検索、サンプリング、集約
データは統計分析において不可欠な要素です。このセクションでは、可視化と統計分析のためにデータを取得するための主要な機能である検索、サンプリング、集約の概要を示します。
検索
探索
search 関数を使用して SolrCloud コレクションを検索し、結果セットを返すことができます。
以下は、Zeppelin-Solr インタープリタから呼び出される最も基本的な search 関数の例です。Zeppelin-Solr は seach(logs) 呼び出しを /stream ハンドラに送信し、結果を**テーブル**形式で表示します。
この例では、search 関数には検索対象のコレクション名のみが渡されます。これにより、すべてのフィールドを含む 10 件のレコードの結果セットが返されます。この単純な関数は、データのフィールドを探索し、検索条件の絞り込み方法を理解するのに役立ちます。
検索とソート
レコードの形式が分かれば、search 関数にパラメータを追加してデータの分析を開始できます。
以下の例では、検索クエリ、フィールドリスト、行数、ソートが search 関数に追加されています。これで、検索は特定の時間範囲内のレコードに限定され、tdate_dt を昇順にソートした最大 750 件のレコードの結果セットが返されます。また、結果セットは 3 つの特定のフィールドに限定されています。
データがテーブルに読み込まれたら、散布図に切り替えて、filesize_d 列を**x 軸**に、response_d 列を**y 軸**にプロットできます。
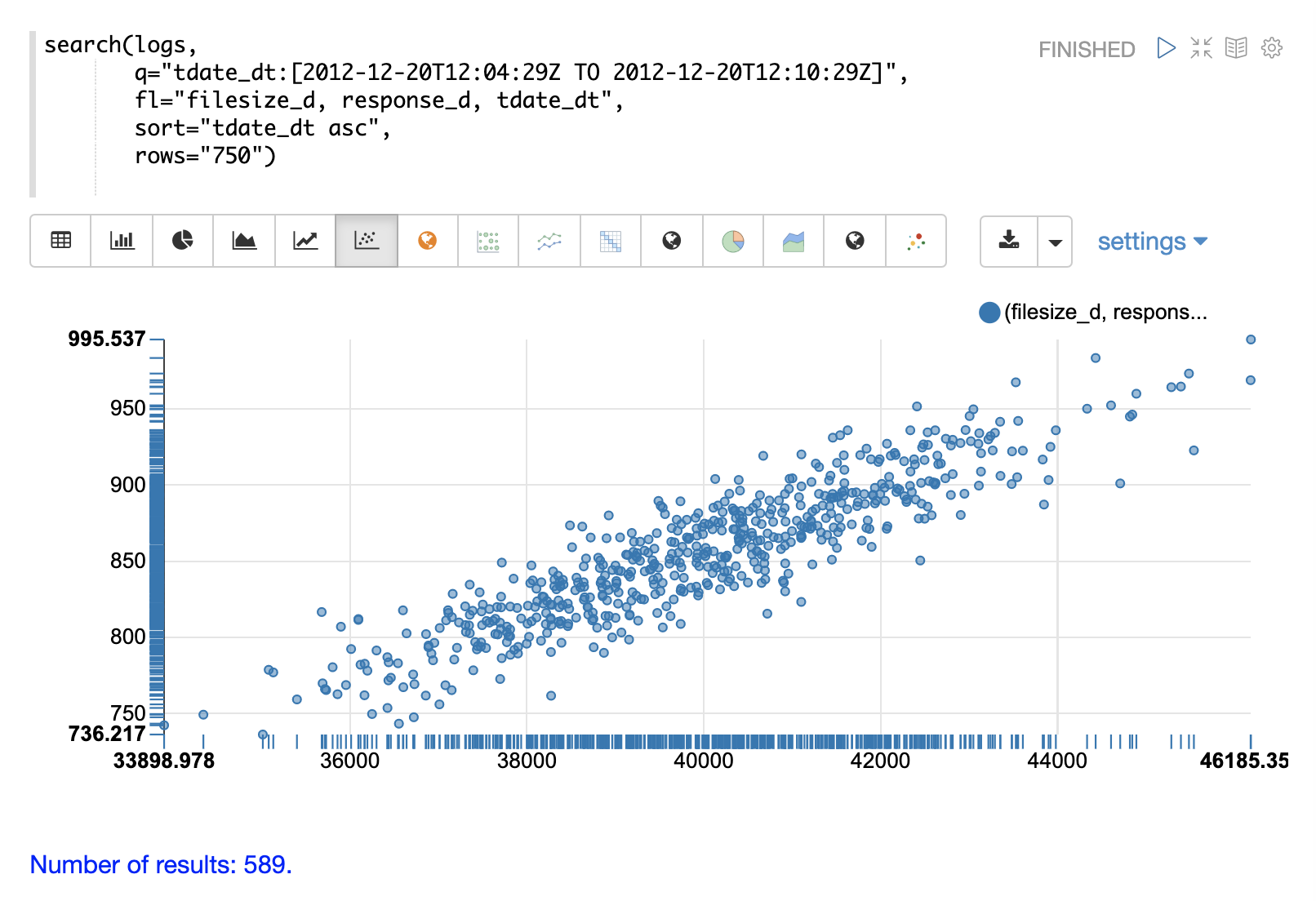
これにより、インデックスの非常に具体的なスライスから選択された 2 つの変数の関係を迅速に可視化できます。
サンプリング
random 関数は、分散検索結果セットからランダムサンプルを返します。これにより、より大きな結果セットに関する情報を推測するために使用できるサンプルの高速な可視化、統計分析、およびモデリングが可能になります。
以下の可視化の例では小さなランダムサンプルを使用していますが、Solr のランダムサンプリングは 20 万件を超えるサンプルサイズでサブ秒の応答時間を提供します。これらのより大きなサンプルを使用して、(数十億件のドキュメントを含む)大規模なデータセットを記述する信頼性の高い統計モデルをサブ秒のパフォーマンスで構築できます。
以下の例は、ランダムサンプルの単変量と二変量の散布図を示しています。ランダムサンプルを使用した統計モデリングについては、統計、確率分布、線形回帰、曲線フィッティング、機械学習 の各セクションを参照してください。
単変量散布図
以下の例では、random関数は、コレクション名をパラメータとして渡す最も単純な形式で呼び出されています。
他のパラメータを指定せずに呼び出された場合、random関数は、コレクションのすべてのフィールドを含む500件のレコードのランダムサンプルを返します。フィールドリストパラメータ(fl)を指定せずに呼び出された場合も、random関数はシーケンス(この場合は0~499)を生成します。これは、x軸のプロットに使用できます。このシーケンスはxというフィールドに格納されて返されます。
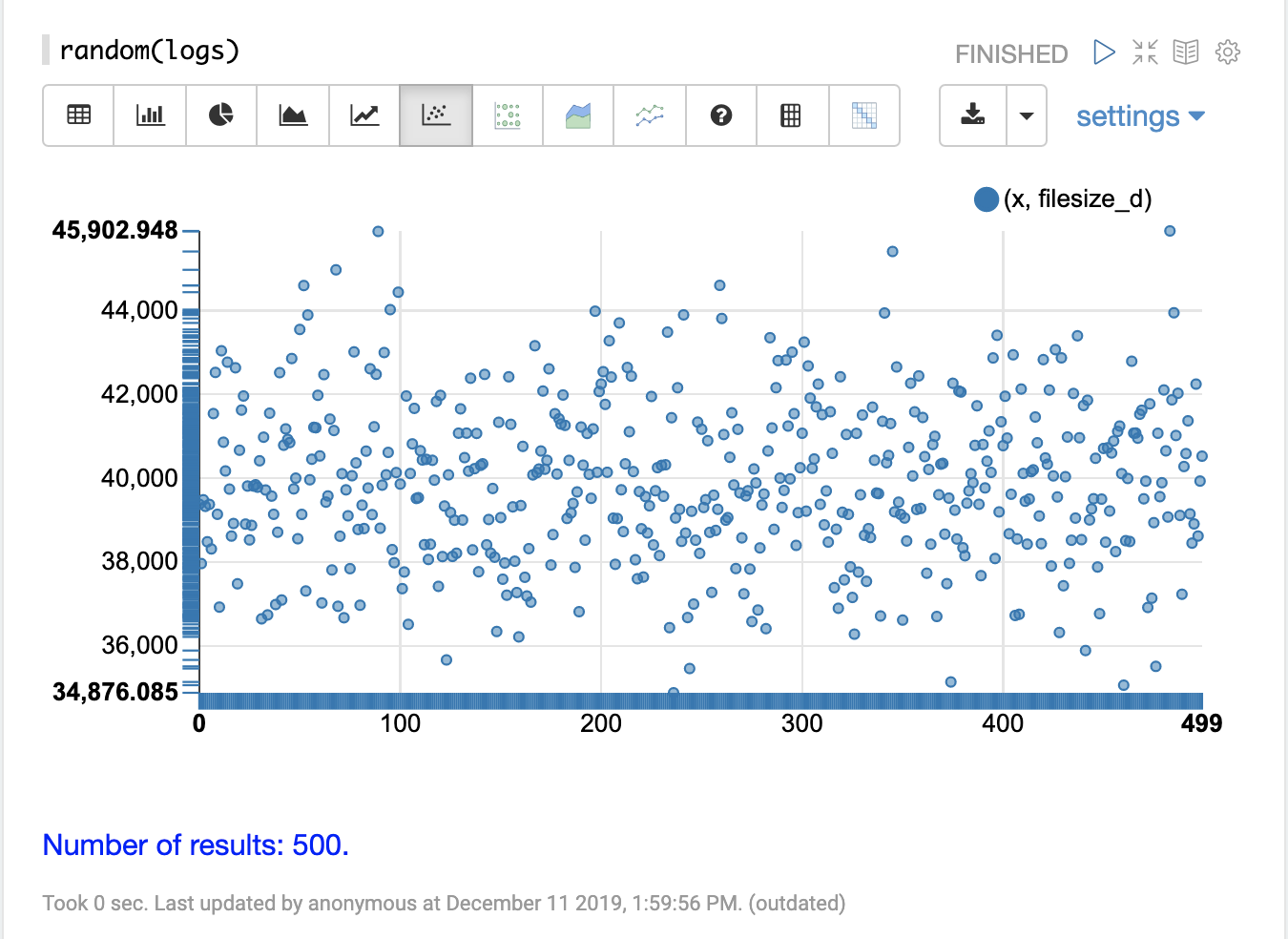
以下の視覚化は、y軸にfilesize_dフィールド、x軸にxシーケンスをプロットした散布図を示しています。これにより、filesize_dサンプルがプロットの長さにわたって分散され、より容易に調査できるようになります。
散布図を調べることで、filesize_d変数の分布に関するいくつかの情報を得ることができます。
-
サンプルセットの範囲は34,875~45,902です。
-
最も高い密度は約40,000に見られます。
-
サンプルは、40,000の上下でバランスの取れた数の観測値を持つようです。これに基づくと、**平均値**と**最頻値**は約40,000と思われます。
-
観測値の数は、サンプルの低位と高位の端で少数の外れ値に減少します。
このサンプルは複数回実行して、サンプルが同様のプロットを生成するかどうかを確認できます。
二変量散布図
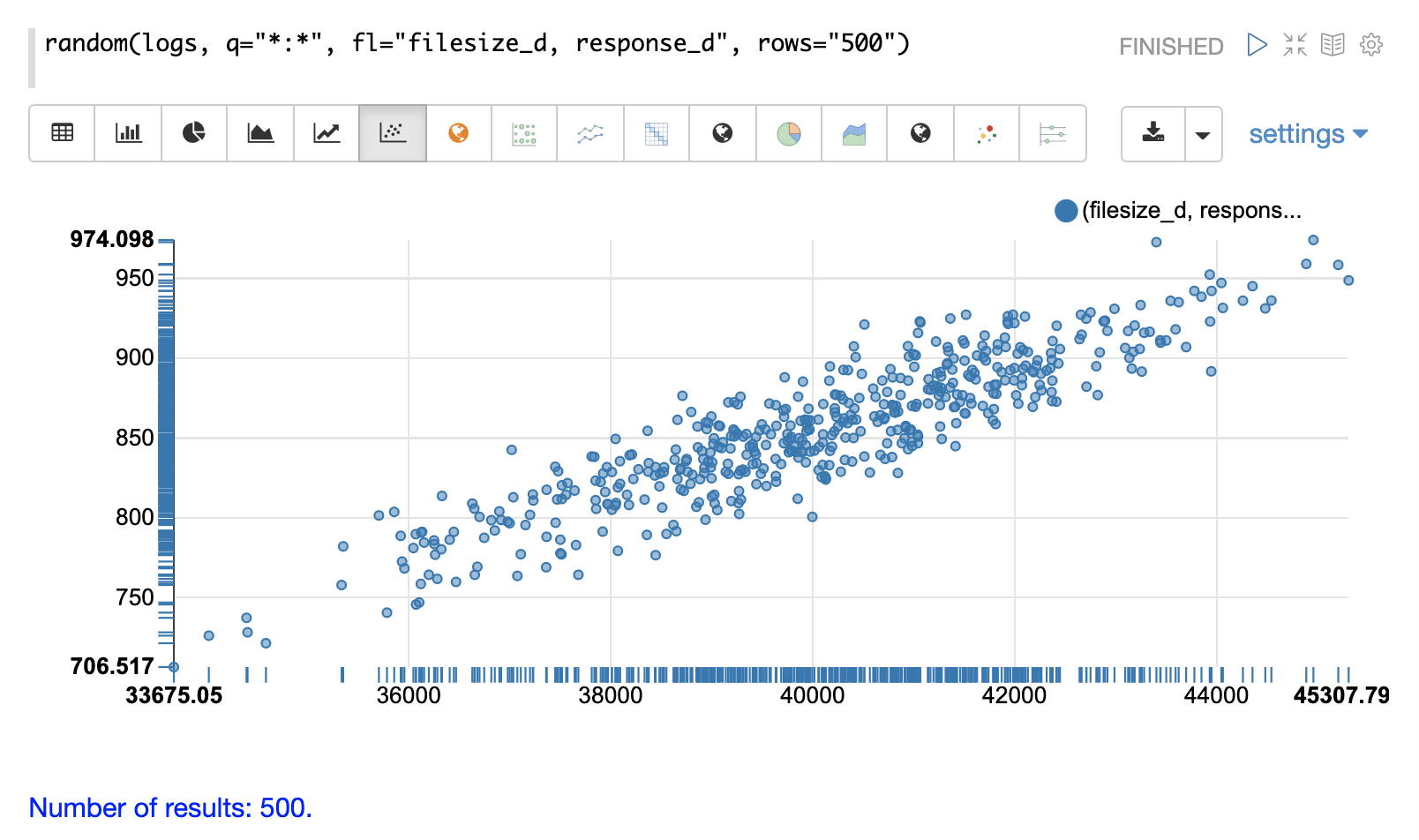
次の例では、random関数にパラメータが追加されています。フィールドリスト(fl)は、各サンプルで返すフィールドとしてfilesize_dとresponse_dを指定するようになりました。qとrowsパラメータはデフォルトと同じですが、これらのパラメータの設定方法の例として含まれています。
x軸にfilesize_d、y軸にresponse_dをプロットすることで、2つの変数の間の関係を調査し始めることができます。
散布図を調べることで、以下の情報を得ることができます。
-
filesize_dが増加すると、response_dも増加する傾向があります。 -
この関係は線形に見えるため、データを通る直線を当てはめて関係をモデル化することができます。
-
点は、中央を通る直線に沿ってより密に集まり、線から離れるにつれて密度が低くなります。
-
各
filesize_d点でのデータの分散は、かなり一貫しているようです。これは、予測モデルの予測範囲全体で誤差が一定であることを意味します。
集計
集計は、大規模なデータセットを要約し、データ内のパターン、トレンド、相関関係を明らかにするための強力な統計ツールです。集計は視覚化にも強力なツールであり、さらなる統計分析のためのデータセットを提供します。
stats
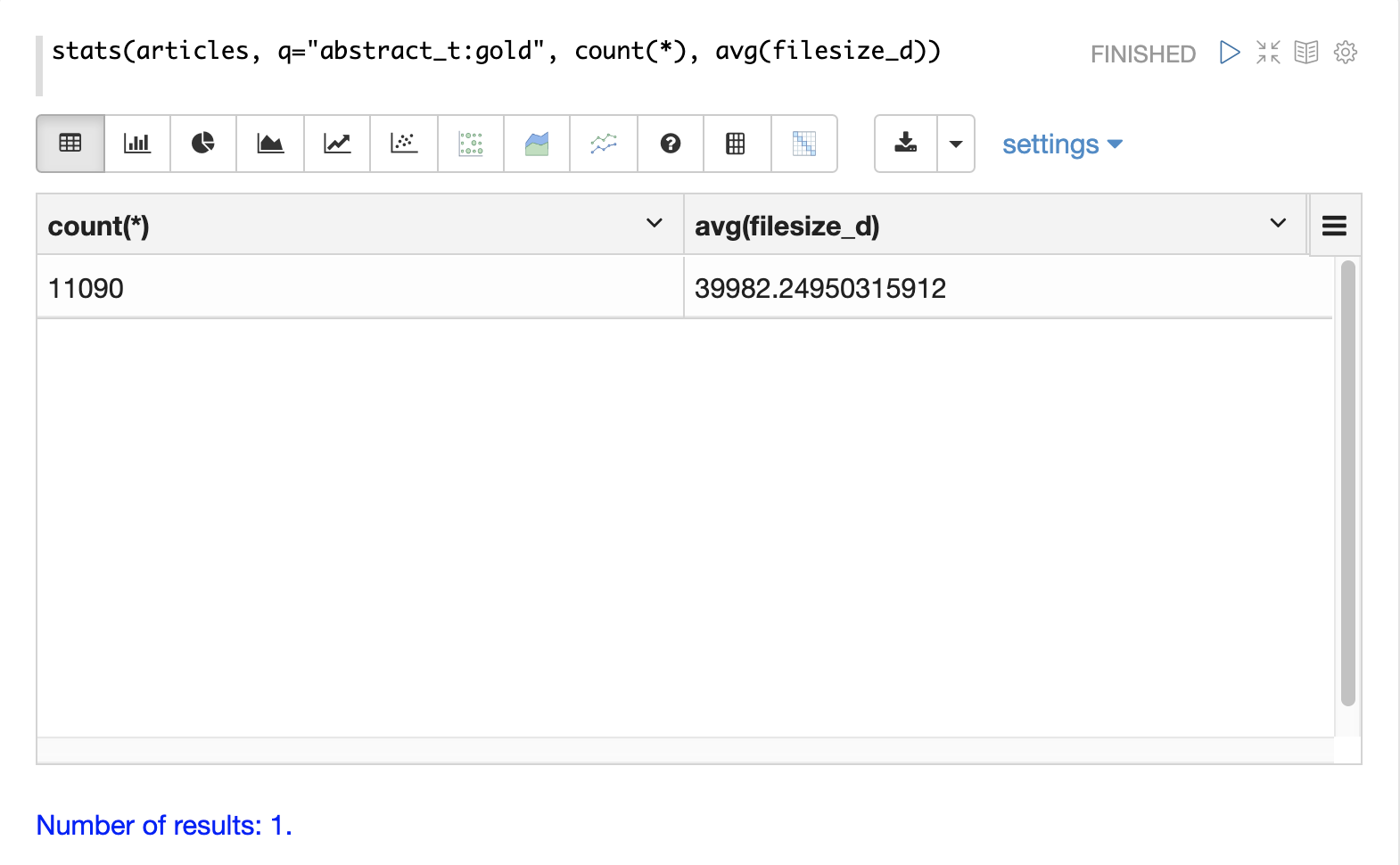
最も単純な集計はstats関数です。stats関数は、クエリに一致する結果セット全体に対して集計を計算します。stats関数は、count(*)、sum、min、max、avgといった集計関数をサポートしています。任意の数と組み合わせの統計を、単一の関数呼び出しで計算できます。
stats関数は、Zeppelin-Solrでテーブルとして視覚化できます。以下の例では、結果セットに対して2つの統計が計算され、テーブルに表示されます。
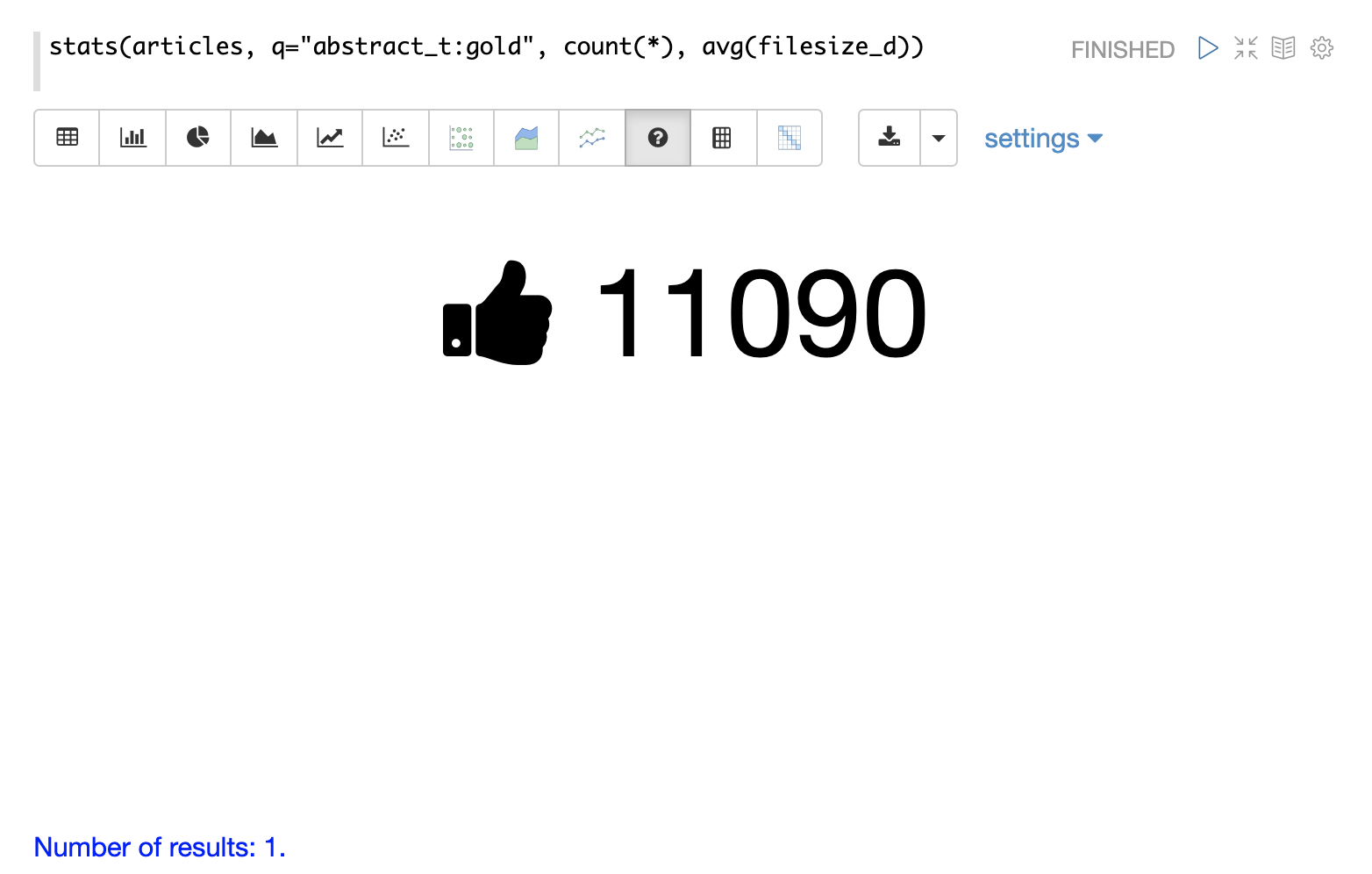
stats関数は、重要な数値を強調表示するために使用される**数値**視覚化を使用して視覚化することもできます。以下の例は、count(*)集計を数値視覚化で表示したものです。
facet
facet関数は、SQLのGROUP BY集計と同様の動作をする単一および多次元集計を実行します。内部的には、facet関数は集計をSolrのJSON Facet APIにプッシュダウンして、高速な分散実行を実現します。
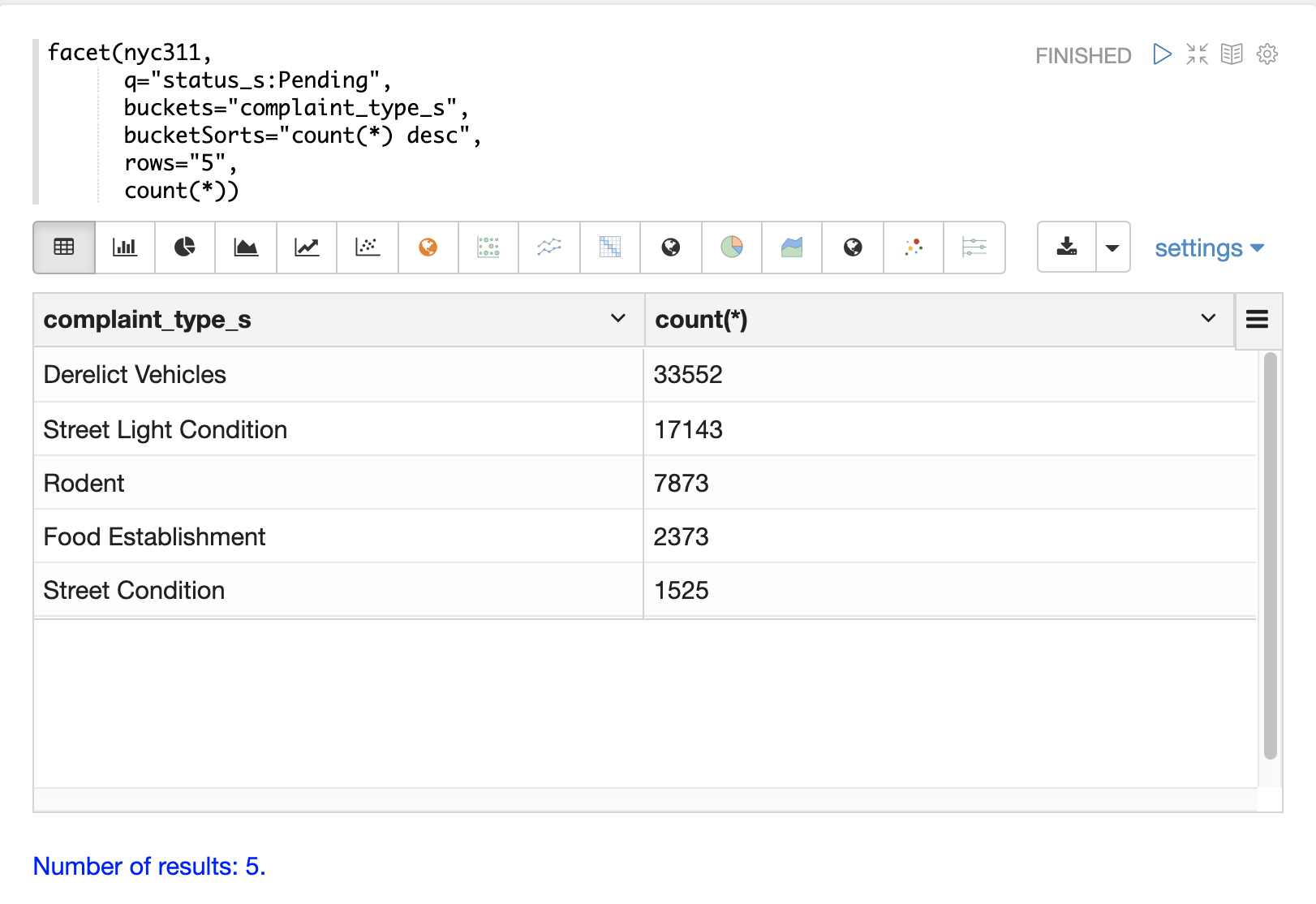
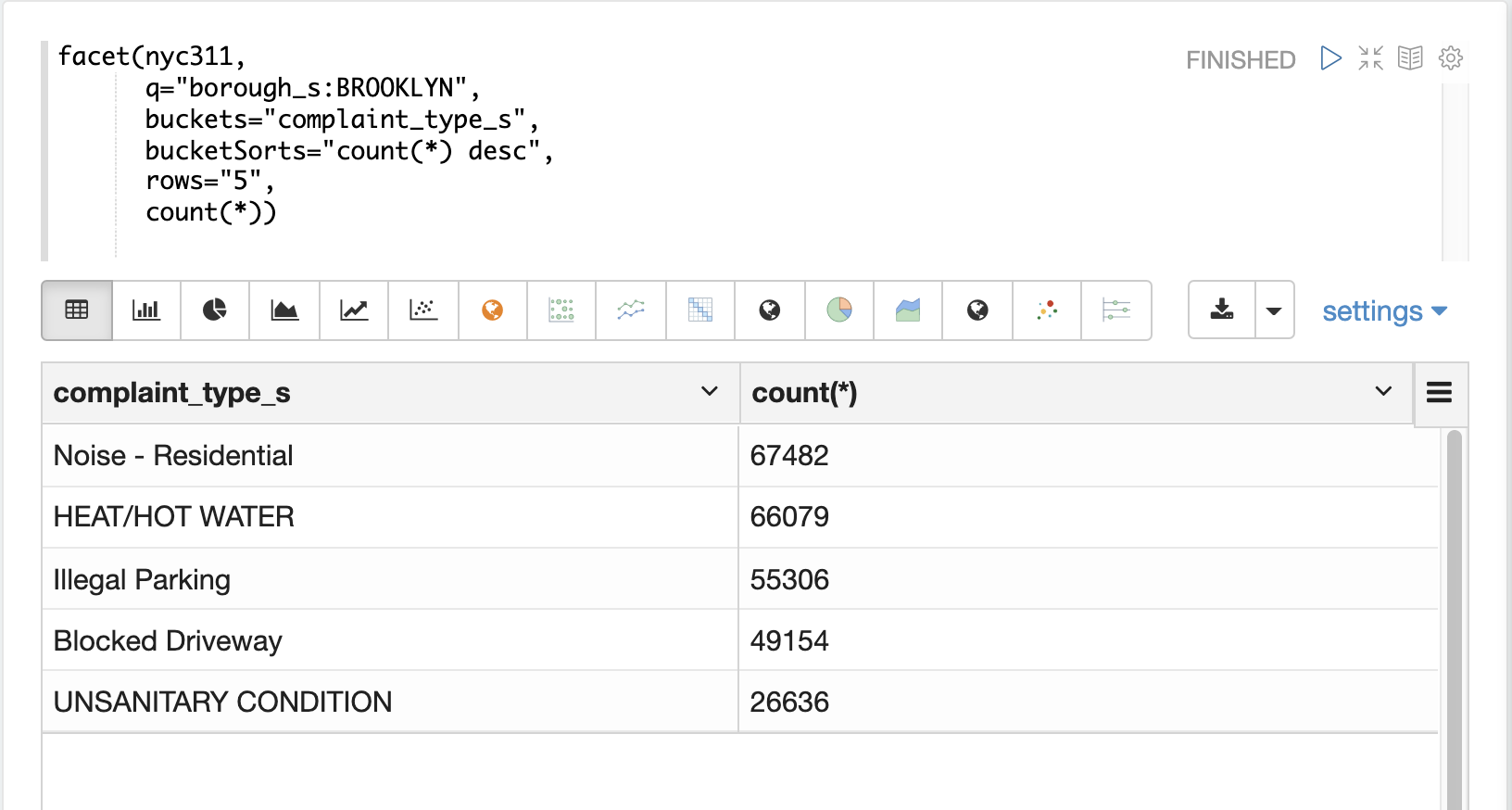
以下の例は、nyc311(NYC苦情)データセットから単一寸法の集計を実行しています。集計は、ステータスが**保留中**のレコードについて、**件数**による上位5つの**苦情の種類**を返します。結果はZeppelin-Solrでテーブルに表示されます。
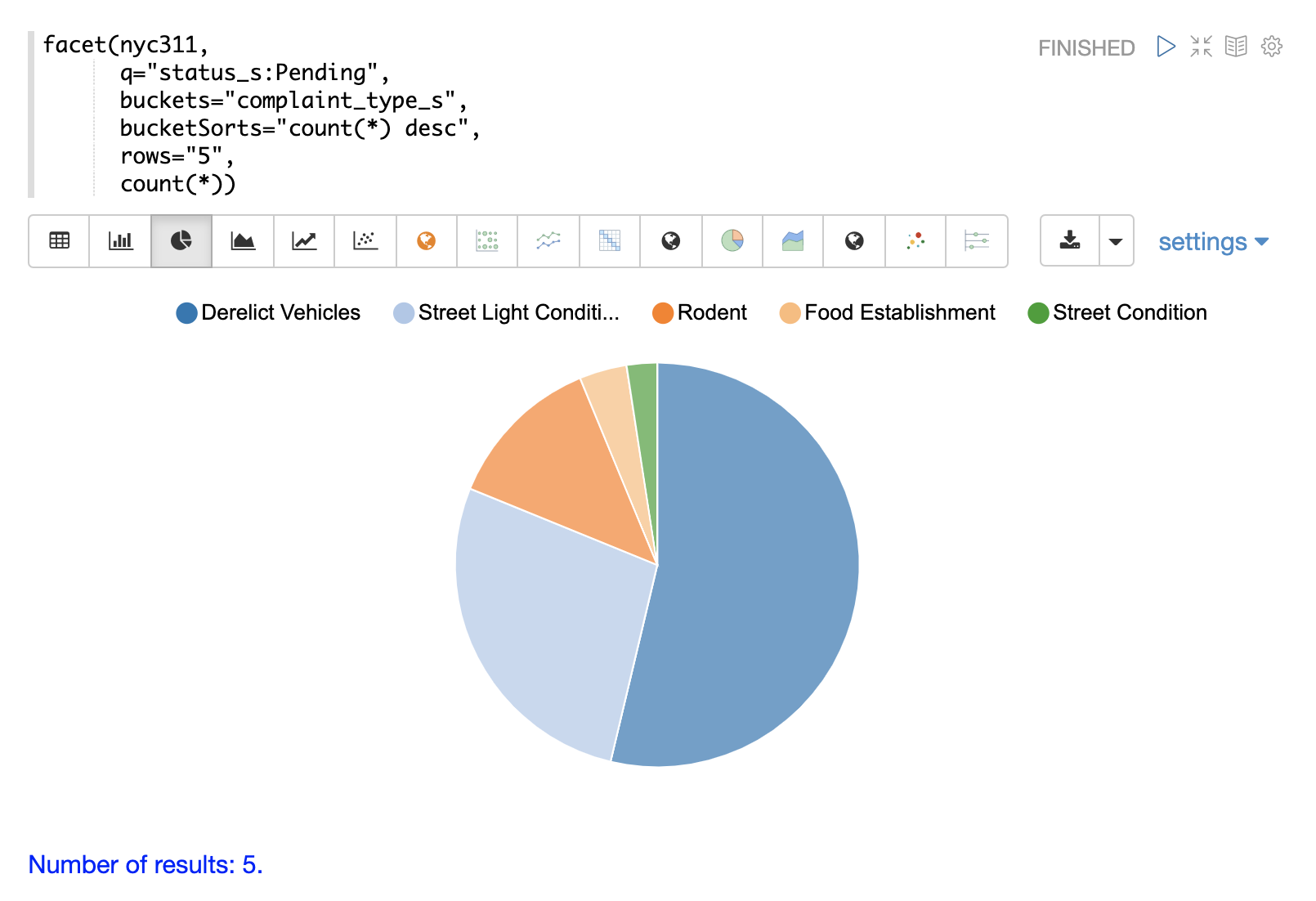
以下の例は、円グラフを使用して視覚化されたテーブルを示しています。
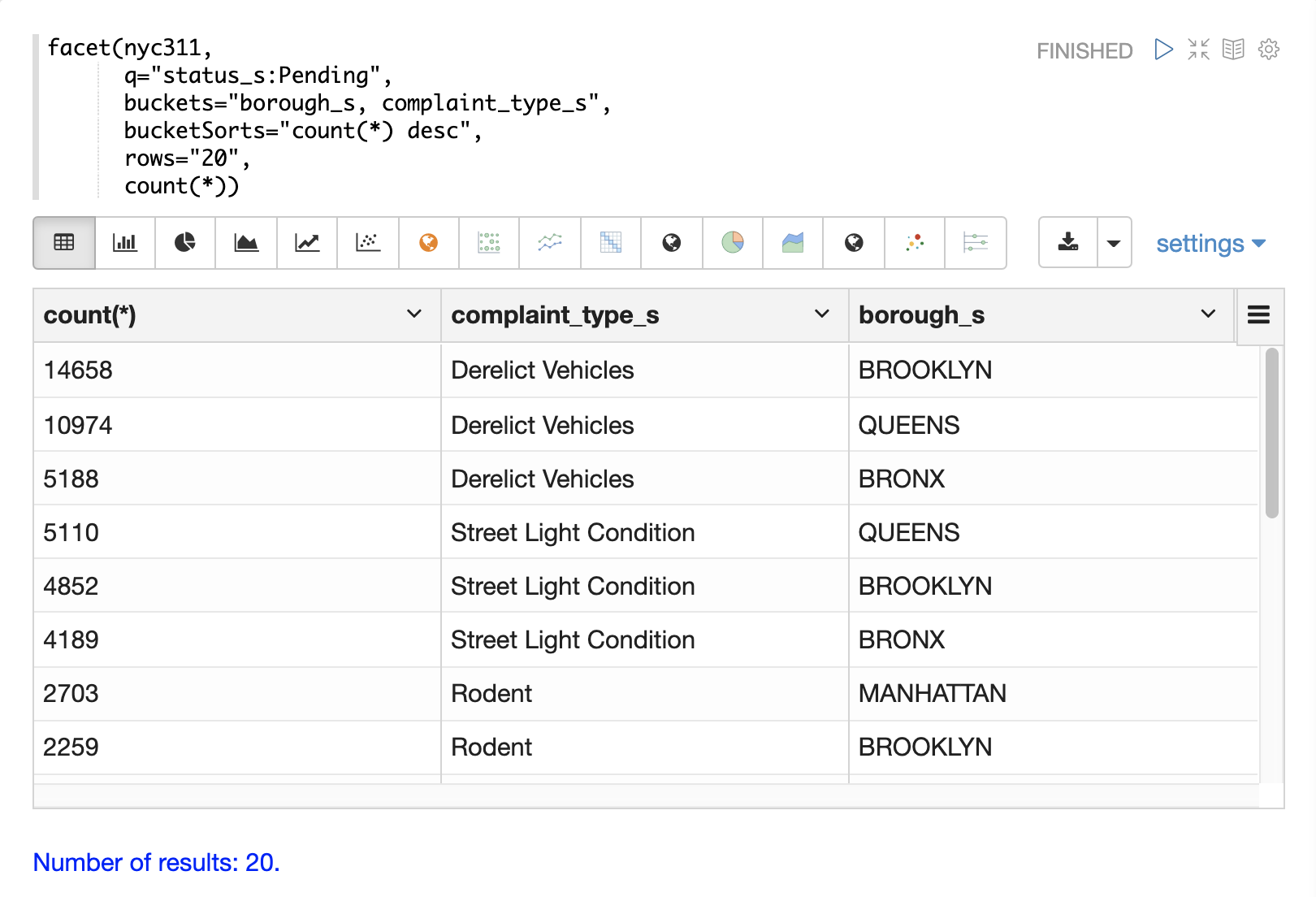
次の例は、多次元集計を示しています。bucketsパラメータには、borough_sとcomplaint_type_sの2つの次元が含まれていることに注意してください。これにより、件数による行政区と苦情の種類の上位20個の組み合わせが返されます。
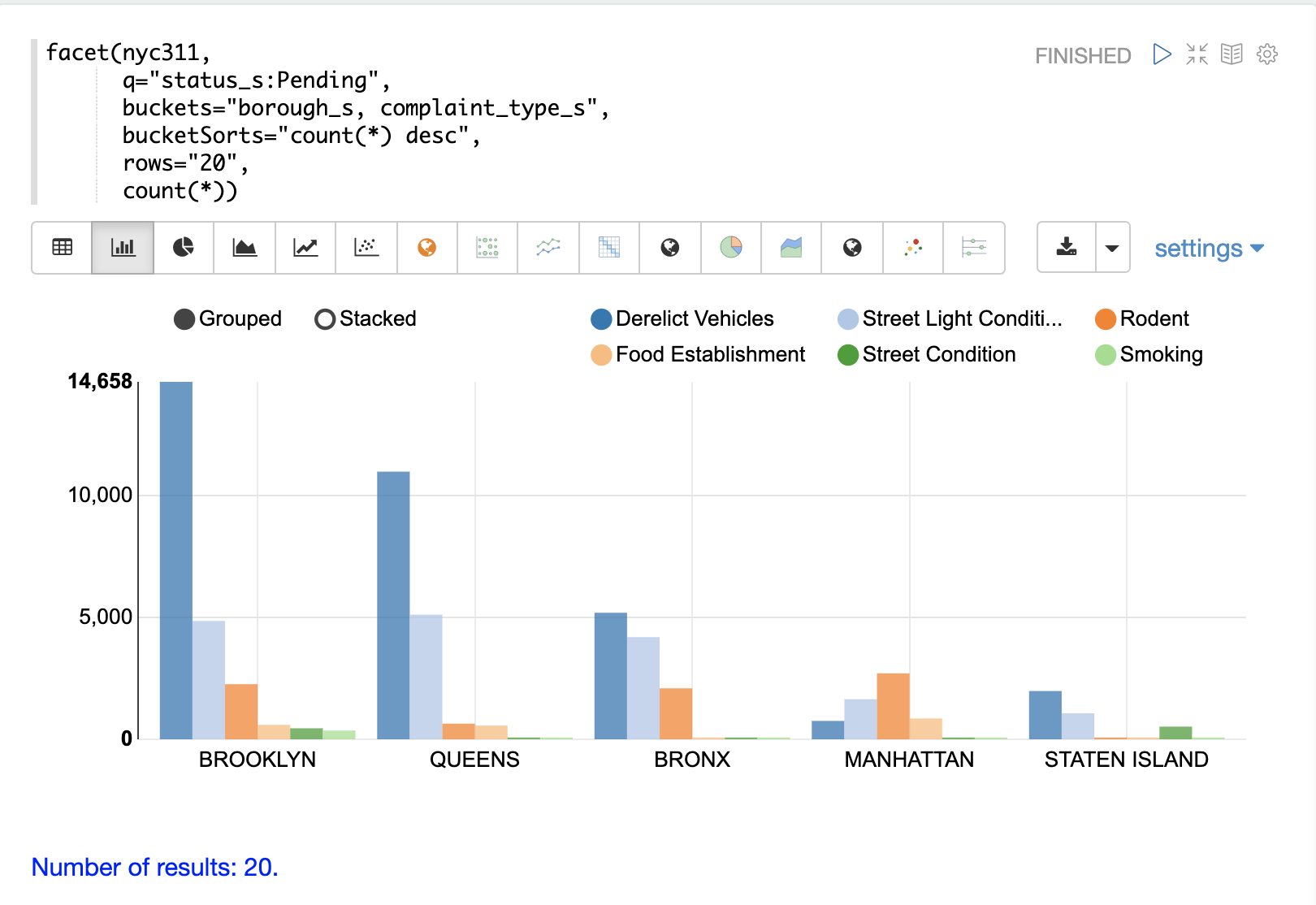
以下の例は、グループ化された棒グラフとして視覚化された多次元集計を示しています。
facet関数は、count(*)、sum、avg、min、maxといった集計関数の任意の組み合わせをサポートしています。
facet2D
facet2D関数は、ヒートマップとして視覚化したり、行列にピボットして機械学習関数で操作したりできる2次元集計を実行します。
facet2D関数は、各次元の固有ファセットの数を制御しない2次元facet関数とは構文と動作が異なります。facet2D関数は、**x**次元と**y**次元の固有ファセットの数を制御するdimensionsパラメータを持っています。
以下の例は、facet2D関数の出力を視覚化しています。この例では、facet2Dは上位5つの行政区と、各行政区の上位5つの苦情の種類を返します。その後、出力はヒートマップとして視覚化されます。
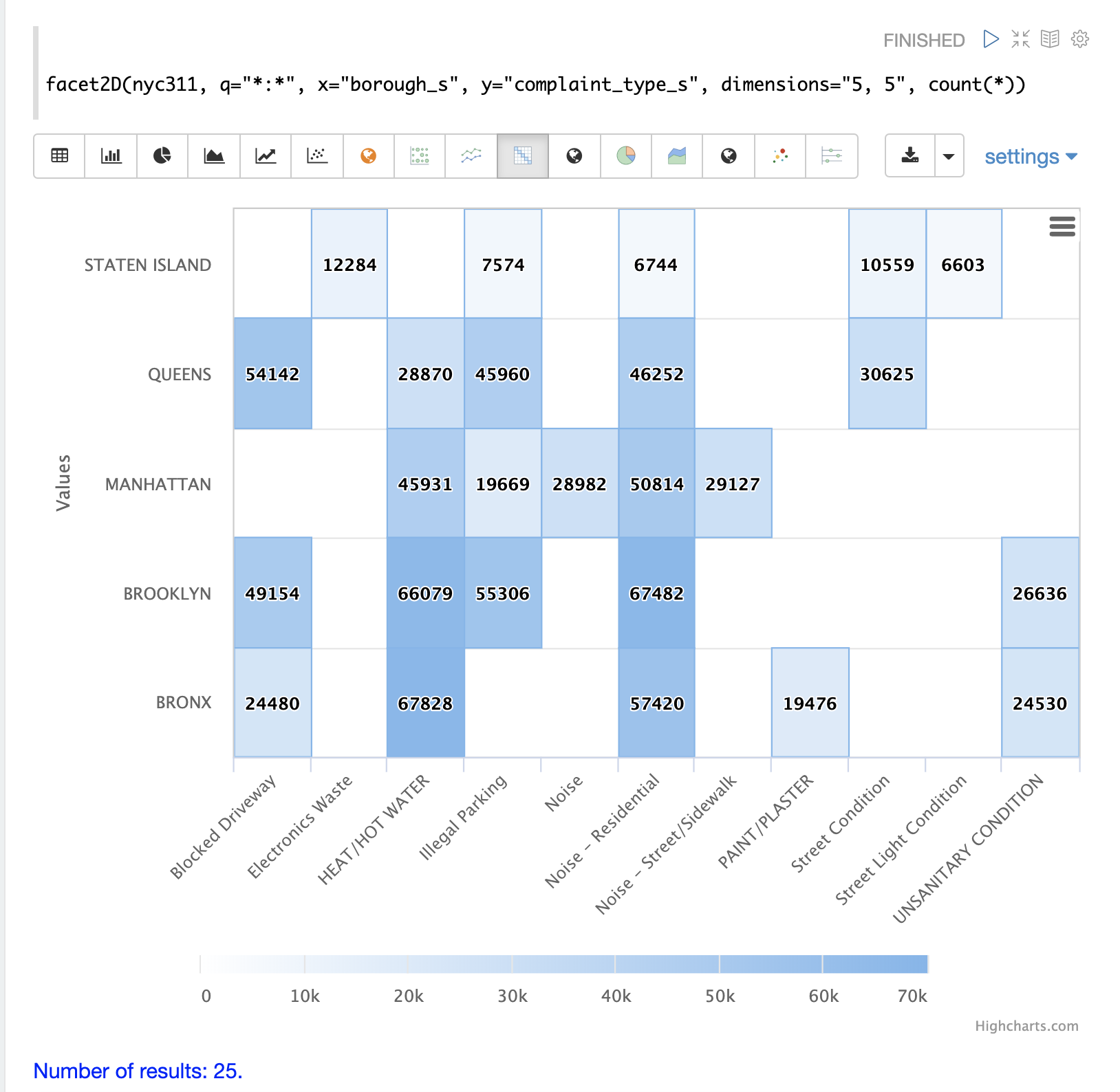
facet2D関数は、count(*)、sum、avg、min、maxといった集計関数のいずれかをサポートしています。
timeseries
timeseries関数は、Solrの組み込みファセットと日付数学機能を利用した、高速な分散型時系列集計を実行します。
以下の例は、日々の株価データのコレクションに対して月次時系列集計を実行しています。この例では、特定の日付範囲内の株価シンボル**amzn**について、平均月次終値が計算されます。
timeseries関数の出力は、折れ線グラフで視覚化されます。
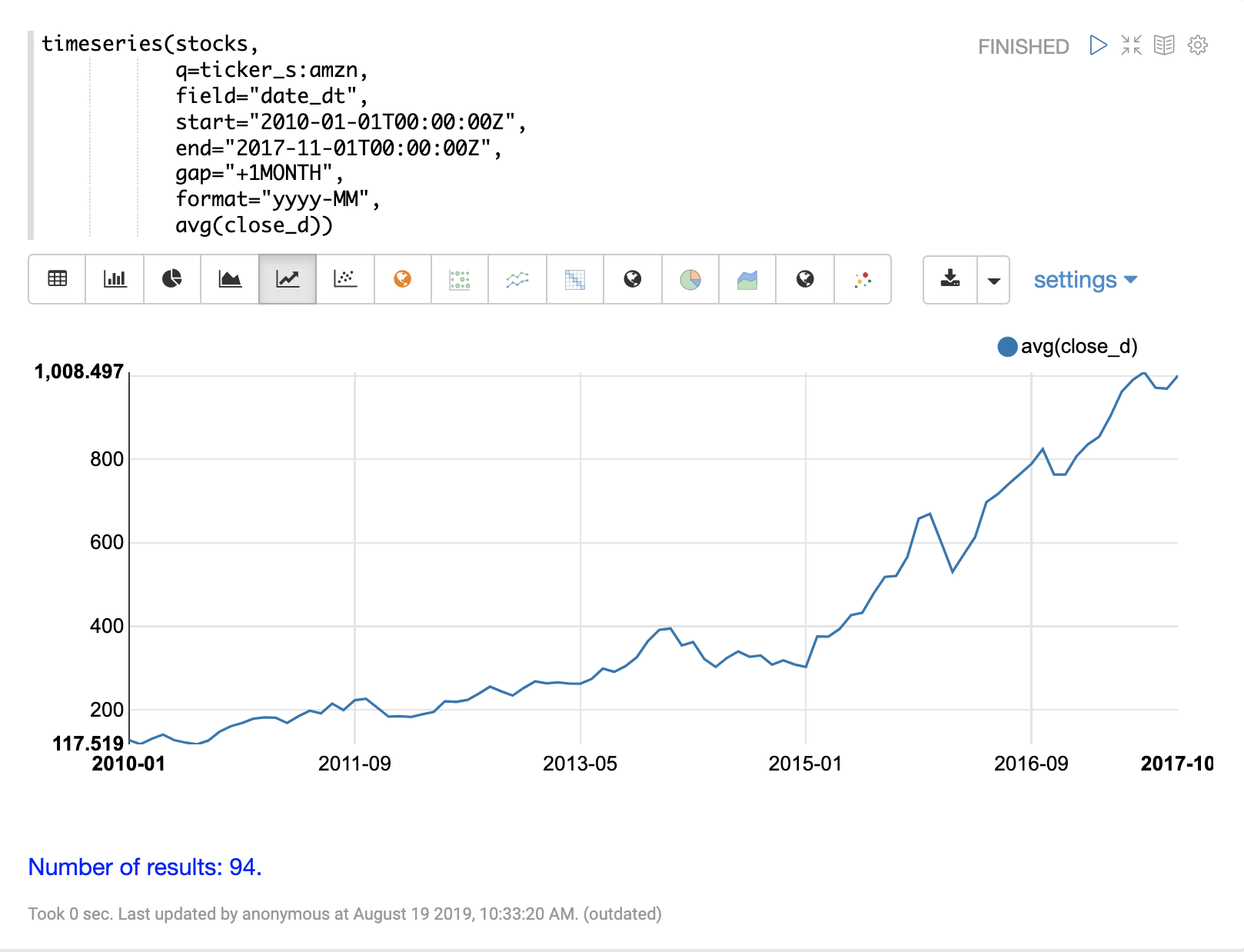
timeseries関数は、count(*)、sum、avg、min、maxといった集計関数の任意の組み合わせをサポートしています。
significantTerms
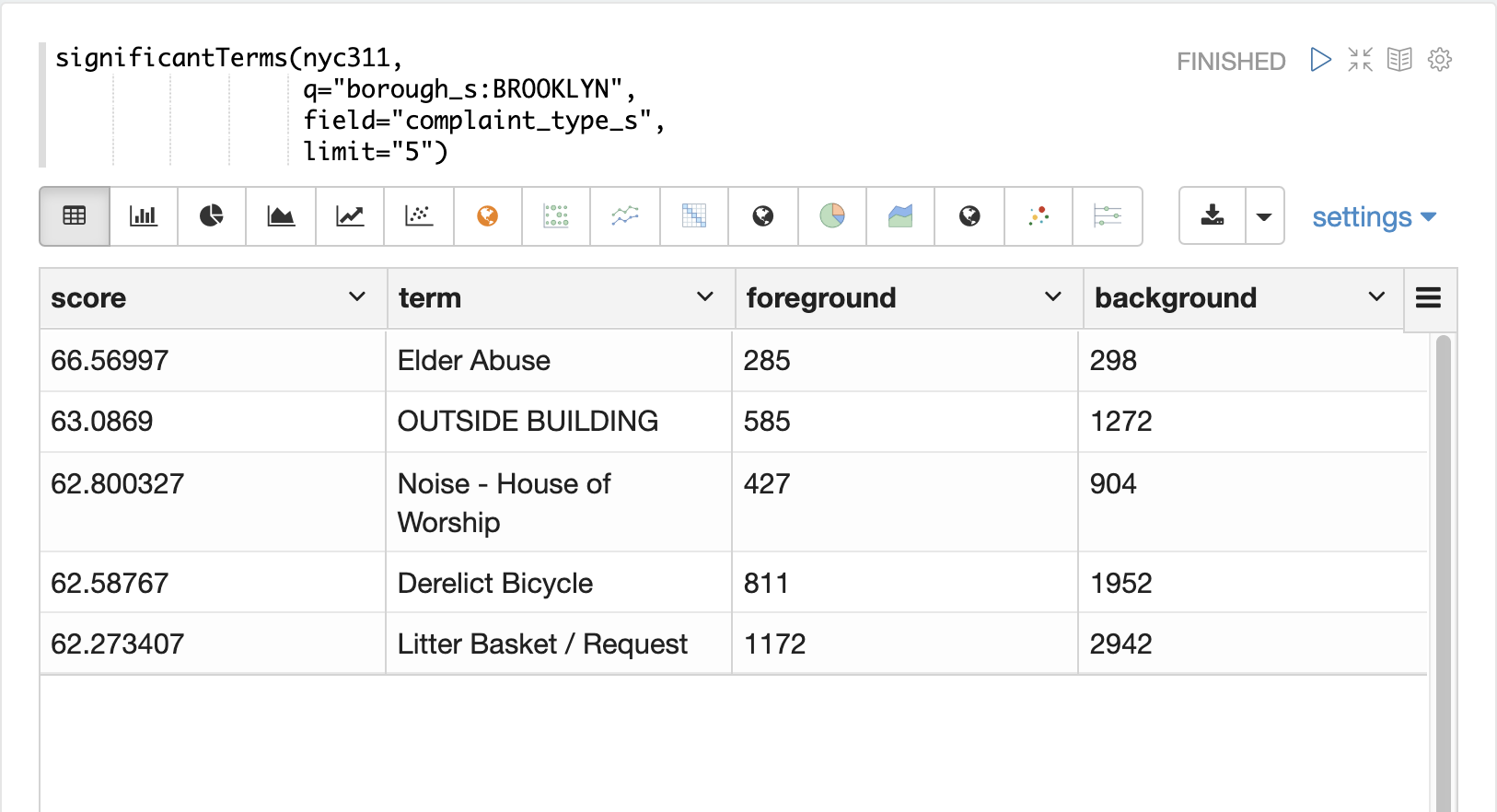
significantTerms関数はコレクションをクエリしますが、ドキュメントを返す代わりに、結果セット内のドキュメントに見つかった重要な用語を返します。この関数は、結果セット内での出現頻度と、コーパス全体での出現頻度の低さを基に用語をスコアリングします。significantTerms関数は、用語、スコア、フォアグラウンドカウント、バックグラウンドカウントを含むタプルを各用語に対して出力します。フォアグラウンドカウントは、用語が結果セット内のドキュメントに出現する回数です。バックグラウンドカウントは、用語がコーパス全体に出現するドキュメントの数です。フォアグラウンドカウントとバックグラウンドカウントはコレクション全体でグローバルです。
significantTerms関数は、他の種類の集計からは得られない洞察を提供することがよくあります。以下の例は、facet関数とsignificantTerms関数の違いを示しています。
最初の例では、facet関数はブルックリンの上位5つの苦情の種類を集計します。これはブルックリンで最も一般的な5つの苦情の種類を返しますが、これらの用語が他の行政区よりもブルックリンで頻繁に出現することが明確ではありません。
次の例では、significantTerms関数はブルックリン区のcomplaint_type_sフィールドの上位5つの重要な用語を返します。最もスコアの高い用語である「高齢者虐待」は、フォアグラウンドカウントが285、バックグラウンドカウントが298です。これは、データセット全体で298件の高齢者虐待の苦情があり、そのうち285件がブルックリンにあったことを意味します。これは、高齢者虐待の苦情が他の行政区よりもブルックリンではるかに高い発生率であることを示しています。
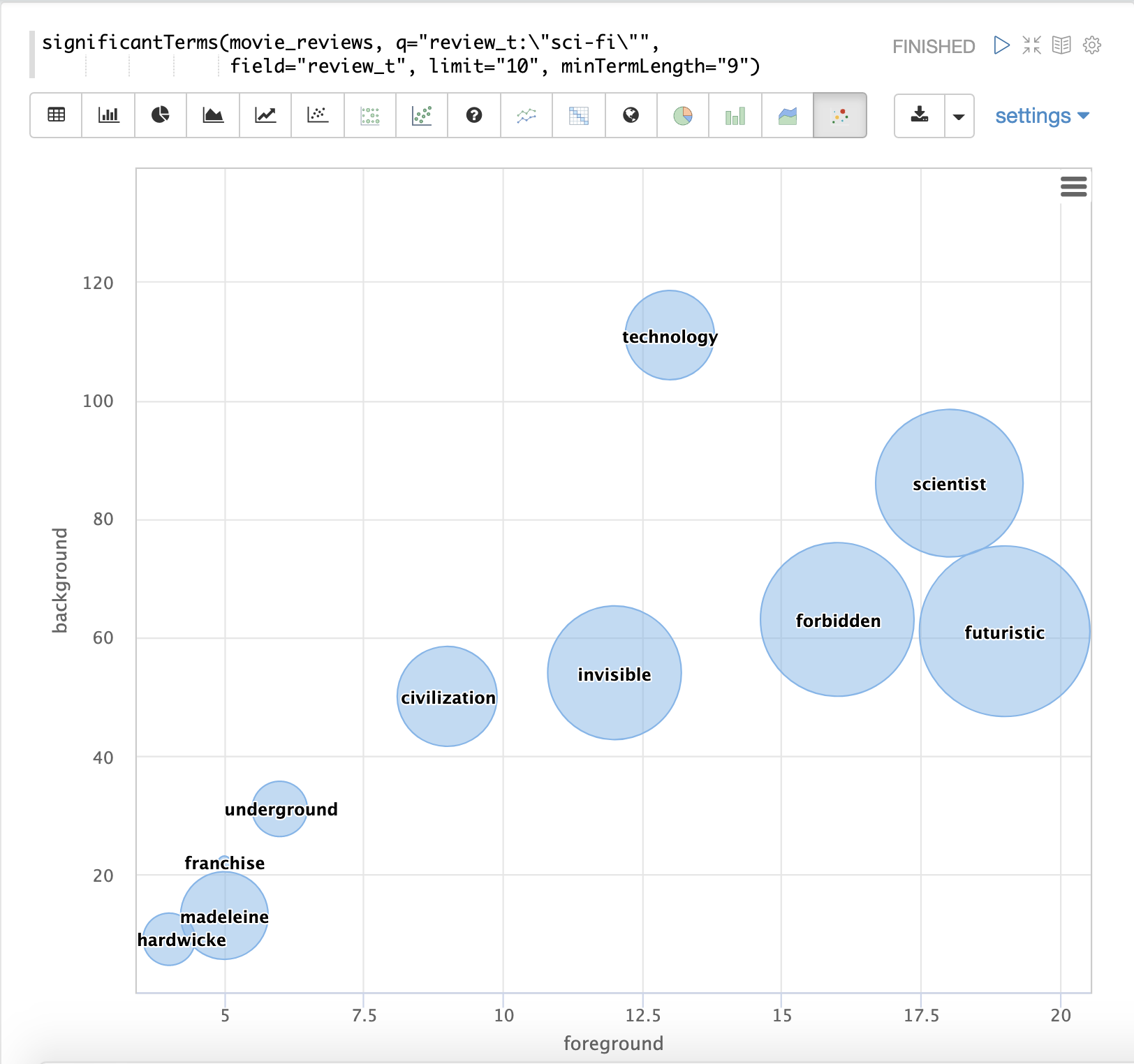
最後の例は、映画レビューを含むテキストフィールドからのsignificantTermsの視覚化を示しています。「SF」というフレーズを含む映画レビューに出現する重要な用語を示しています。
結果は、x軸に**フォアグラウンド**カウント、y軸に**バックグラウンド**カウントをプロットしたバブルチャートで視覚化されます。各用語は、**スコア**でサイズが調整されたバブルで表示されます。
nodes
nodes関数は、グラフの幅優先探索中にノードの集計を実行します。この関数は、グラフ探索セクションで詳細に説明されています。この例では、nodes式を使用して時系列グラフ内の相関ノードを見つけることに重点を置きます。
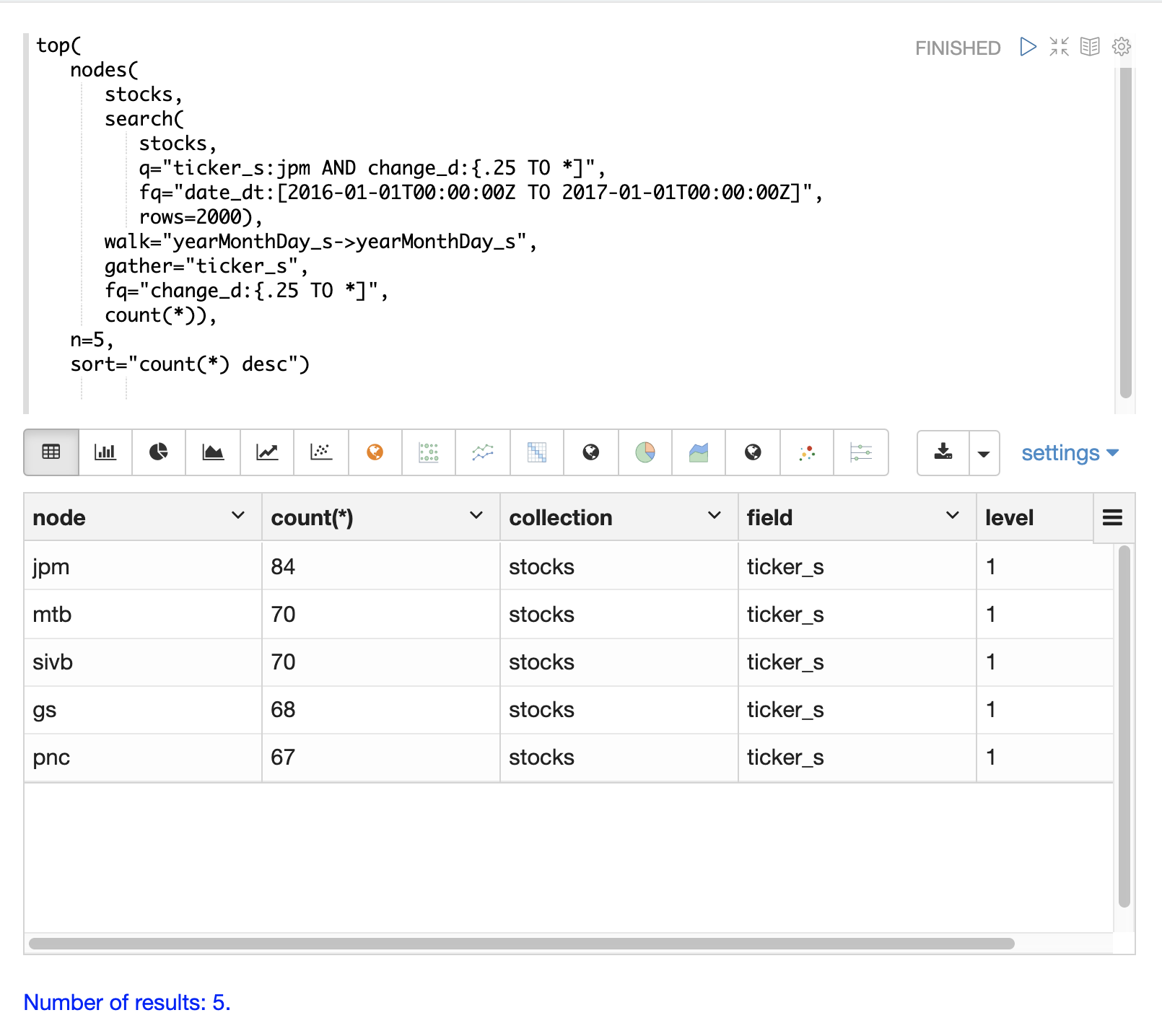
以下の例は、日々の変動が**jpm**(JPモルガン)の株価と相関する傾向のある株価シンボルを見つけます。
内部のsearch式は、株価シンボルが**jpm**であり、change_dフィールド(株価の日々の変動)が0.25より大きい特定の日付範囲のレコードを見つけます。この検索は、一致するレコードの年、月、日の文字列表現であるyearMonthDay_sを含む、インデックス内のすべてのフィールドを返します。
nodes関数はsearch関数をラップしてその結果を操作します。walkパラメータは、検索結果のフィールドをインデックス内のフィールドにマッピングします。この場合、yearMonthDay_sは同じインデックスのyearMonthDay_sフィールドにマッピングされます。これにより、初期検索によって返された同じyearMonthDay_sフィールド値を持つレコードが見つかり、それらの日のすべてのティッカーのレコードが返されます。検索にフィルタークエリが適用され、change_dが0.25より大きい行に検索が絞り込まれます。これにより、一致する日のうち、日々の変動が0.25より大きいすべてのレコードが見つかります。
gatherパラメータは、nodes式に幅優先探索中にticker_sシンボルを収集するように指示します。count(*)パラメータは、ティッカーの出現回数をカウントします。これにより、幅優先探索で各ティッカーが出現する回数がカウントされます。
最後に、top関数は、カウントによって上位5つのティッカーを選択して返します。
以下の結果は、nodesフィールドのティッカーシンボルと各ノードのカウントを示しています。**jpm**が最初に表示されており、この期間中に**jpm**が0.25を超える変動を示した日数が示されています。次のティッカーシンボル(**mtb**、**slvb**、**gs**、**pnc**)は、**jpm**が0.25を超える変動を示した日と同じ日に、0.25を超える変動を示した日数が最も多いシンボルです。
nodes関数は、count(*)、sum、avg、min、maxといった集計関数の任意の組み合わせをサポートしています。