、カンマで区切られた複数の値を受け取り、指定された値のいずれかに一致するドキュメントを返します。
これは、ファセットコンポーネントまたはタームコンポーネントから返される外部の人間が読めるタームからフィルタークエリを生成するのに役立ち、デフォルトの実装methodがスコアリングを回避するため、標準クエリパーサーを使用してブールクエリを生成するよりも効率的な場合があります。
このクエリパーサーは、以下のパラメーターを受け取ります。
f-
必須
デフォルト: none
検索対象のフィールド。
separator-
オプション
デフォルト:
,(カンマ)入力を解析するときに使用する区切り文字。「 」(単一の空白文字)に設定すると、入力タームから余分な空白が削除されます。
method-
オプション
デフォルト:
termsFilterSolrで使用するクエリ実装を決定します。
オプションは、
termsFilter、booleanQuery、automaton、docValuesTermsFilterPerSegment、docValuesTermsFilterTopLevel、またはdocValuesTermsFilterに制限されます。各実装には独自のスケーリング特性があり、ユーザーはユースケースで最もパフォーマンスの高い実装を決定するために実験することを推奨します。以下にヒューリスティックを示します。
booleanQueryは、リクエストを表すBooleanQueryを作成します。インデックスサイズにはうまくスケーリングしますが、検索対象のターム数にはうまくスケーリングしません。termsFilterは、ターム数に応じてBooleanQueryまたはTermInSetQueryを使用します。インデックスサイズにはうまくスケーリングしますが、クエリターム数にはほどほどにスケーリングします。docValuesTermsFilterは、docValuesデータを持つフィールドでのみ使用できます。cacheパラメーターはデフォルトでfalseです。クエリターム数を大まかなヒューリスティックとして使用して、docValuesTermsFilterTopLevelメソッドとdocValuesTermsFilterPerSegmentメソッドのどちらを使用するかを選択します。ユーザーは通常、すべてのサイズのクエリでいずれかのメソッドを検証するパフォーマンステストを実施していない限り、docValuesTermsFilterTopLevelまたはdocValuesTermsFilterPerSegmentを直接使用するのではなく、このメソッドを使用する必要があります。選択した実装によっては、このメソッドは各コミット後に遅延的に設定される高価なデータ構造に依存する場合があります。コミット頻度が高く、ユースケースが静的なウォームアップクエリを許容できる場合は、コミットの一部としてこの作業が実行され、ユーザーリクエストに直接添付されないように、solrconfig.xmlにウォームアップクエリを追加することを検討してください。docValuesTermsFilterTopLevelは、docValuesデータを持つフィールドでのみ使用できます。cacheパラメーターはデフォルトでfalseです。トップレベルのdocValuesデータ構造を使用して結果を見つけます。これらのデータ構造は、クエリターム数が多くなるほど(数百を超える)、より効率的です。ただし、構築にもコストがかかり、各コミット後に遅延的に設定する必要があるため、各コミット後の最初のクエリで目立つほどの遅延が発生することがあります。コミット頻度が高く、ユースケースが静的なウォームアップクエリを許容できる場合は、コミットの一部としてこの作業が実行され、ユーザーリクエストに直接添付されないように、solrconfig.xmlにウォームアップクエリを追加することを検討してください。docValuesTermsFilterPerSegmentは、docValuesデータを持つフィールドでのみ使用できます。cacheパラメーターはデフォルトでfalseです。小から中程度(〜500)のクエリターム数では、「トップレベル」の代替よりも効率的であり、(docValuesTermsFilterTopLevelのように)コミット直後のクエリでの遅延が発生しません(上記を参照)。ただし、非常に多数のクエリタームではパフォーマンスが低下します。automatonは、各タームが結合を形成するリクエストを表すAutomatonQueryを作成します。インデックスサイズにはうまくスケーリングし、クエリターム数にはほどほどにスケーリングします。
例
{!terms f=tags}software,apache,solr,lucene{!terms f=categoryId method=booleanQuery separator=" "}8 6 7 5309XMLクエリパーサー
XmlQParserPluginはQParserPluginを拡張し、XMLからクエリを作成することをサポートします。例
| パラメーター | 値 |
|---|---|
defType |
|
q |
|
XmlQParserの実装は、LuceneのCoreParserクラスを拡張したSolrCoreParserクラスを使用します。XML要素は、次のようにQueryBuilderクラスにマッピングされます。
| XML要素 | QueryBuilderクラス |
|---|---|
<BooleanQuery> |
|
<BoostingTermQuery> |
|
<ConstantScoreQuery> |
|
<DisjunctionMaxQuery> |
|
<MatchAllDocsQuery> |
|
<RangeQuery> |
|
<SpanFirst> |
|
<SpanPositionRange> |
|
<SpanNear> |
|
<SpanNot> |
|
<SpanOr> |
|
<SpanOrTerms> |
|
<SpanTerm> |
|
<TermQuery> |
|
<TermsQuery> |
|
<UserQuery> |
|
<LegacyNumericRangeQuery> |
LegacyNumericRangeQuery(Builder) は非推奨です |
XMLクエリパーサーのカスタマイズ
追加のXML要素に対して、独自のカスタムクエリビルダーを構成できます。カスタムビルダーは、SolrQueryBuilderクラスまたはSolrSpanQueryBuilderクラスを拡張する必要があります。solrconfig.xmlの例を以下に示します。
<queryParser name="xmlparser" class="XmlQParserPlugin">
<str name="MyCustomQuery">com.mycompany.solr.search.MyCustomQueryBuilder</str>
</queryParser>