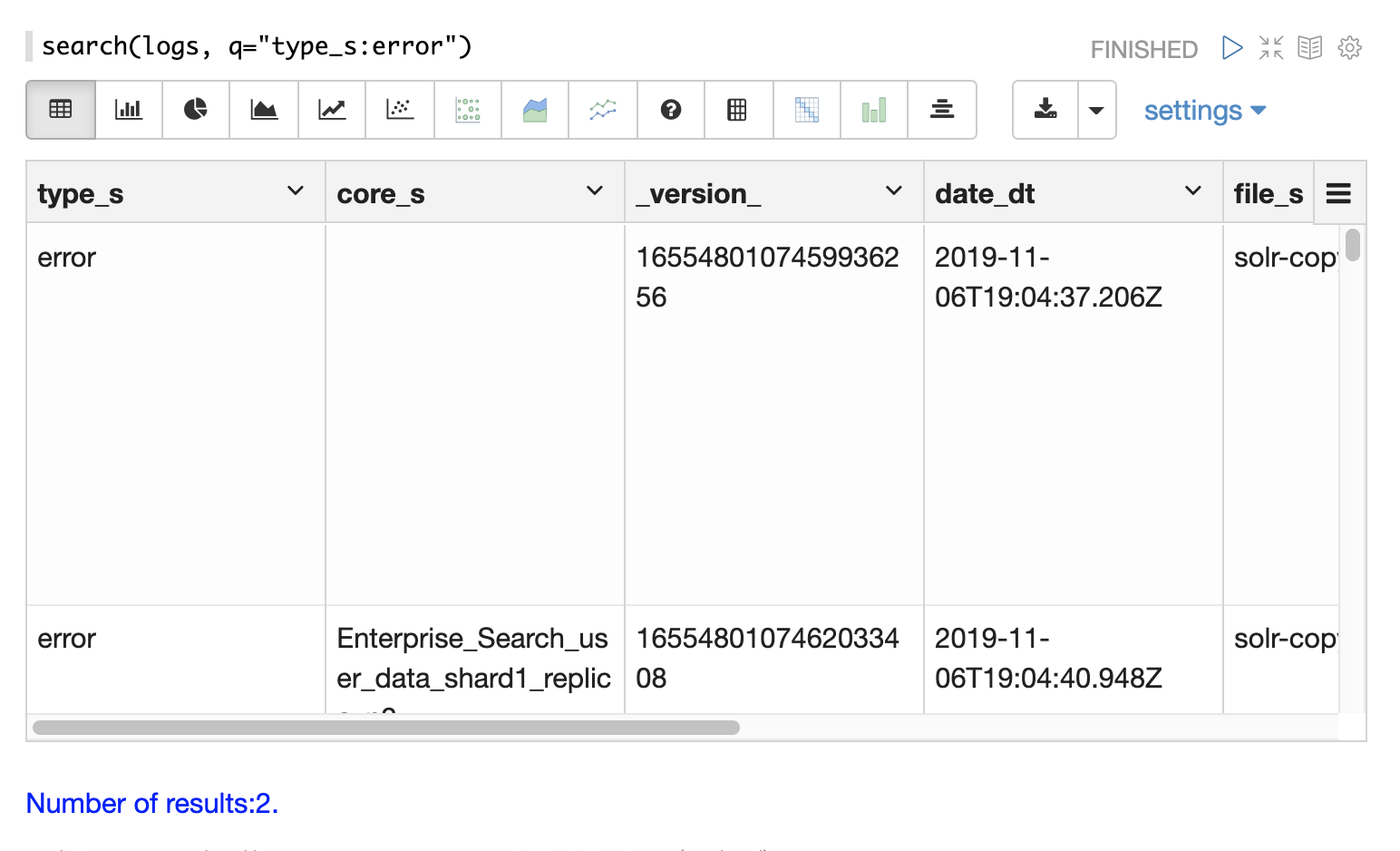
ログ分析
ユーザーガイドのこのセクションでは、Solr ログ分析の概要について説明します。
| これは ストリーミング式と数式のビジュアルガイド の付録です。以下に説明するすべての関数は、ガイドで詳しく説明されています。可視化と Apache Zeppelin の使用方法については、はじめに の章を参照してください。 |
読み込み
標準の Solr ログ形式は、Solr ディストリビューションの bin/ ディレクトリにある bin/solr postlogs コマンドラインツールを使用して Solr インデックスにロードできます。
Postlogs
postlogs コマンドは、Solr のログ形式を読み取り、Solr コレクションにインデックスを作成します。
bin/solr postlogs [オプション]
bin/solr postlogs -help
ヘルスチェックパラメータ
-url <アドレス>-
必須
デフォルト: なし
コレクションのアドレス。例: https://:8983/solr/collection1/。
-rootdir <ディレクトリ>-
必須
デフォルト: なし
ログディレクトリのルートへのファイルパス: このディレクトリ (サブディレクトリを含む) 以下にあるすべてのファイルがインデックス化されます。パスが単一のログファイルを指している場合、そのログファイルのみがロードされます。
例:
bin/solr postlogs --url https://:8983/solr/logs --rootdir /var/logs/solrlogs
上記の例では、/var/logs/solrlogs 以下のすべてのログファイルが、ベース URL https://:8983/solr にある logs コレクションにインデックス化されます。
探索
ログの探索は、多くの場合、ログ分析と可視化の最初のステップです。
使い慣れていないインストール作業を行う場合、探索を使用して、ログに含まれるコレクション、それらのコレクションに含まれるシャードとコア、およびそれらのコレクションに対して実行されている操作の種類を理解できます。
使い慣れた Solr インストールであっても、探索はトラブルシューティング中に非常に重要です。未知のエラーや予期しない管理操作またはインデキシング操作などの予期しない問題が発見されることが多いためです。
サンプリング
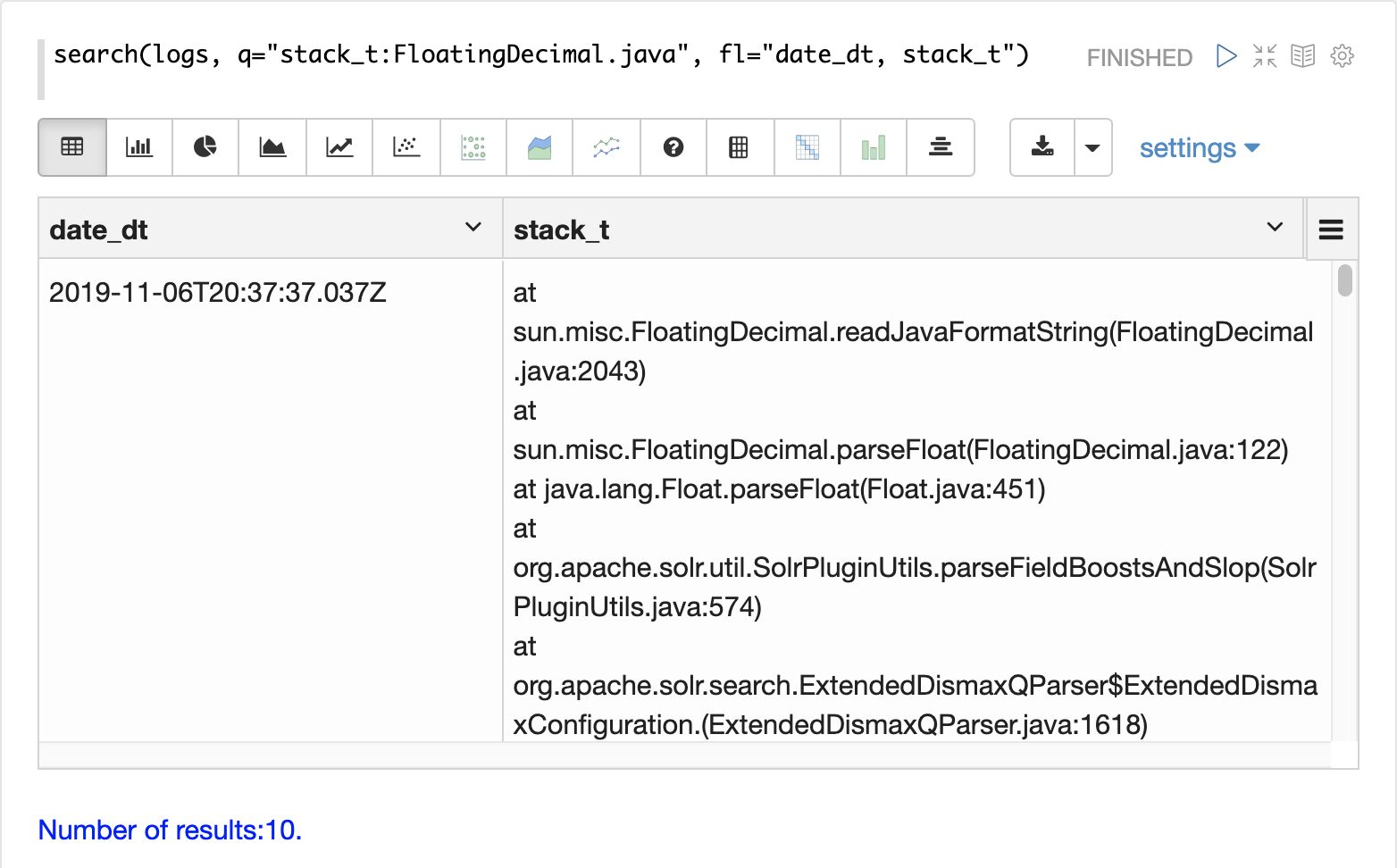
探索の最初のステップは、random 関数を使用して logs コレクションからランダムサンプルを取得することです。
以下の例では、random 関数は、サンプリングするコレクションの名前である 1 つのパラメータで実行されます。
サンプルには、完全なフィールドリストを持つ 500 のランダムレコードが含まれています。このサンプルを見ると、logs コレクションで使用可能な **フィールド** についてすぐに学ぶことができます。
期間
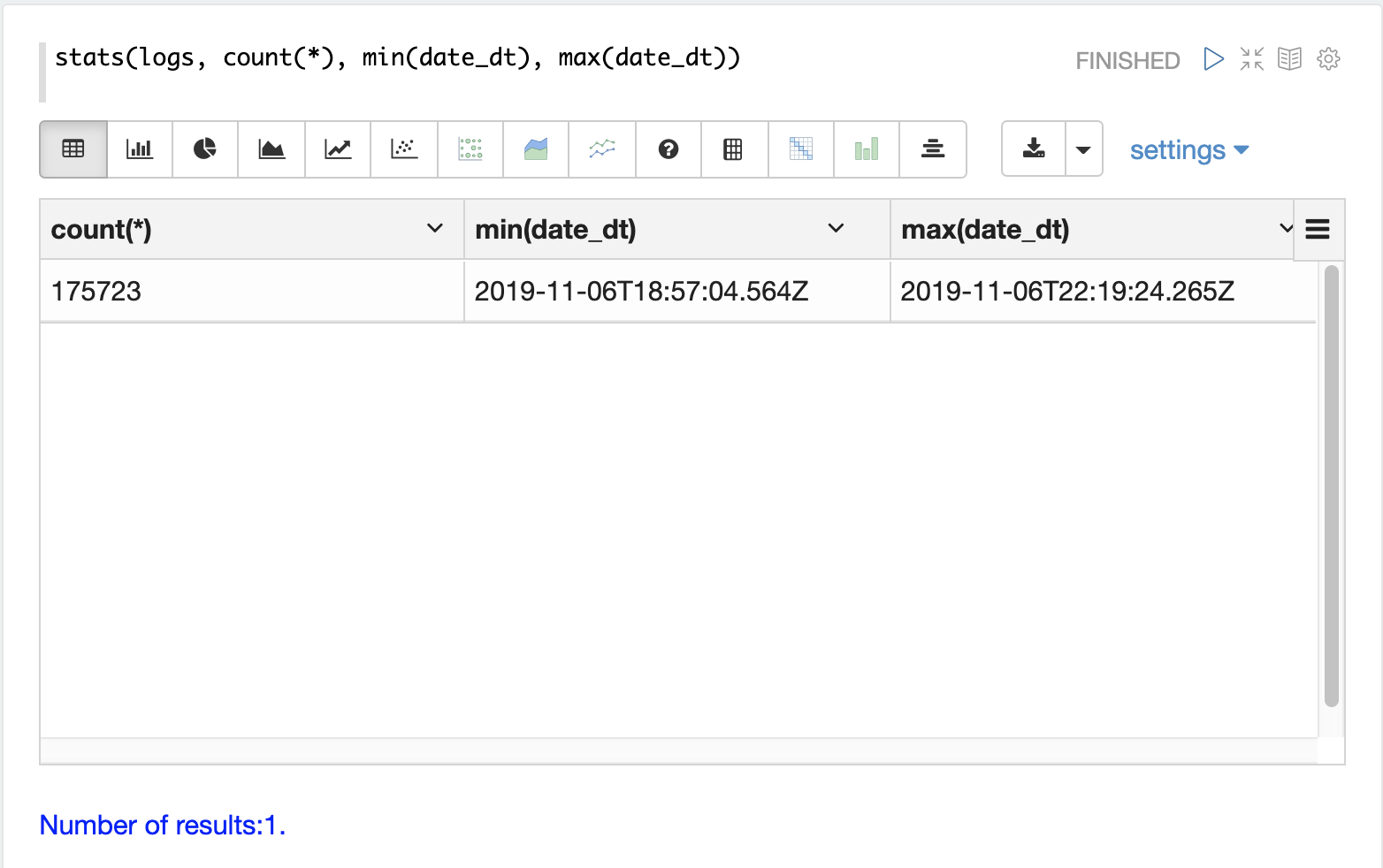
各ログレコードには、date_dt フィールドにタイムスタンプが含まれています。ログがカバーする期間と、インデックス化されたログレコードの数を理解することは、多くの場合役立ちます。
stats 関数を実行すると、この情報を表示できます。
レコードタイプ
インデックスの重要なフィールドの1つは、ログレコードのタイプである type_s フィールドです。
facet 式を使用すると、さまざまなタイプのログレコードと、各タイプのレコードがインデックスにいくつあるかを視覚化できます。
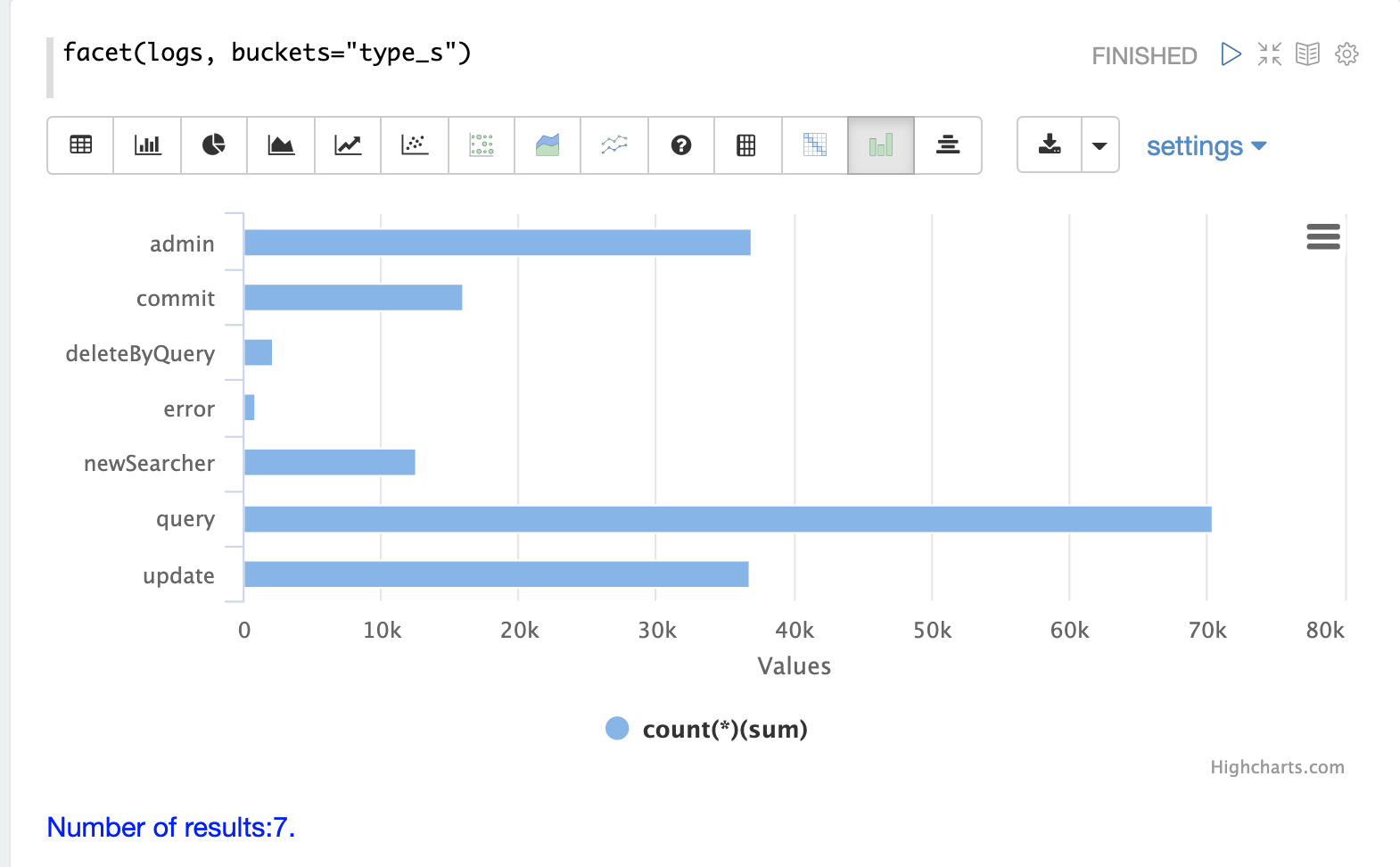
コレクション
もう1つの重要なフィールドは、ログレコードが生成されたコレクションである collection_s フィールドです。
facet 式を使用すると、さまざまなコレクションと、それらが生成するログレコードの数を視覚化できます。
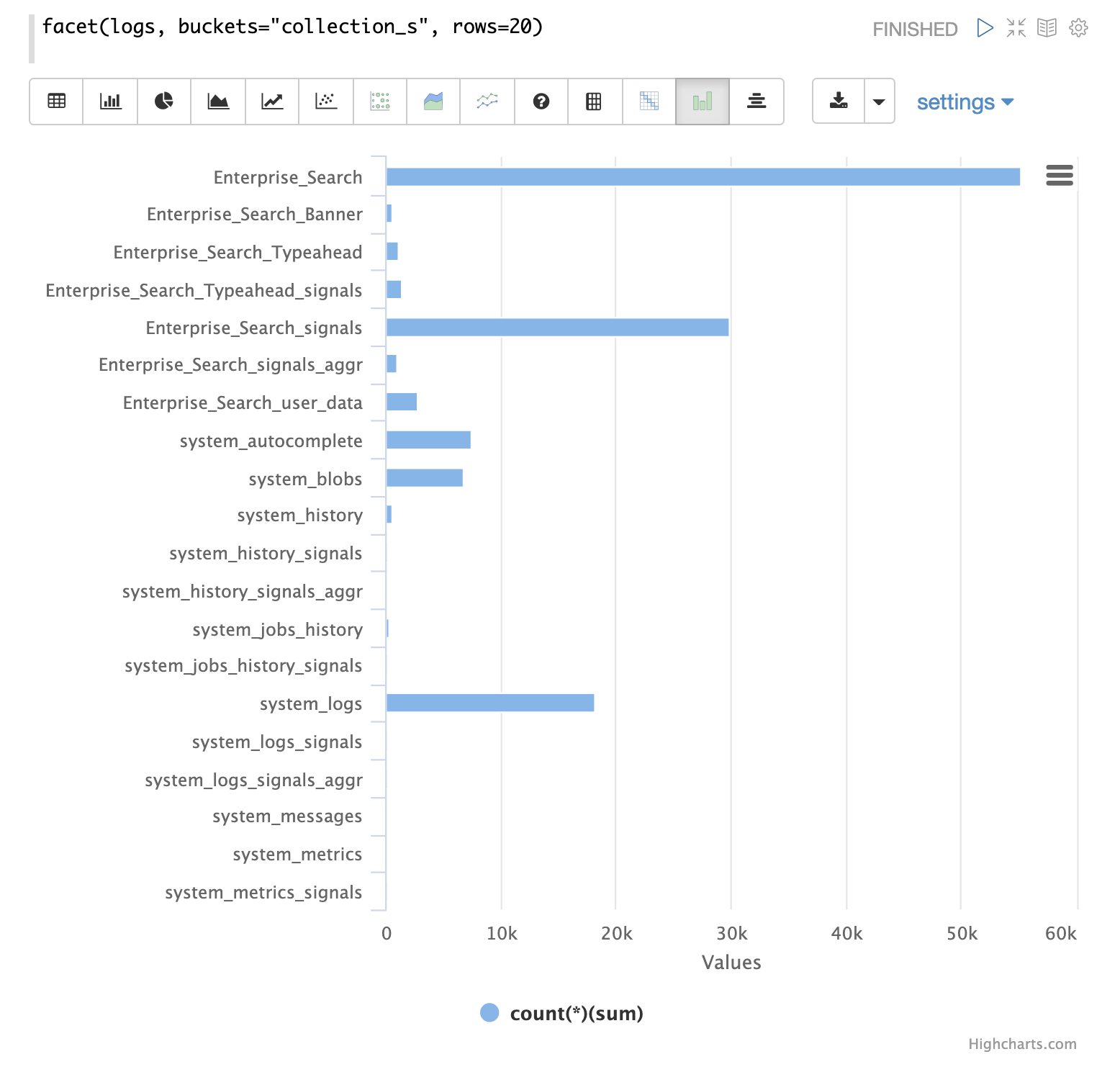
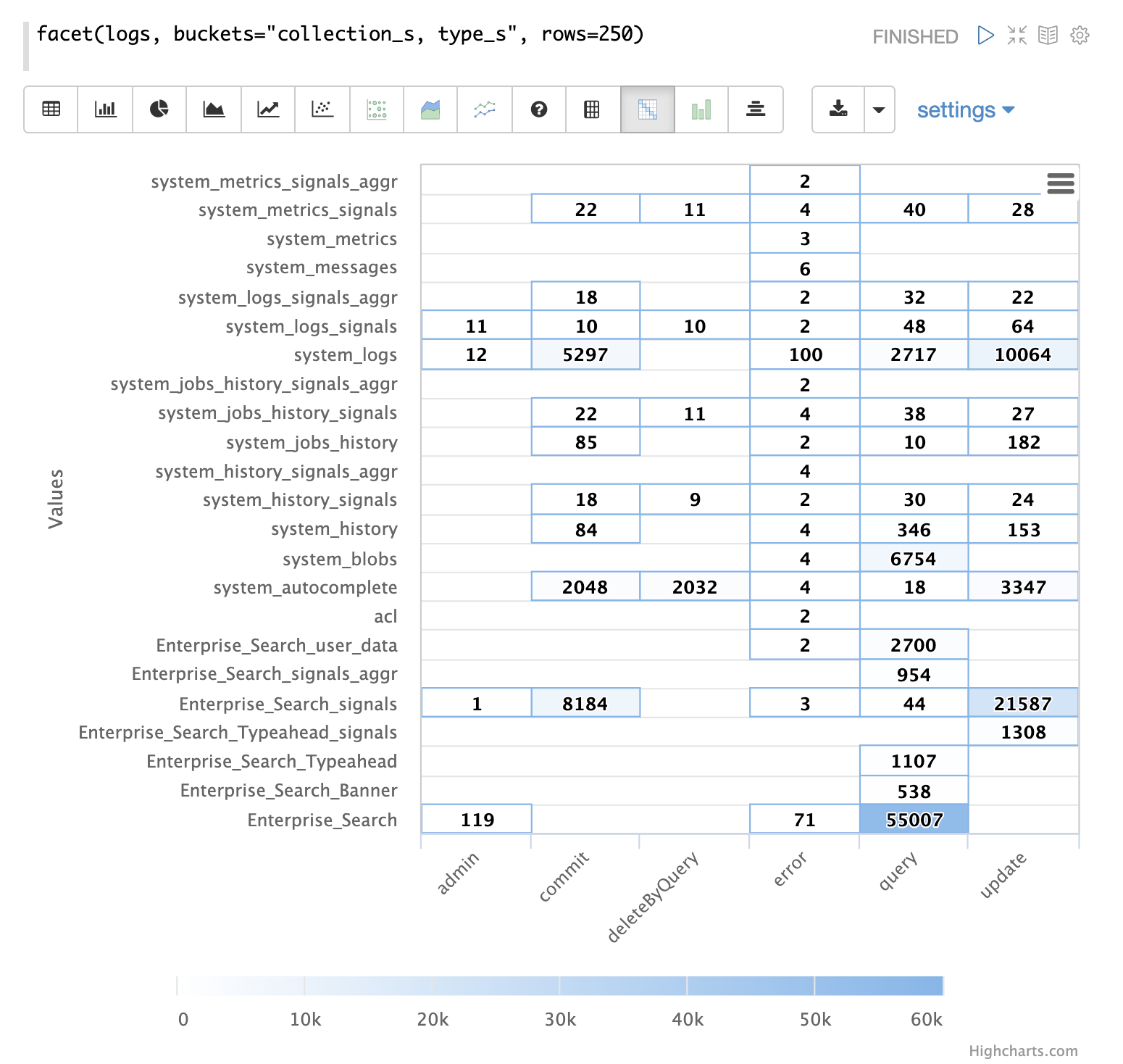
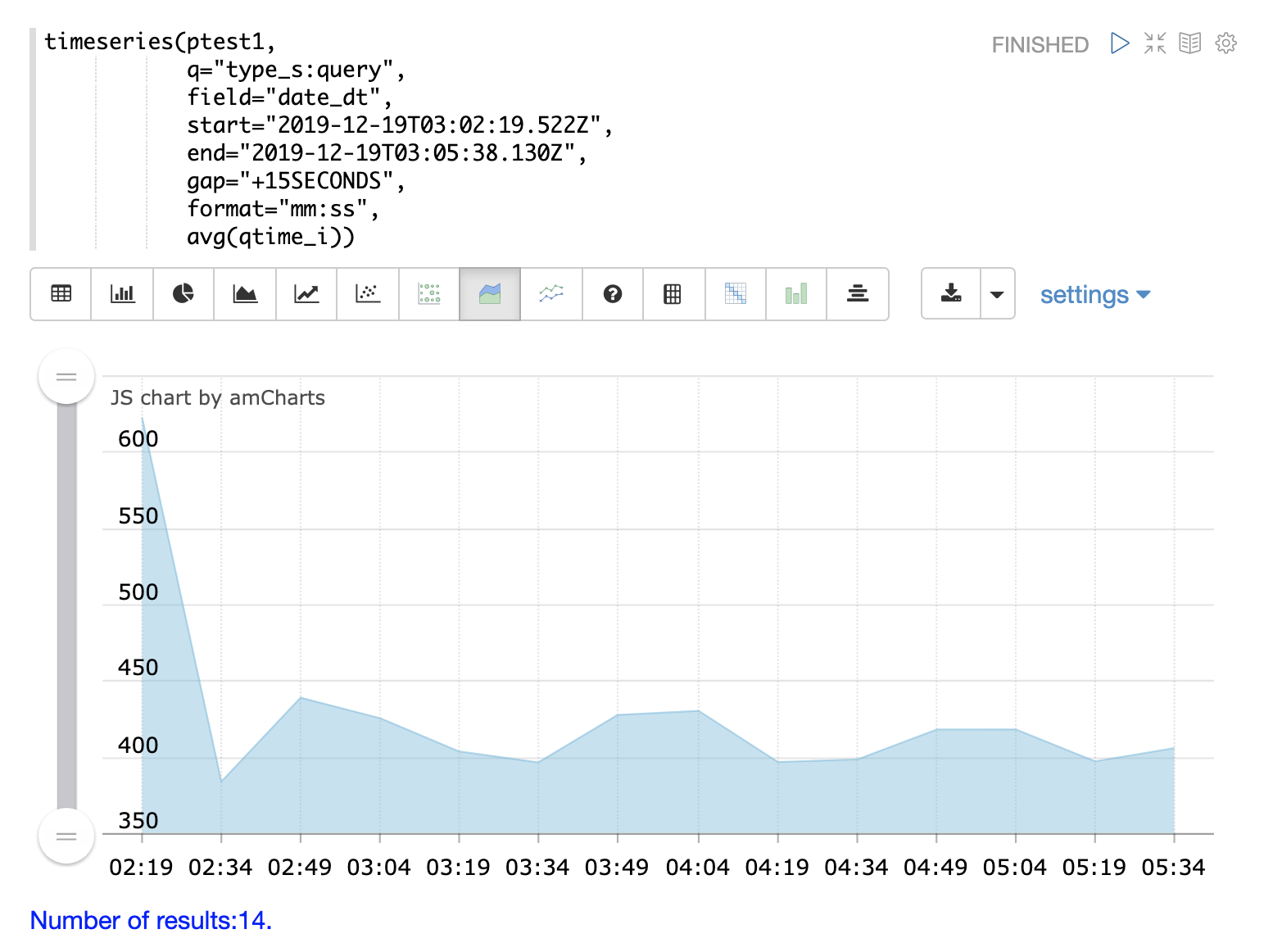
時系列
timeseries 関数を使用すると、ログの特定の期間の時系列を視覚化できます。
以下の例では、時系列を使用して、15秒間隔のログレコード数を視覚化しています。
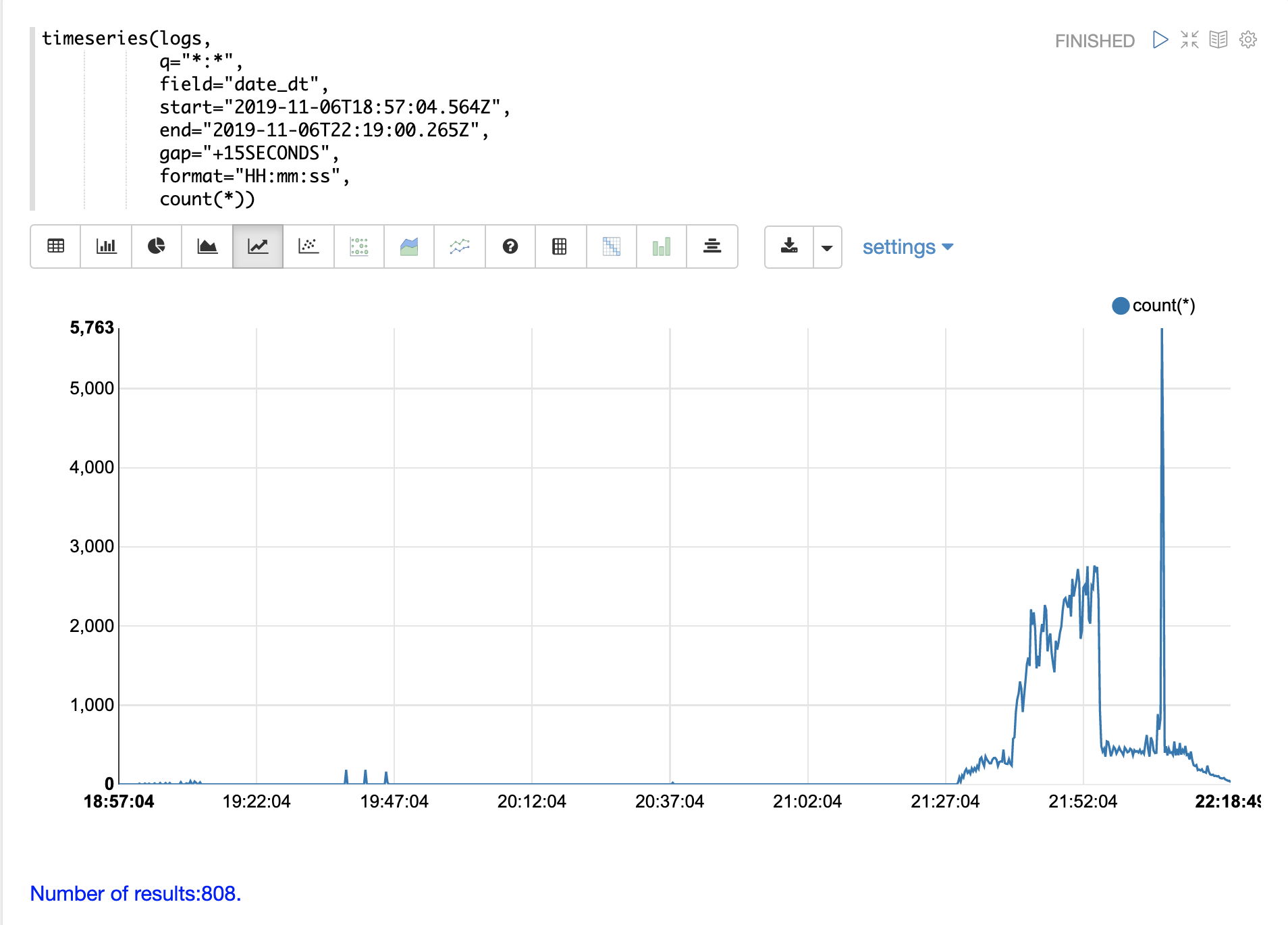
21時27分まではログアクティビティのレベルが非常に低いことに注意してください。その後、27分から52分にかけてログアクティビティが急増します。
その後、ログアクティビティが大幅に急増します。
以下の例では、type_s フィールドにクエリを追加して、ログ内の **クエリ** アクティビティのみを視覚化することで、これをさらに詳しく分析しています。
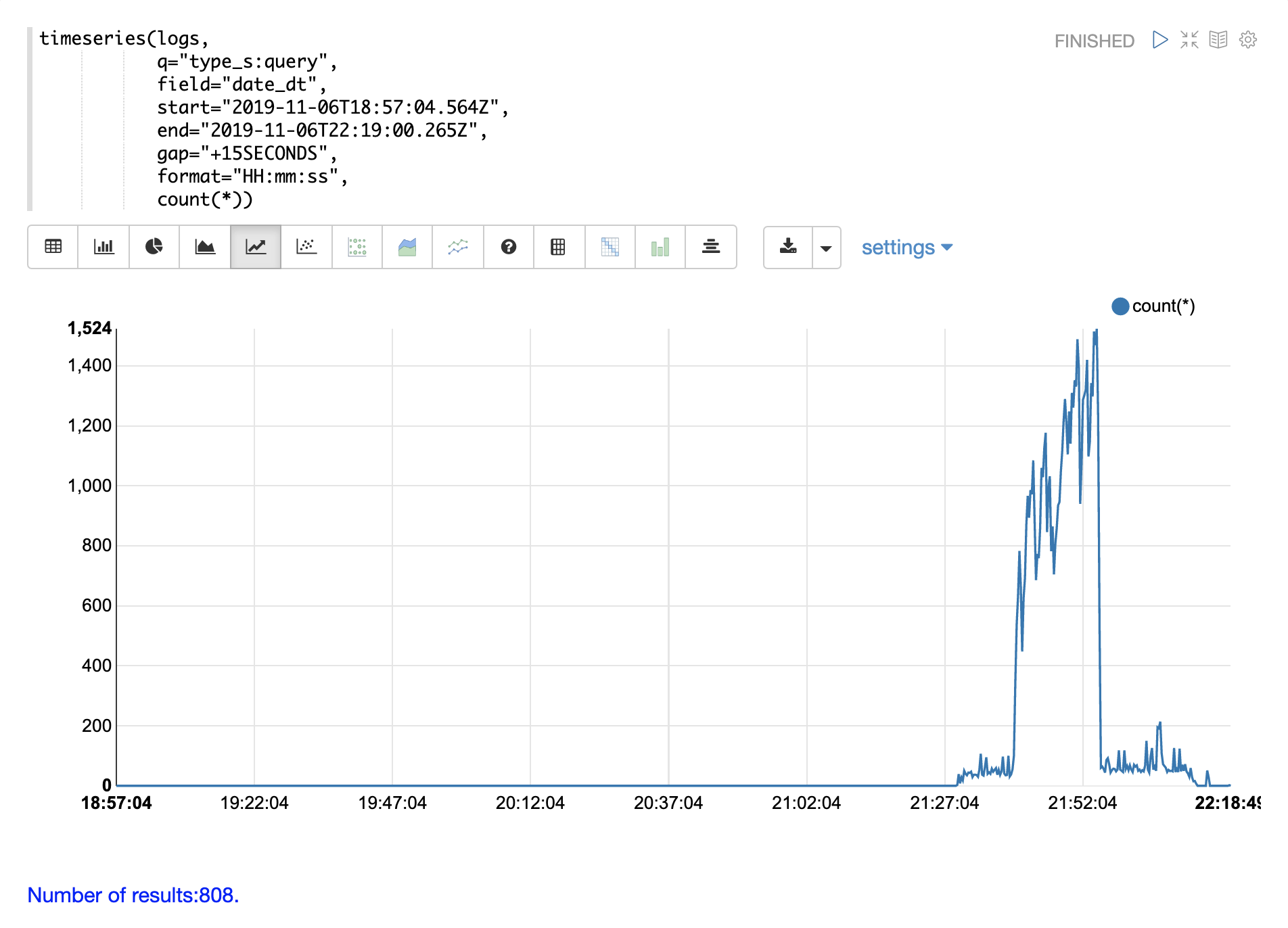
クエリアクティビティは、21:27から21:52までのログレコードの急増の半分以上を占めていることに注意してください。ただし、クエリアクティビティは、その後に続くログアクティビティの大規模な急増を説明するものではありません。
ログ内の **更新**、**コミット**、および **deleteByQuery** レコードのみを含むように検索を変更することで、その急増を説明できます。また、コレクションを絞り込むことで、これらのアクティビティがどこで発生しているかを知ることができます。
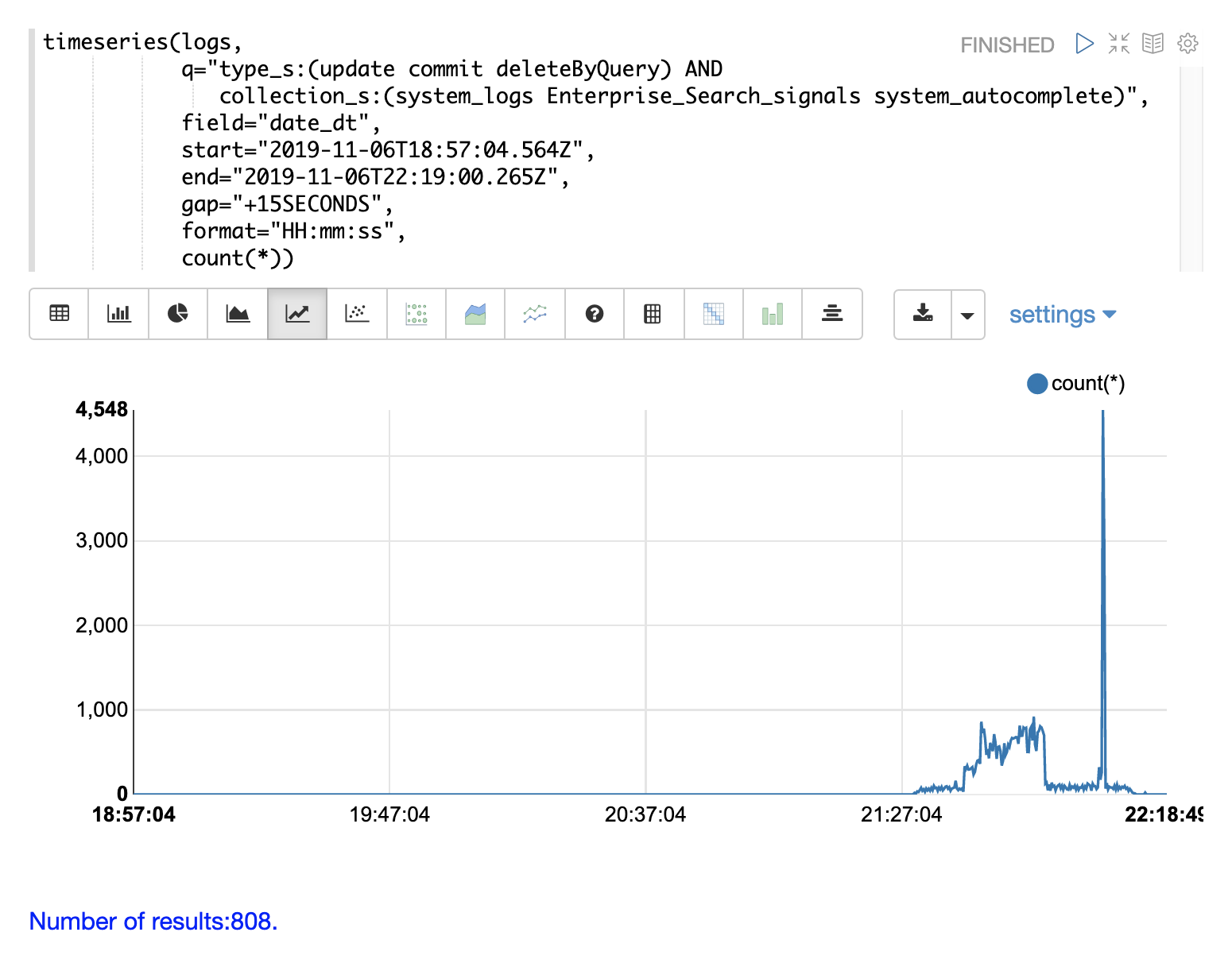
さまざまな探索的クエリと視覚化を通じて、ログに何が含まれているかをより深く理解できるようになりました。
クエリのカウント
分散検索では、クエリごとに複数のログレコードが生成されます。トップレベルの分散クエリには1つの **トップレベル** ログレコードがあり、各シャードの1つのレプリカには **シャードレベル** ログレコードがあります。また、結果のページを完成させるために、シャードからIDでフィールドを取得するための一連の **ID** クエリが存在する場合があります。
ログインデックスには、3種類のクエリレコードを区別するために使用できるフィールドがあります。
以下の例では、stats 関数を使用して、ログ内のさまざまなタイプのクエリレコードをカウントしています。同じクエリを search、random、timeseries 関数で使用して、特定の種類のクエリレコードの結果を返すことができます。
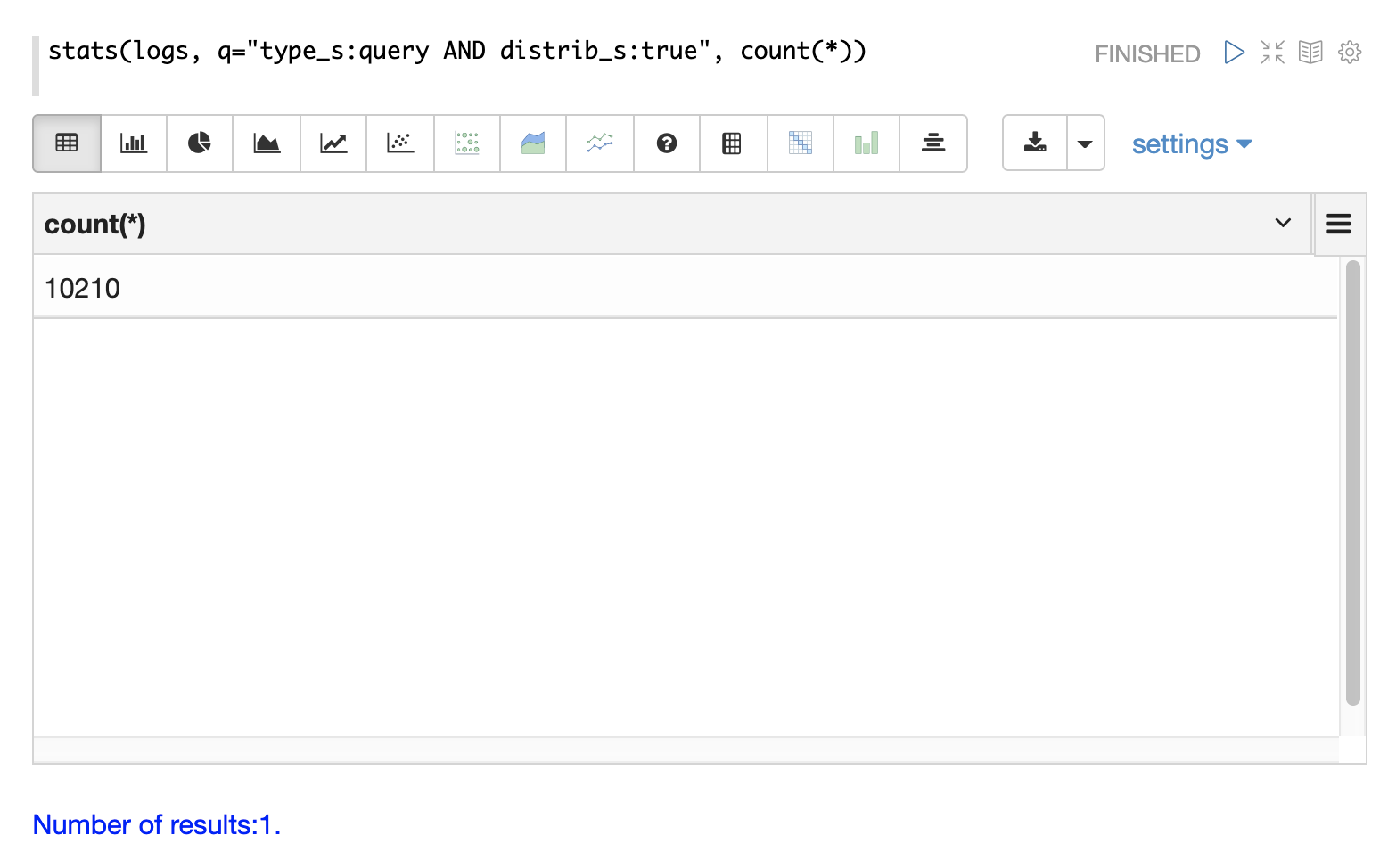
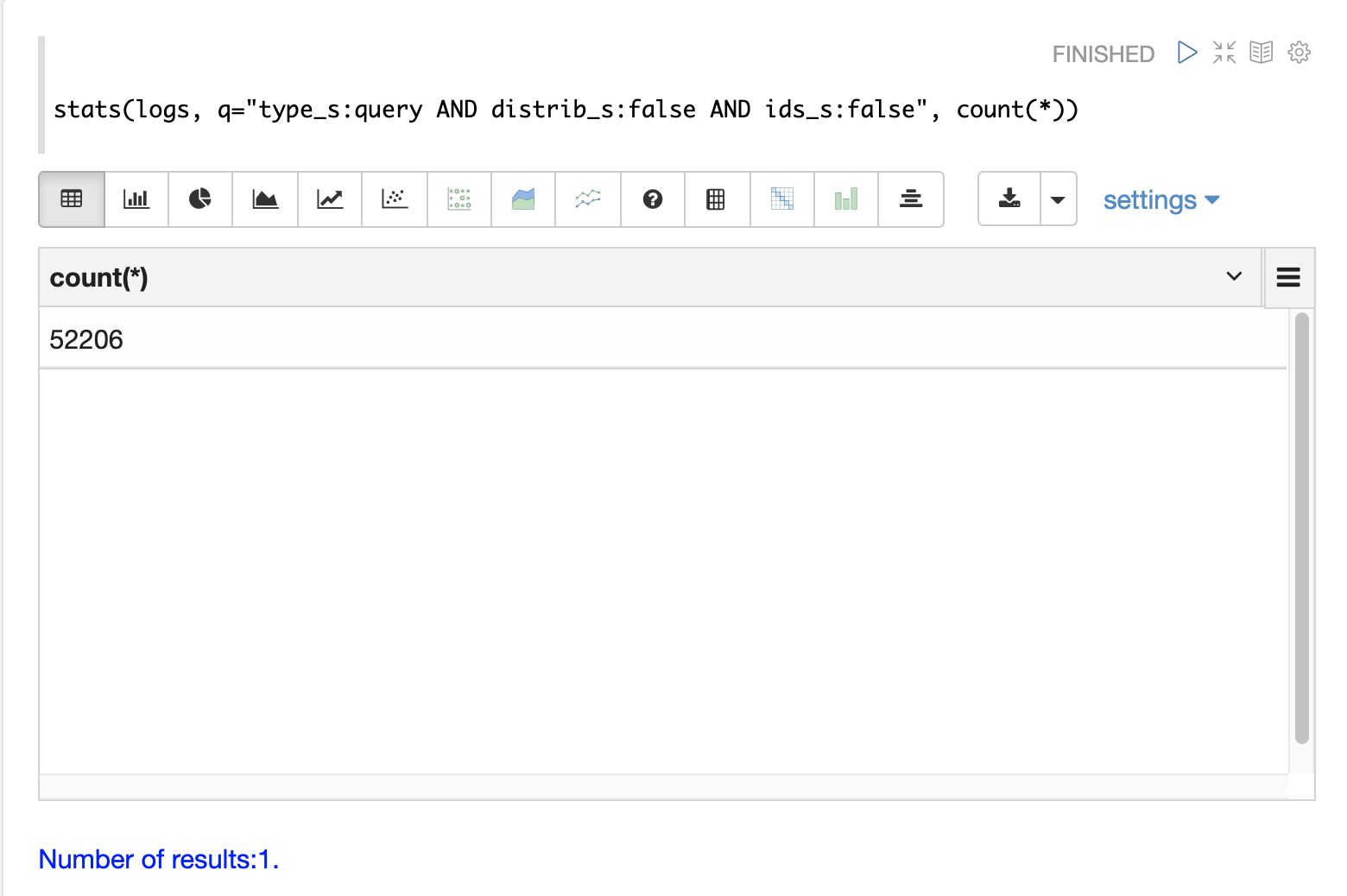
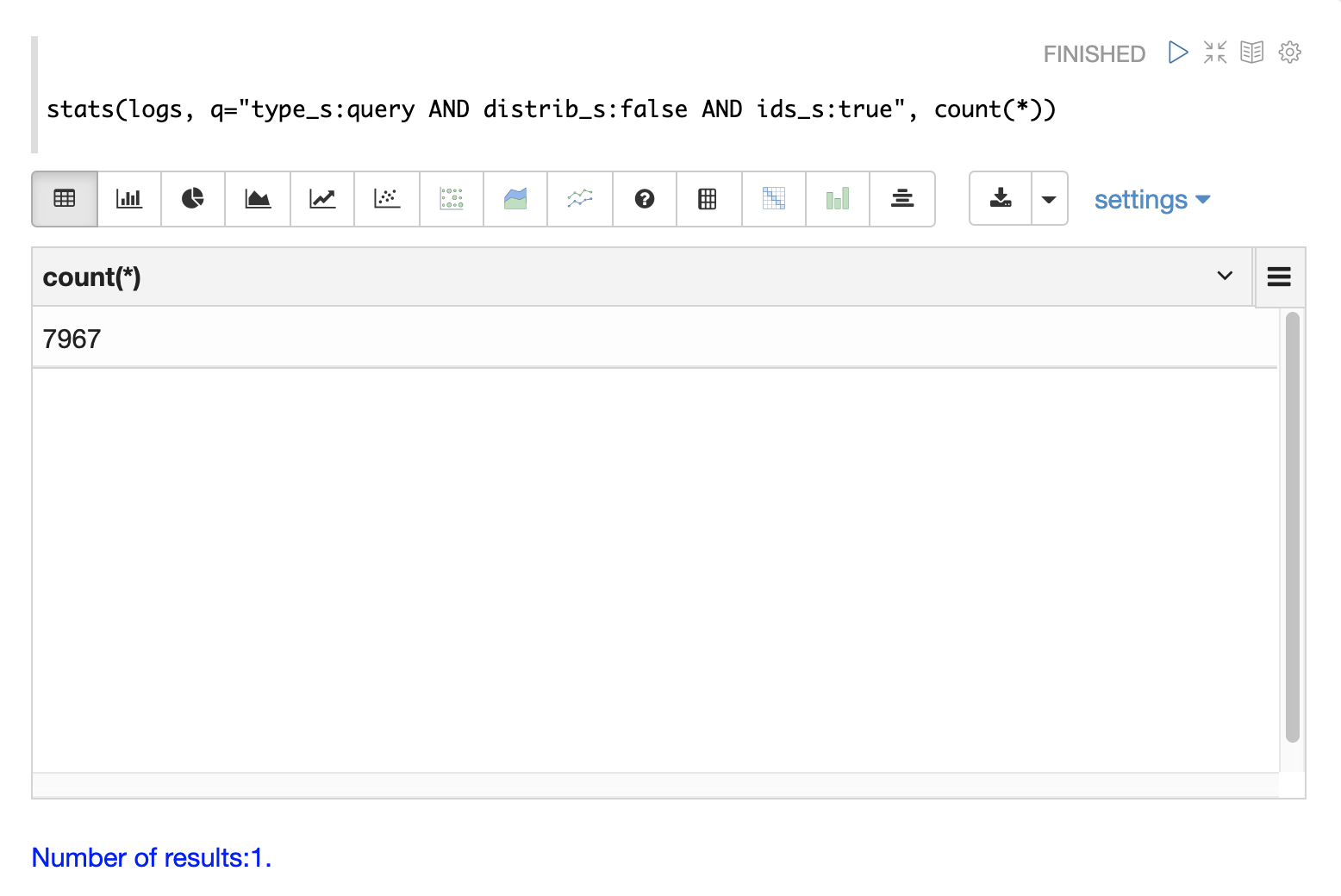
クエリのパフォーマンス
Solrログ分析の重要なタスクの1つは、Solrクラスターのパフォーマンスを理解することです。
qtime_i フィールドには、ログレコードからのクエリ時間(QTime)がミリ秒単位で含まれています。クエリのパフォーマンスを分析するための強力な視覚化と統計的手法がいくつかあります。
QTime散布図
散布図を使用して、qtime_i フィールドのランダムサンプルを視覚化できます。以下の例は、ptest1 コレクションのログレコードからの500のランダムサンプルの散布図を示しています。
この例では、qtime_i はy軸にプロットされ、x軸はクエリ時間をプロット全体に分散させるための単純なシーケンスです。
x フィールドはフィールドリストに含まれています。random 関数は、x がフィールドリストに含まれている場合、x軸のシーケンスを自動的に生成します。 |
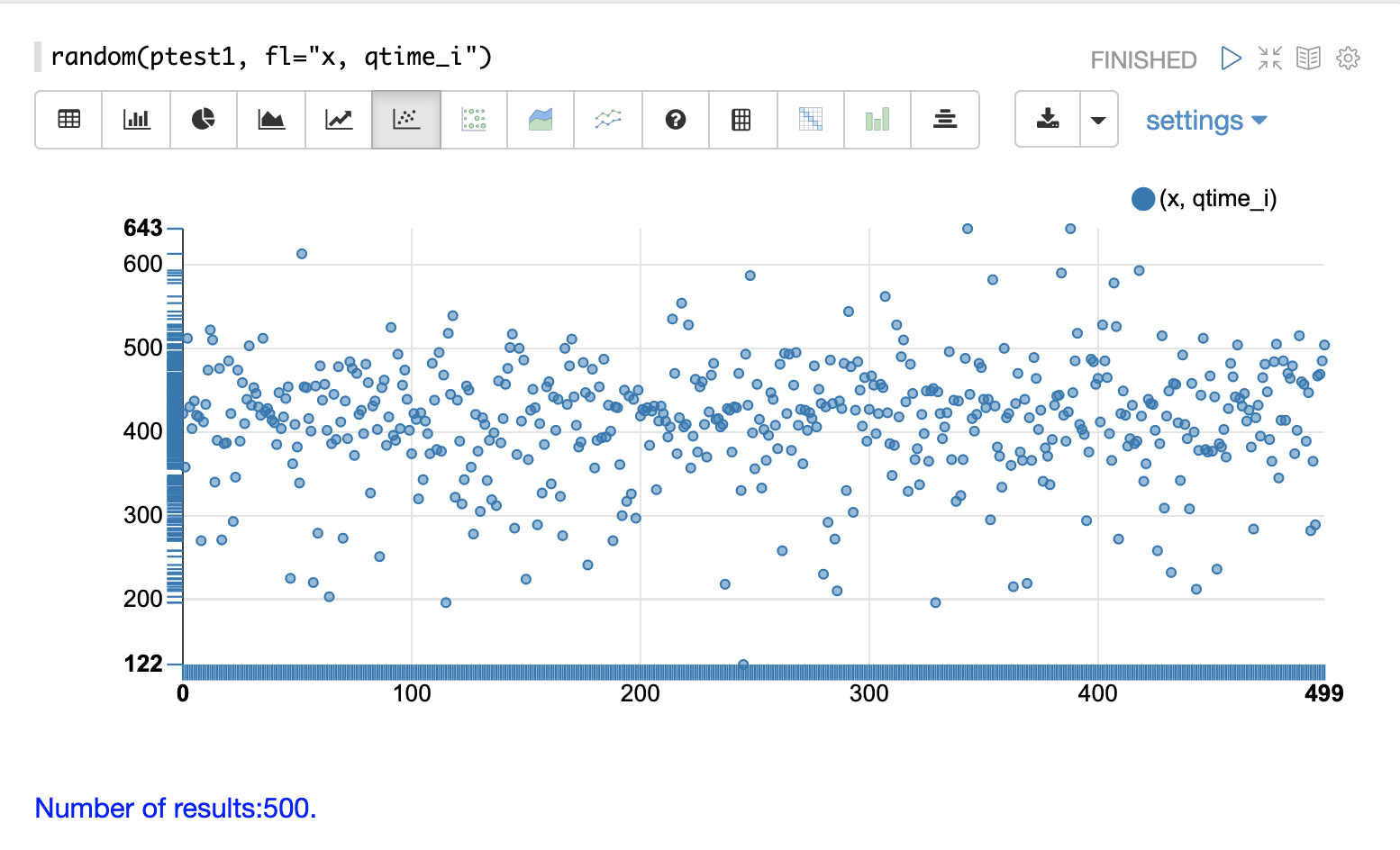
この散布図から、クエリ時間についていくつかの重要なことがわかります。
-
サンプルのクエリ時間は、最小122から最大643の範囲です。
-
平均は400ミリ秒強のようです。
-
クエリ時間は平均に近いほどクラスター化される傾向があり、平均から離れるほど頻度が低くなります。
最高のQTime散布図
ログデータに記録された最高のクエリ時間を視覚化できると便利なことがよくあります。これは、search 関数を使用し、qtime_i desc でソートすることで実行できます。
以下の例では、search 関数は ptest1 コレクションから上位500のクエリ時間を返し、結果を変数 a に設定します。次に、col 関数を使用して、結果セットから qtime_i 列をベクトルに抽出し、変数 y に設定します。
次に、zplot 関数を使用して、散布図のy軸にクエリ時間をプロットします。
rev 関数を使用してクエリ時間ベクトルを反転し、視覚化が最小クエリ時間から最大クエリ時間まで表示されるようにします。 |
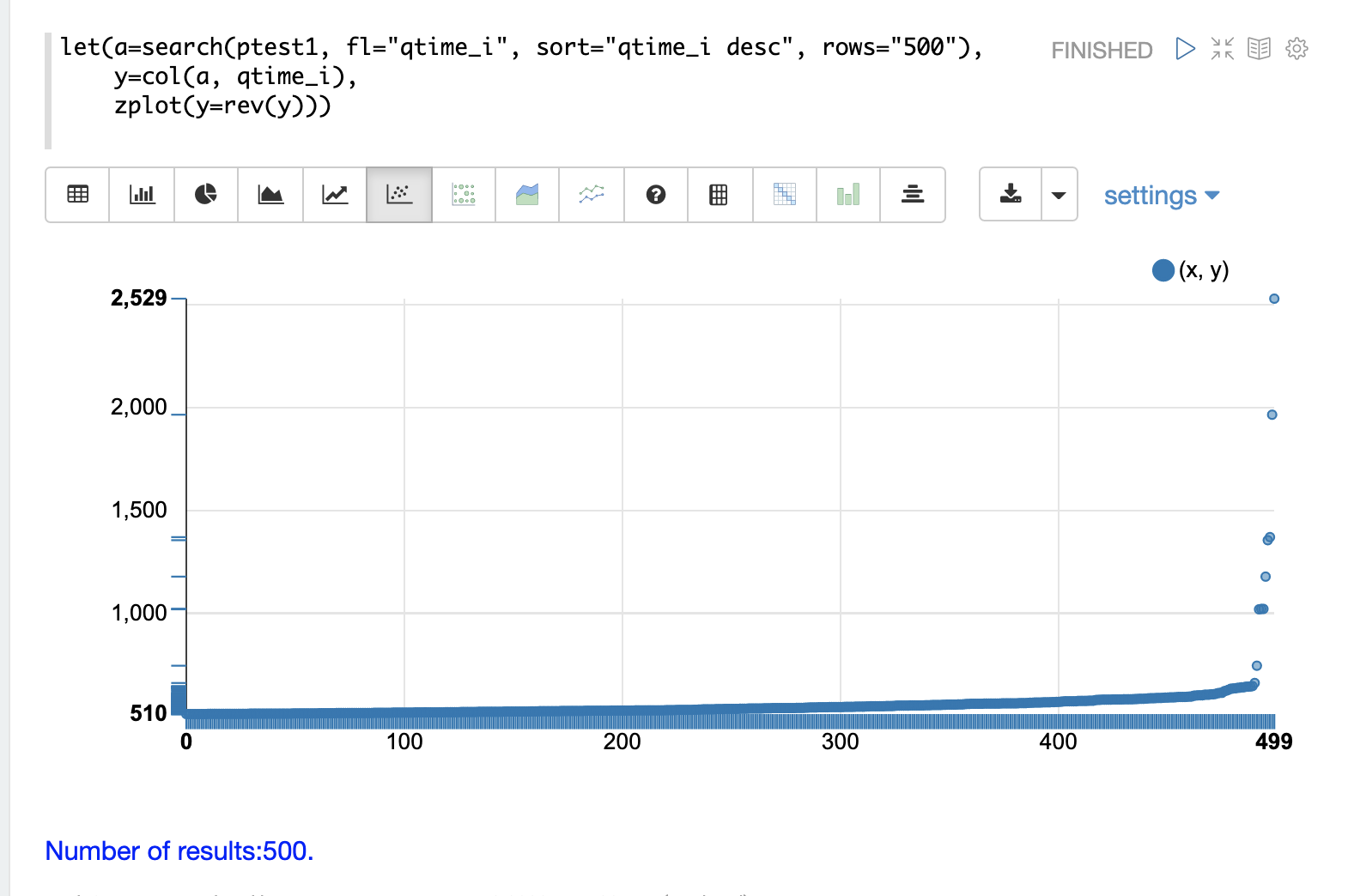
このプロットから、上位500のクエリ時間は510ミリ秒から始まり、ゆっくりと増加し、最後の10個が急上昇して、最高のクエリ時間である2529ミリ秒で終わることがわかります。
QTime分布
この例では、最も近い秒に丸めたクエリ時間の分布を示す視覚化が作成されます。
以下の例では、type_s が `query` である10000のログレコードのランダムサンプルを取得することから 시작합니다。random 関数の結果は、変数 a に割り当てられます。
次に、col 関数を使用して、結果から qtime_i フィールドを抽出します。クエリ時間のベクトルは変数 b に設定されます。
次に、scalarDivide 関数を使用して、クエリ時間ベクトルのすべての要素を1000で除算します。これにより、クエリ時間がミリ秒から秒に変換されます.結果は変数cに設定されます。
次に、round 関数は、クエリ時間ベクトルのすべての要素を最も近い秒に丸めます。これは、500ミリ秒未満のすべてのクエリ時間が0に丸められることを意味します。
次に、freqTable 関数が、最も近い秒に丸められたクエリ時間のベクトルに適用されます。
結果の頻度表を以下の視覚化に示します。x軸は秒数です。y軸は、各秒に丸められたクエリ時間の数です。
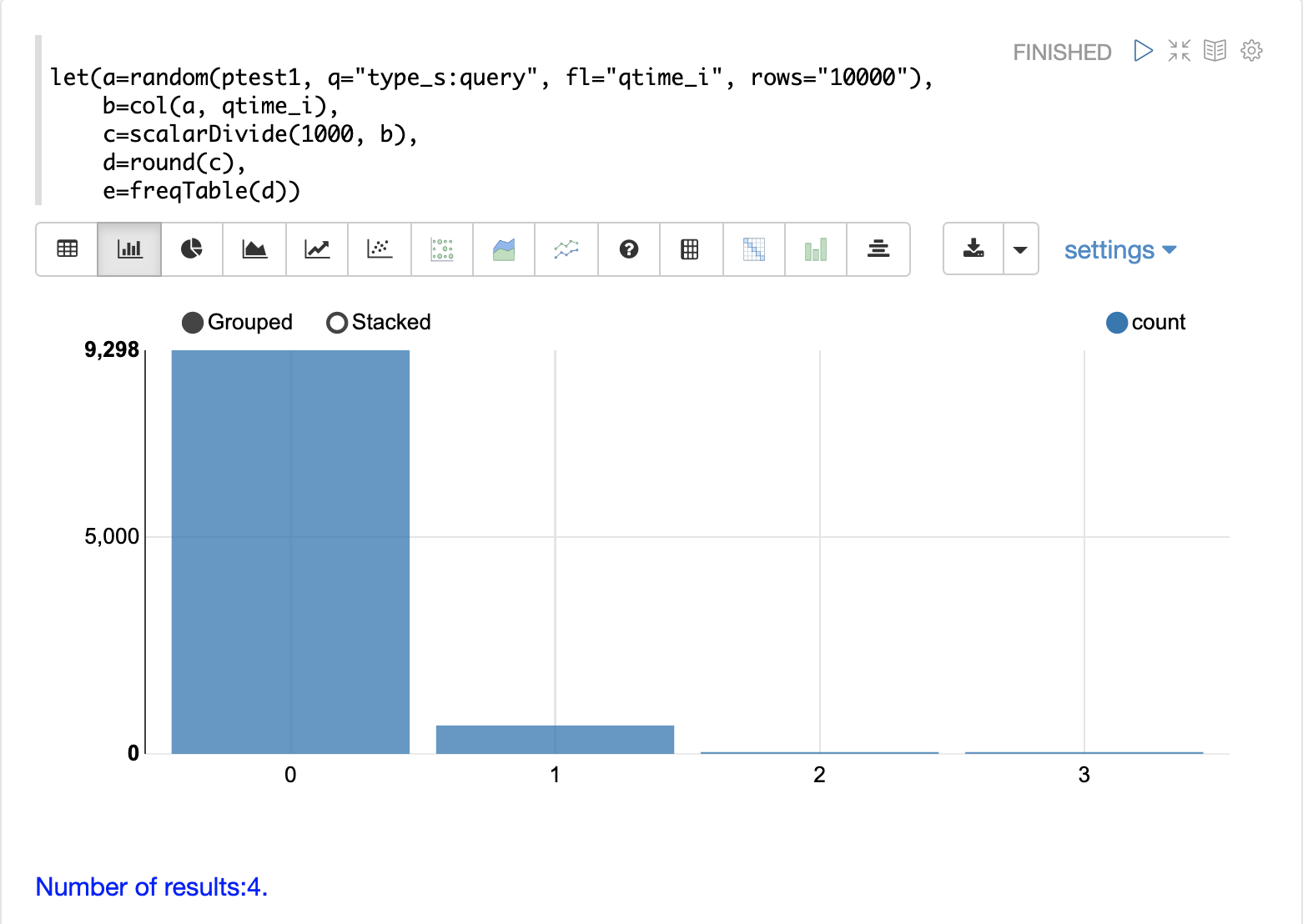
クエリ時間の約93%が0に丸められていることに注意してください。これは、500ミリ秒未満であったことを意味します。約6%が1に丸められ、残りは2秒または3秒に丸められました。
QTimeパーセンタイルプロット
パーセンタイルプロットは、ログ内のクエリ時間の分布を理解するためのもう1つの強力なツールです。以下の例は、パーセンタイルプロットを作成および解釈する方法を示しています。
この例では、パーセンタイルの array が作成され、変数 p に設定されます。
次に、10000のログレコードのランダムサンプルが描画され、変数 a に設定されます.次に、col 関数を使用して、サンプル結果から qtime_i フィールドを抽出し、このベクトルを変数 b に設定します。
次に、percentile 関数を使用して、クエリ時間のベクトルの各パーセンタイルの値を計算します。変数 p に設定されたパーセンタイルの配列は、percentile 関数にどのパーセンタイルを計算するかを指示します。
次に、zplot 関数を使用して、x軸に **パーセンタイル** を、y軸に各パーセンタイルの **クエリ時間** をプロットします。
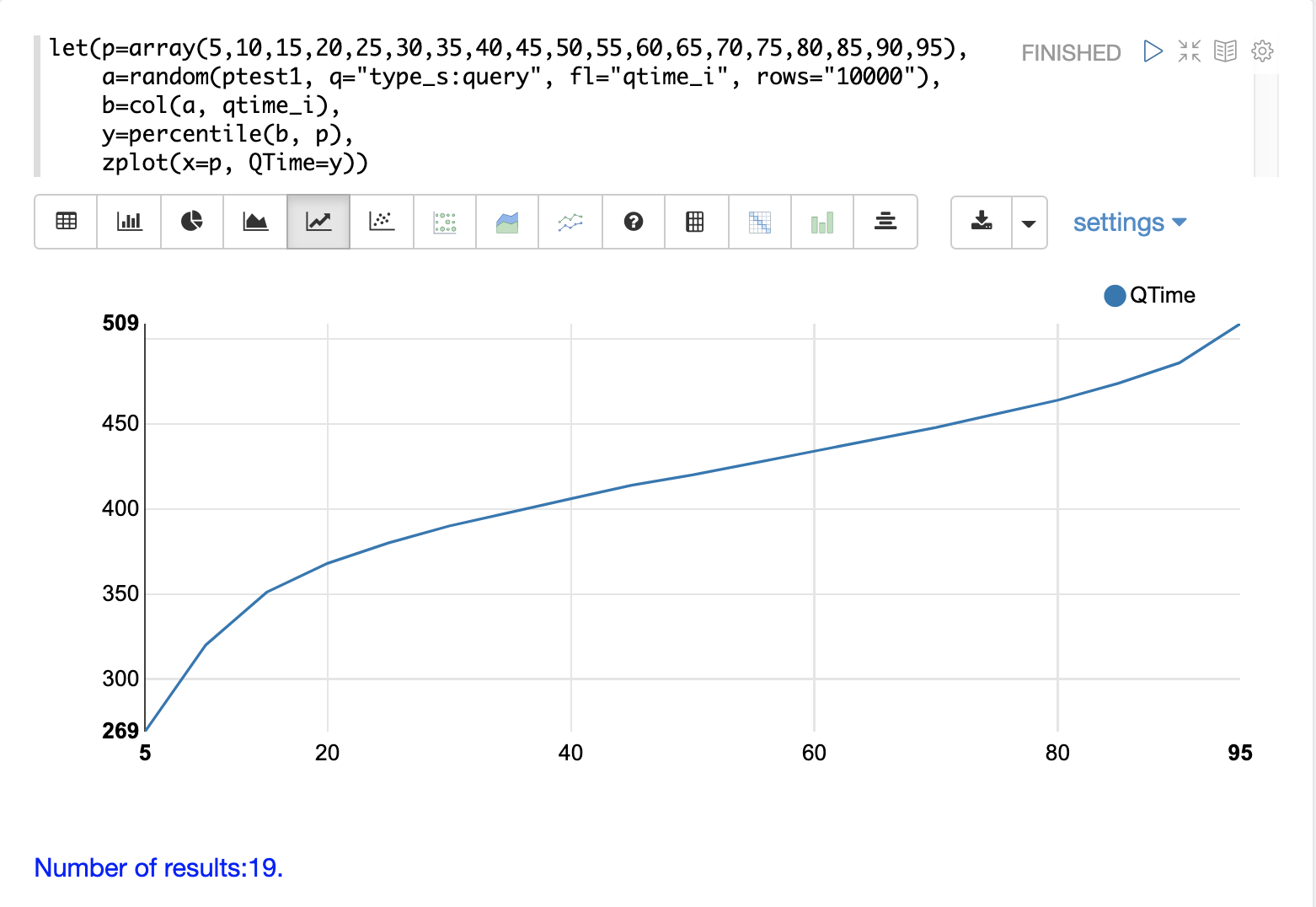
プロットから、80パーセンタイルのクエリ時間が464ミリ秒であることがわかります。これは、クエリの80%が464ミリ秒未満であることを意味します。
パフォーマンスのトラブルシューティング
クエリ分析でクエリが期待どおりに実行されていないと判断された場合、ログ分析を使用して、速度低下の原因をトラブルシューティングすることもできます。以下のセクションでは、クエリ速度低下の原因を特定するためのいくつかのアプローチを示します。
低速ノード
分散検索では、最終的な検索パフォーマンスは、クラスター内で最も応答の遅いシャードと同じ速度になります。したがって、1つの低速ノードが検索時間全体の低速の原因となる可能性があります。
フィールド core_s、replica_s、および shard_s はログレコードで使用できます。これらのフィールドを使用すると、**コア**、**レプリカ**、または **シャード** ごとに平均クエリ時間を計算できます。
core_s フィールドは、最も粒度の細かい要素であり、命名規則には多くの場合コレクション、シャード、およびレプリカの情報が含まれているため、特に役立ちます。
以下の例では、facet 関数を使用して、コアごとに avg(qtime_i) を計算しています。
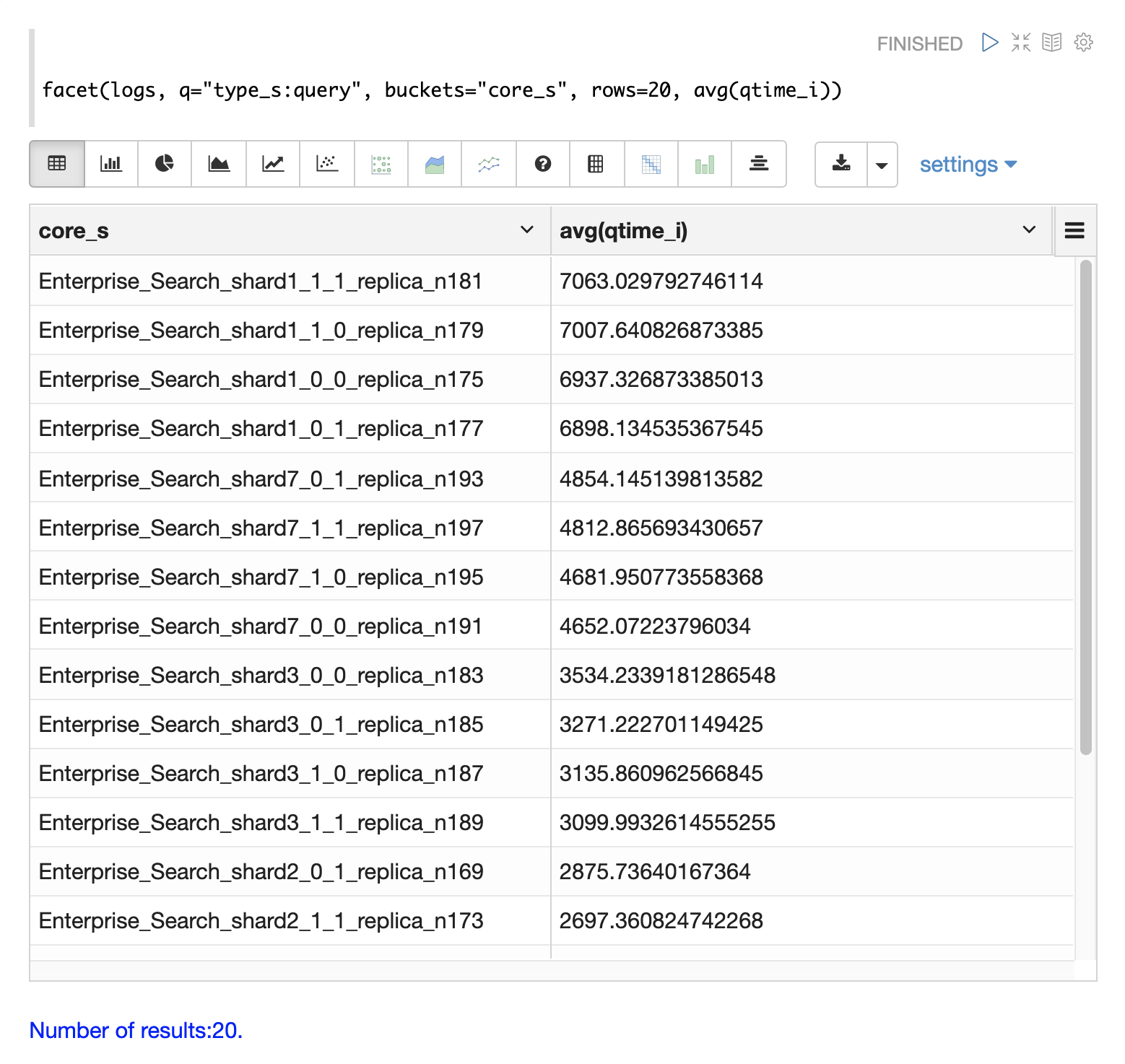
結果では、core_s フィールドに **コレクション**、**シャード**、および **レプリカ** に関する情報が含まれていることに注意してください。この例では、同じコレクション内の特定のコアではqtimeがかなり高くなることも示しています。これは、これらのコアのパフォーマンスが遅い理由について、より詳細な調査を行うきっかけとなるはずです。
低速クエリ
クエリ分析で、ほとんどのクエリは良好に実行されているが、低速の外れ値クエリがあることが示された場合、この理由の1つは、特定のクエリが低速である可能性があります。
q_s フィールドと q_t フィールドはどちらも、Solrリクエストからの **q** パラメーターの値を保持します。q_s フィールドは文字列フィールドであり、q_t フィールドはトークン化されています。
search 関数を使用して、結果を qtime_i desc でソートすることにより、ログ内で最も遅い上位N個のクエリを返すことができます。以下の例はこれを示しています。

クエリが取得されたら、それらを個別に調べて試して、クエリが常に低速かどうかを判断できます.クエリが低速であることが示された場合、クエリのパフォーマンスを向上させる計画を立てることができます。
コミット
コミット、およびフルインデックスレプリケーションなどのコミットを引き起こすアクティビティにより、クエリのパフォーマンスが低下する可能性があります.時系列の視覚化は、コミットがパフォーマンスの低下に関連しているかどうかを判断するのに役立ちます。
最初のステップは、クエリパフォーマンスの問題を可視化することです。以下の時系列グラフは、ログの結果を`query`タイプのレコードに限定し、10分間隔で`max(qtime_i)`を計算したものです。横軸には日、時、分が表示され、縦軸には`max(qtime_i)`がミリ秒単位で表示されます。`max(qtime_i)`にいくつかの極端なスパイクがあることに注意してください。これらを理解する必要があります。
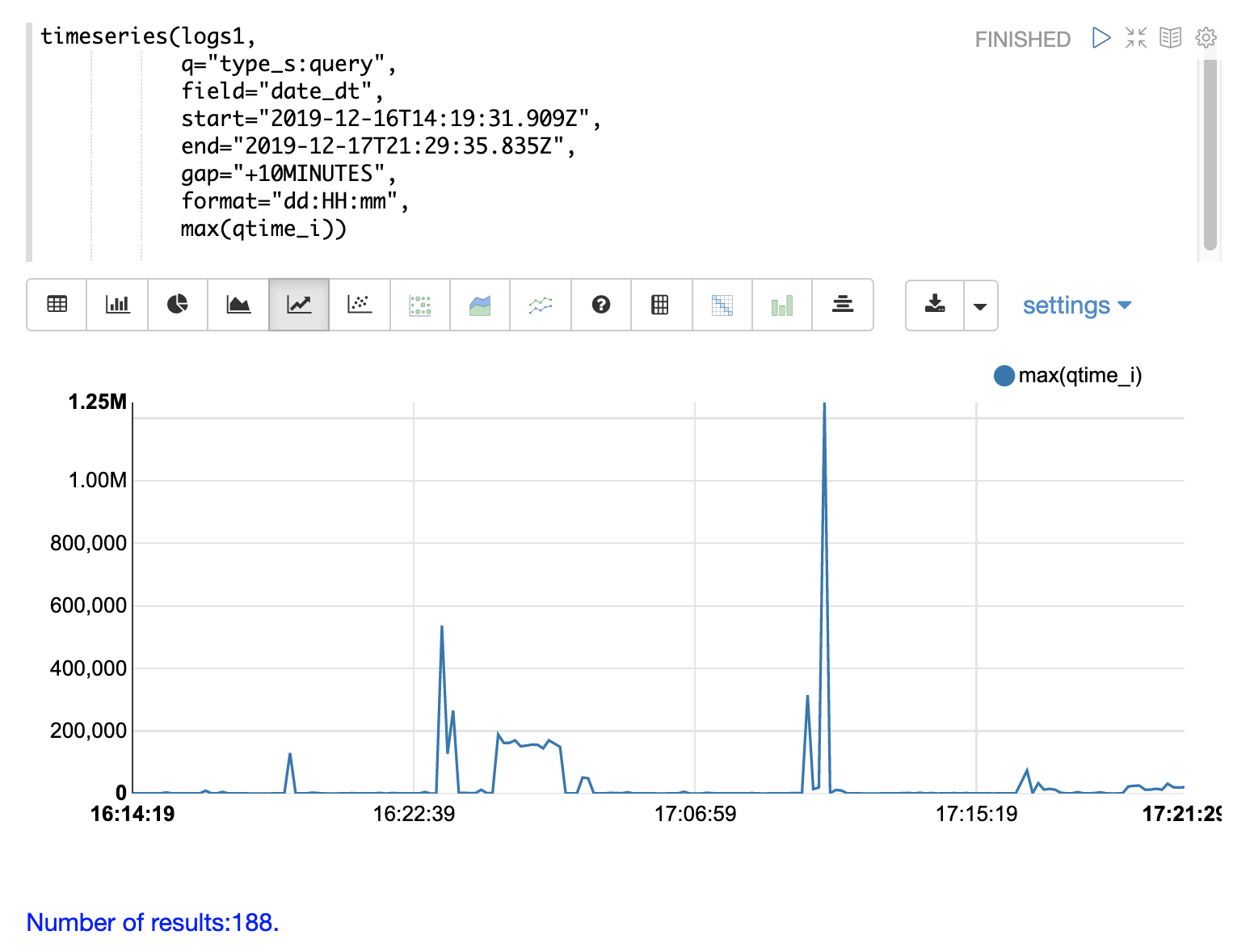
次のステップは、同じ時間間隔でコミット数をカウントする時系列グラフを生成することです。以下の時系列グラフは、最初の時系列グラフと同じ`start`、`end`、`gap`を使用します。ただし、この時系列グラフは`commit`タイプのレコードに対して計算されます。コミット数は計算され、縦軸にプロットされます。
`max(qtime_i)`のスパイク付近に、コミットアクティビティのスパイクがあることに注意してください。

最後のステップは、2つの時系列グラフを同じプロットに重ね合わせることです。
これは、両方の時系列グラフを実行し、結果を変数(この場合は`a`と`b`)に設定することによって行われます。
次に、`date_dt`フィールドと`max(qtime_i)`フィールドが最初の時系列グラフからベクトルとして抽出され、`col`関数を使用して変数に設定されます。そして、`count(*)`フィールドが2番目の時系列グラフから抽出されます。
`zplot`関数は、タイムスタンプベクトルを横軸に、最大クエリ時間とコミットカウントベクトルを縦軸にプロットするために使用されます。
| `minMaxScale`関数は、両方のベクトルを0から1の間にスケールするために使用されます。これにより、同じプロットで視覚的に比較できます。 |
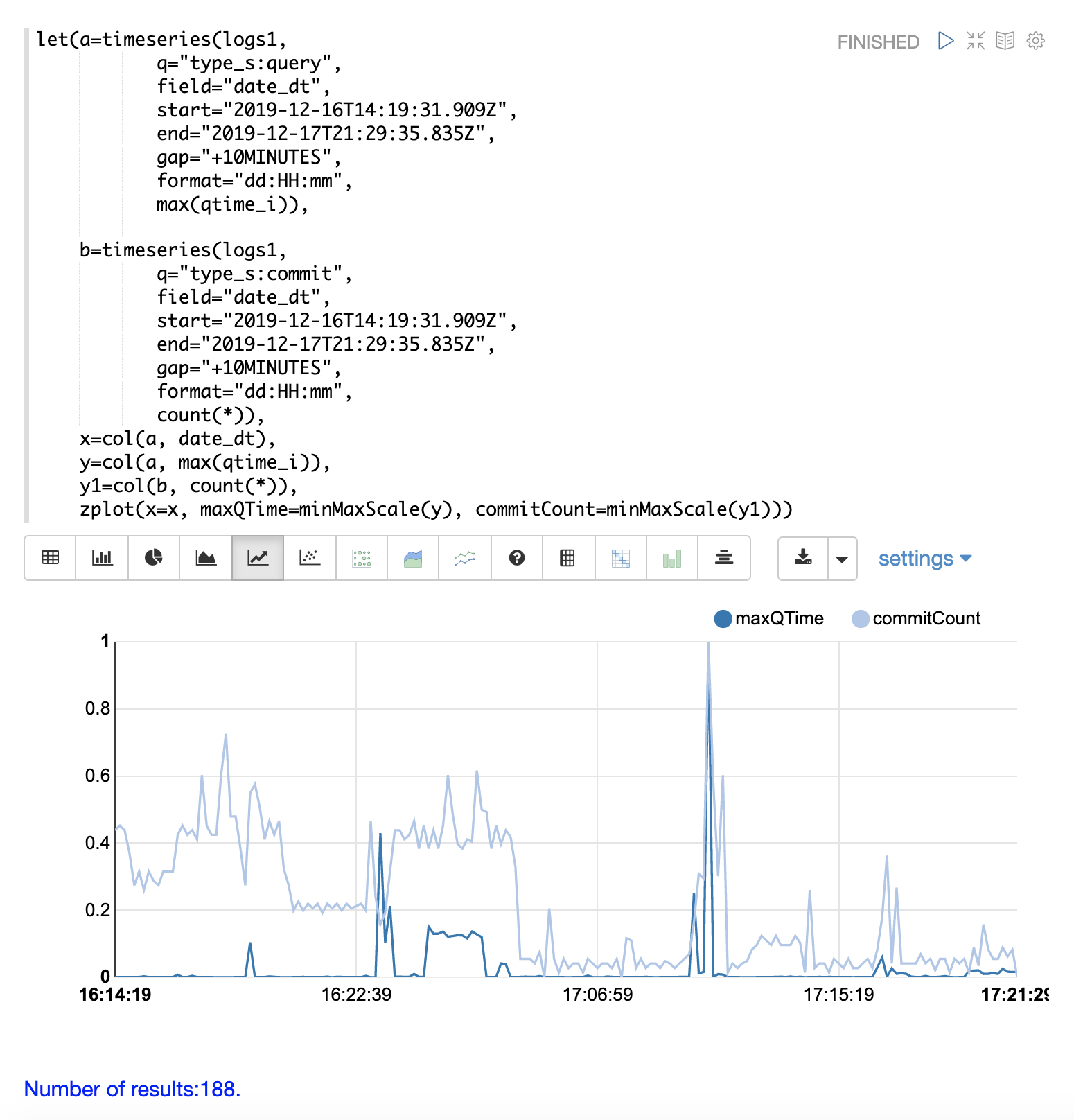
このプロットでは、コミットカウントが`max(qtime_i)`のスパイクと密接に関連しているように見えることに注意してください。