グラフ
このユーザガイドのセクションでは、**グラフ式**の構文と理論について説明します。**2部グラフレコメンダー**と**時間的グラフクエリ**を使用した**イベント相関**という2つの主要なグラフユースケースの例を示します。
グラフ
Solrにインデックスされたログレコードやその他のデータには、分散グラフとして見ることができる相互接続があります。グラフ式は、グラフ内のルートノードを特定し、その接続を辿るためのメカニズムを提供します。グラフウォークの一般的な目的は、特定の**サブグラフ**を具体化し、**リンク分析**を実行して、ノード間の接続を理解することです。
以下のいくつかのセクションでは、Solrのグラフ式を支えるグラフ理論について検討します。
サブグラフ
サブグラフは、より大きなグラフのノードと接続のより小さなサブセットです。グラフ式を使用すると、分散インデックスに格納されているより大きなグラフからサブグラフを柔軟に定義して具体化できます。
サブグラフは2つの重要な役割を果たします。
-
リンク分析のためのローカルコンテキストを提供します。サブグラフの設計によって、リンク分析の意味が定義されます。
-
異常検出の目的で、バックグラウンドインデックスと比較できるフォアグラウンドグラフを提供します。
2部グラフ
グラフ式を使用して、**2部グラフ**を具体化できます。2部グラフとは、ノードが2つの異なるカテゴリに分割されているグラフです。これらの2つのカテゴリ間のリンクを分析して、それらがどのように関連しているかを調査できます。2部グラフは、協調フィルタリングレコメンダーシステムのコンテキストでよく議論されます。
**買い物かご**と**商品**間の2部グラフは、有用な例です。買い物かごと商品間のリンク分析を通じて、どの商品が同じ買い物かごの中で最も頻繁に購入されているかを判断できます。
以下の例では、basketsというSolrコレクションがあり、3つのフィールドがあります。
**id**: 一意のID
**basket_s**: 買い物かごID
**product_s**: 商品
コレクション内の各レコードは、ショッピングバスケット内の製品を表します。同じバスケット内のすべての製品は、同じバスケットIDを共有します。
バターと一緒に販売されることが多い製品を見つけることを目的とした簡単な例を考えてみましょう。これを行うために、バターを含むショッピングバスケットの二部グラフを作成することができます。バター自体はグラフに含めません。これは、バターの補完製品を見つけるのに役立たないためです。
以下は、行列として表されたこの二部グラフの例です。
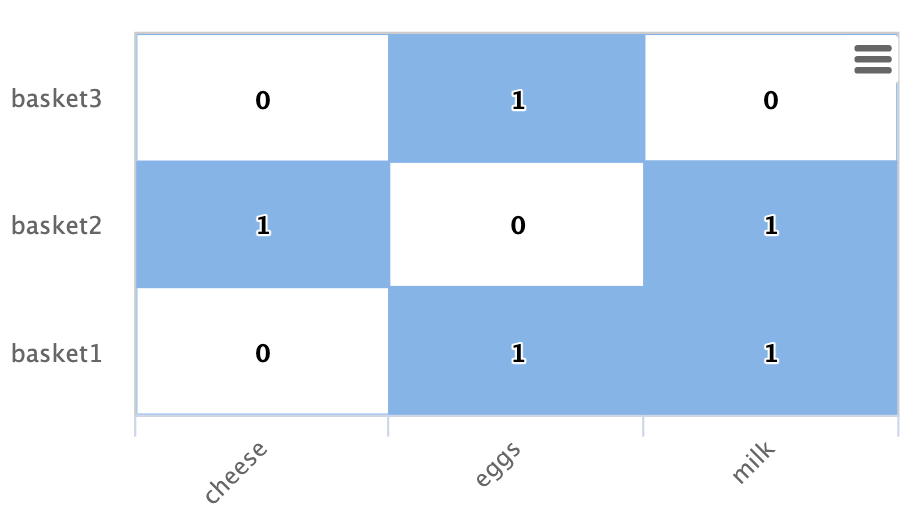
この例では、行で示される3つのショッピングバスケット(basket1、basket2、basket3)があります。
列で示される3つの製品(チーズ、卵、牛乳)もあります。
各セルには、製品がバスケット内にあるかどうかを示す1または0が入っています。
Solrグラフ式がこの二部グラフをどのように具体化するのかを見てみましょう。
nodes関数は、より大きなグラフから部分グラフを具体化するために使用されます。以下は、上記の行列に示されている二部グラフを具体化するnodes関数の例です。
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true")random関数から始めて、この例を分解してみましょう。
random(baskets, q="product_s:butter", fl="basket_s", rows="3")random関数は、クエリproduct_s:butterを使用してバスケットコレクションを検索し、3つのランダムサンプルを返します。各サンプルには、バスケットIDであるbasket_sフィールドが含まれています。ランダムサンプルによって返される3つのバスケットIDは、グラフクエリのルートノードです。
nodes関数はグラフクエリです。nodes関数は、random関数によって返された3つのルートノード上で動作します。インデックス内のbasket_sフィールドに対してルートノードのbasket_sフィールドを検索することでグラフを「巡回」します。これにより、ルートバスケットのすべての製品レコードが見つかります。その後、巡回で見つかったレコードからproduct_sフィールドを「収集」します。フィルターが適用されるため、product_sフィールドにバターが含まれているレコードは返されません。
trackTraversalフラグは、ノード式にルートバスケットと製品間のリンクを追跡するように指示します。
ノードセット
nodes関数の出力は、nodes関数によって指定された部分グラフを表すノードセットです。ノードセットには、グラフ巡回中に収集されたノードの一意のセットが含まれています。結果のnodeプロパティは、収集されたノードの値です。ショッピングバスケットの例では、nodes式で収集するように指定されたため、product_sフィールドがnodeプロパティにあります。
ショッピングバスケットのグラフ式の出力は次のとおりです。
{
"result-set": {
"docs": [
{
"node": "eggs",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket3"
],
"level": 1
},
{
"node": "cheese",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket2"
],
"level": 1
},
{
"node": "milk",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket2"
],
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 12
}
]
}
}結果のancestorsプロパティには、部分グラフ内のノードへのすべての着信リンクの一意でアルファベット順にソートされたセットが含まれています。この場合、各製品にリンクされているバスケットを示しています。祖先リンクは、nodes式でtrackTraversalフラグがオンになっている場合にのみ追跡されます。
リンク分析と次数中心性
リンク分析は、ノードの中心性を決定するためにしばしば実行されます。中心性を分析する場合の目標は、部分グラフにおける接続度に基づいて各ノードに重みを割り当てることです。ノードの中心性にはさまざまな種類があります。グラフ式は、着信次数中心性(インデグリー)を非常に効率的に計算します。
着信次数中心性は、各ノードへの着信リンクの数を数えることによって計算されます。簡潔にするため、このドキュメントでは、着信次数を単に次数と呼ぶ場合があります。
ショッピングバスケットの例に戻りましょう。
グラフ内の製品の次数は、列を合計することで計算できます。
cheese: 1
eggs: 2
milk: 2次数計算から、卵と牛乳は、チーズよりもバターを含むショッピングバスケットに頻繁に出現することがわかります。
nodes関数は、以下に示すようにcount(*)集計を追加することで次数中心性を計算できます。
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*))このグラフ式の出力は次のとおりです。
{
"result-set": {
"docs": [
{
"node": "eggs",
"count(*)": 2,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket3"
],
"level": 1
},
{
"node": "cheese",
"count(*)": 1,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket2"
],
"level": 1
},
{
"node": "milk",
"count(*)": 2,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket2"
],
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 17
}
]
}
}count(*)集計は、「収集された」ノード、この場合はproduct_sフィールドの値をカウントします。count(*)の結果は、祖先の数と同じであることに注意してください。これは、nodes関数が収集されたノードをカウントする前に、エッジの重複を除去するためです。このため、count(*)集計は常に収集されたノードの着信次数中心性を計算します。
ドット積
着信次数と二部グラフレコメンダーの間には、ドット積との直接的な関係があります。バターの列を追加すると、作業例でこの関係を明確に確認できます。
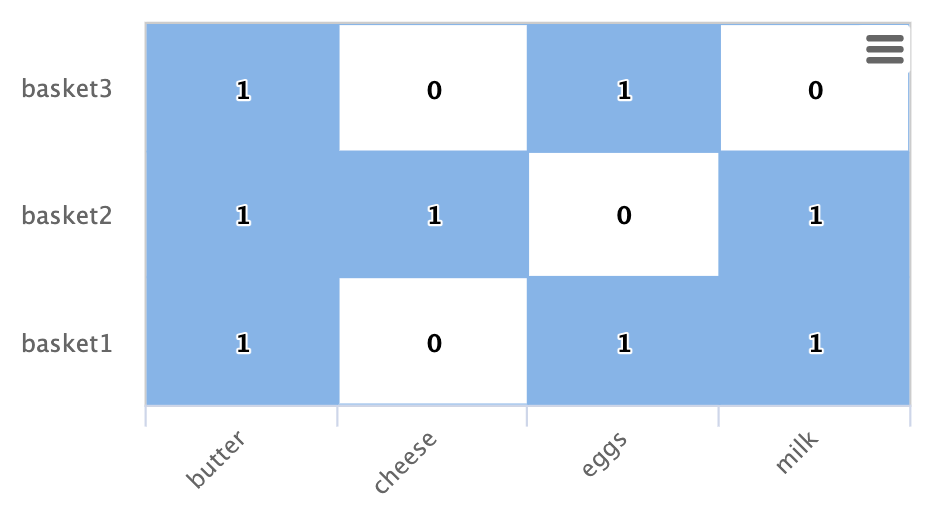
バター列と他の製品列のドット積を計算すると、ドット積はそれぞれの場合に着信次数と等しくなります。これは、最大内積類似度を使用した最近傍検索では、着信次数が最も高い列が選択されることを意味します。
バスケットの出力次数を制限する
バスケットの出力次数を制限することで、推奨をより強力にすることができます。出力次数は、グラフ内のノードの出力リンクの数です。ショッピングバスケットの例では、バスケットからの出力リンクは製品にリンクしています。したがって、出力次数を制限すると、バスケットのサイズが制限されます。
ショッピングバスケットのサイズを制限すると、なぜ推奨がより強力になるのでしょうか?この質問に答えるには、各ショッピングバスケットをバターと組み合わせる製品に投票していると考えることが役立ちます。2人の候補者がいる選挙では、両方の候補者に投票すると、票は相殺され、効果がありません。しかし、1人の候補者にのみ投票すると、投票は結果に影響を与えます。同じ原則が推奨にも当てはまります。バスケットがより多くの製品に投票すると、1つの製品に対する推奨の強さが薄まります。バターともう1つのアイテムしかないバスケットは、そのアイテムをより強く推奨します。
maxDocFreqパラメーターを使用して、グラフの「巡回」を、インデックスに特定の回数だけ表示されるバスケットのみに含めることができます。インデックス内のバスケットIDの各出現は製品へのリンクであるため、バスケットIDのドキュメント頻度を制限すると、バスケットの出力次数が制限されます。maxDocFreqパラメーターはシャードごとに適用されます。単一のシャードがある場合、またはドキュメントがバスケットIDによって共配置されている場合、maxDocFreqは正確なカウントになります。そうでない場合、numShards * maxDocFreqの最大サイズを持つバスケットを返します。
以下の例は、nodes式に適用されるmaxDocFreqパラメーターを示しています。
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
maxDocFreq="5",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*))ノードスコアリング
ノードの次数は、部分グラフ内のどのノードがそれにリンクしているかを示しています。しかし、これは、ノードが特にこの部分グラフの中心であるか、それとも全体グラフで非常に頻繁に出現するノードであるかを示しているわけではありません。部分グラフでは頻繁に出現するが、全体グラフではめったに出現しないノードは、部分グラフに対してより関連性が高いと見なすことができます。
検索インデックスには、各ノードが全体インデックスにどのくらいの頻度で出現するかに関する情報が含まれています。tf-idfドキュメントスコアリングと同様の手法を使用して、グラフ式はノードの次数とインデックス内の逆文書頻度を組み合わせて関連性スコアを決定できます。
scoreNodes関数はノードをスコアリングします。以下は、ショッピングバスケットのノードセットに適用されるscoreNodes関数の例です。
scoreNodes(nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*)))出力には、nodeScoreプロパティが含まれるようになりました。以下の出力では、卵はcount(*)が同じであるにもかかわらず、牛乳よりも高いnodeScoreを持っていることに注意してください。これは、牛乳は卵よりも全体インデックスに頻繁に出現するためです。nodeScore関数によって追加されたdocFreqプロパティは、インデックス内のドキュメント頻度を示しています。docFreqが低いということは、卵はこの部分グラフに関連性が高く、バターと組み合わせるためのより良い推奨事項であると見なされることを意味します。
{
"result-set": {
"docs": [
{
"node": "eggs",
"nodeScore": 3.8930247,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 2,
"collection": "baskets",
"ancestors": [
"basket1",
"basket3"
],
"docFreq": 2
},
{
"node": "milk",
"nodeScore": 3.0281217,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 2,
"collection": "baskets",
"ancestors": [
"basket1",
"basket2"
],
"docFreq": 4
},
{
"node": "cheese",
"nodeScore": 2.7047482,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 1,
"collection": "baskets",
"ancestors": [
"basket2"
],
"docFreq": 1
},
{
"EOF": true,
"RESPONSE_TIME": 26
}
]
}
}時系列グラフ式
上記の例は、時系列グラフクエリの基礎を築いています。時系列グラフクエリでは、nodes関数が時間ウィンドウを使用してグラフを巡回し、時系列グラフ内のクロス相関を表面化することができます。現在、nodes関数は、10秒ウィンドウ、日次ウィンドウ、曜日ウィンドウを使用したグラフ巡回をサポートしています。
10秒ウィンドウは、ログ分析におけるイベント相関と根本原因分析に役立ちます。日次および曜日ウィンドウは、数日離れて発生するイベントを関連付けるのに役立ちます。
時系列グラフクエリをサポートするために、ISO 8601形式の切り捨てられたタイムスタンプを、インデックス作成時に文字列フィールドとしてログレコードに追加する必要があります。10秒の時間ウィンドウをサポートするには、10秒間切り捨てられたタイムスタンプを文字列フィールドに次のようにインデックスする必要があります。2021-02-10T20:51:30Z。日次および週次時間ウィンドウをサポートするには、日次で切り捨てられたタイムスタンプを文字列フィールドに次のようにインデックスする必要があります。2021-02-10T00:00:00Z。
ここで説明されているSolrログ用のSolrインデックス作成ツールは、すでに10秒間切り捨てられたタイムスタンプを追加しています。したがって、Solrを使用してSolrログを分析するユーザーは、無料で時系列グラフ式を利用できます。
ルートイベント
10秒ウィンドウがログレコードにインデックスされると、ルートイベントのセットを作成するクエリを考案できます。Solrログレコードを使用した例でこれを実証できます。
この例では、平均クエリ時間が最も高い上位10個の10秒ウィンドウを見つけるストリーミング式facet集計を実行します。これらの時間ウィンドウは、時系列グラフクエリにおける遅いクエリイベントを表すために使用できます。
ファセット関数は次のとおりです。
facet(solr_logs, q="+type_s:query +distrib_s:false", buckets="time_ten_second_s", avg(qtime_i))以下は、平均クエリ時間が最も高い25個のウィンドウのスニペットです。
{
"result-set": {
"docs": [
{
"avg(qtime_i)": 105961.38461538461,
"time_ten_second_s": "2020-08-25T21:05:00Z"
},
{
"avg(qtime_i)": 93150.16666666667,
"time_ten_second_s": "2020-08-25T21:04:50Z"
},
{
"avg(qtime_i)": 87742,
"time_ten_second_s": "2020-08-25T21:04:40Z"
},
{
"avg(qtime_i)": 72081.71929824562,
"time_ten_second_s": "2020-08-25T21:05:20Z"
},
{
"avg(qtime_i)": 62741.666666666664,
"time_ten_second_s": "2020-08-25T12:30:20Z"
},
{
"avg(qtime_i)": 56526,
"time_ten_second_s": "2020-08-25T12:41:20Z"
},
...
{
"avg(qtime_i)": 12893,
"time_ten_second_s": "2020-08-25T17:28:10Z"
},
{
"EOF": true,
"RESPONSE_TIME": 34
}
]
}
}時系列二部グラフ
ルートイベントのセットを特定したら、同じ10秒ウィンドウ内で発生したログイベントタイプの二部グラフを作成するグラフクエリを簡単に実行できます。Solrログには、ログイベントの種類であるtype_sというフィールドがあります。
ルートイベントと同じ10秒ウィンドウで発生したログイベントを確認するために、10秒ウィンドウを「巡回」してtype_sフィールドを収集できます。
nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
count(*))結果は次のノードセットになります。
{
"result-set": {
"docs": [
{
"node": "query",
"count(*)": 10,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "admin",
"count(*)": 2,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "other",
"count(*)": 3,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "update",
"count(*)": 2,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "error",
"count(*)": 1,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 50
}
]
}
}この結果セットでは、nodeフィールドは、ルートイベントと同じ10秒ウィンドウ内で発生したログイベントの種類を保持しています。イベントの種類には、クエリ、管理、更新、エラーが含まれていることに注意してください。count(*)は、さまざまなログイベントの種類の次数中心性を示しています。
遅いクエリイベントと同じ10秒ウィンドウ内にエラーイベントが1つしかないことに注意してください。
ウィンドウパラメーター
イベント相関と根本原因分析において、同じ10秒間のルートイベントウィンドウ内で発生するイベントを見つけるだけでは不十分です。必要なのは、各ルートイベントの前にある時間ウィンドウ内で発生するイベントを見つけることです。windowパラメータを使用すると、この前の時間ウィンドウをクエリの一部として指定できます。windowパラメータは整数で、グラフ探索に含める各ルートイベントウィンドウの前にある10秒の時間ウィンドウの数を指定します。
nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
window="-3",
count(*))この例では、windowパラメータが負の値(-3)であることに注意してください。これにより、イベントから時間を遡って探索します。正の値のwindowパラメータは、時間を未来に遡って探索します。
以下は、windowパラメータを追加した場合に返されるノードセットです。遅いクエリイベントの前にある3つの10秒ウィンドウ内に、現在29件のエラーイベントがあることに注意してください。
{
"result-set": {
"docs": [
{
"node": "query",
"count(*)": 62,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "admin",
"count(*)": 41,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "other",
"count(*)": 48,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "update",
"count(*)": 11,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "error",
"count(*)": 29,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 117
}
]
}
}相関関係の表現としての次数
時間的二部グラフに対してリンク分析を実行することで、指定された時間ウィンドウ内で発生する各イベントタイプの次数を計算できます。二部グラフレコメンダーの例では、インバウンド次数とドット積の直接的な関係を確立しました。デジタル信号処理の分野では、ドット積は相関を表すために使用されます。したがって、時間的グラフクエリでは、インバウンド次数を、ルートイベントと指定された時間ウィンドウ内で発生するイベント間の相関関係の表現と見なすことができます。
ラグパラメータ
特定のユースケースでは、相関におけるラグを理解することが重要です。ラグ付き相関では、イベントが発生し、遅延の後にもう1つのイベントが発生します。windowパラメータは、イベントが前のウィンドウ内のどこかで発生したことを知っているだけで、遅延を捉えることはできません。
lagパラメータを使用して、過去のある数の10秒ウィンドウからwindowパラメータの計算を開始できます。たとえば、一連のルートイベントの30秒前に始まる20秒ウィンドウでグラフを探索できます。ラグを調整してクエリを再実行することで、どのラグ付きウィンドウが最も高い次数を持つのかを判断できます。これにより、遅延を判断できます。
ノードスコアリングと時間的異常検出
ノードスコアリングの概念は、時間的グラフクエリに適用して、一連のルートイベントと相関があり、ルートイベントに対して異常であるイベントを見つけることができます。次数計算により、イベント間の相関関係は確立されますが、イベントがグラフ全体で非常に頻繁に発生するかどうか、またはサブグラフに固有かどうかは確立されません。
scoreNodes関数を適用して、次数とインデックス内のノードの用語の共通性を基にノードをスコア付けることができます。これにより、イベントがルートイベントに対して異常かどうかがわかります。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
window="-3",
count(*)))以下は、scoreNodes関数を適用した後のノードセットです。ここでは、最高スコアノードがエラーイベントであることがわかります。このスコアは、根本原因分析を開始するのに役立ちます。
{
"result-set": {
"docs": [
{
"node": "other",
"nodeScore": 23.441727,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 48,
"collection": "solr_logs",
"docFreq": 99737
},
{
"node": "query",
"nodeScore": 16.957537,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 62,
"collection": "solr_logs",
"docFreq": 449189
},
{
"node": "admin",
"nodeScore": 22.829023,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 41,
"collection": "solr_logs",
"docFreq": 96698
},
{
"node": "update",
"nodeScore": 3.9480786,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 11,
"collection": "solr_logs",
"docFreq": 3838884
},
{
"node": "error",
"nodeScore": 26.62394,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 29,
"collection": "solr_logs",
"docFreq": 27622
},
{
"EOF": true,
"RESPONSE_TIME": 124
}
]
}
}日単位および曜日単位の時間ウィンドウ
日単位または曜日単位の時間ウィンドウに切り替えるには、まず、ログレコードを含む文字列フィールドに、日単位で切り捨てられたISO 8601タイムスタンプをインデックスする必要があります。以下の例では、time_day_sフィールドに日単位で切り捨てられたタイムスタンプが含まれています。
その後、windowパラメータに-3DAYSを指定するだけです。これにより、デフォルトの10秒の時間ウィンドウから日単位のウィンドウに切り替わります。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_day_s",
avg(qtime_i)),
walk="time_day_s->time_day_s",
gather="type_s",
window="-3DAYS",
count(*)))時間の前後移動時に週末をスキップする必要がある場合があります。これは、平日に取引される金融商品を関連付ける場合に役立ちます。WEEKDAYS時間ウィンドウは、指定された曜日数だけ前または後に移動します。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_day_s",
avg(qtime_i)),
walk="time_day_s->time_day_s",
gather="type_s",
window="-3WEEKDAYS",
count(*)))