結果のクラスタリング
|
クラスタリングコンポーネントの実装とAPI(パラメータ)はバージョン9.0で大幅に変更されました。Solrリリースと完全に一致するSolrガイドバージョンを参照してください。 |
クラスタリング(または**クラスタ分析**)プラグインは、関連する検索結果(ドキュメント)のグループを自動的に検出し、これらのグループに人間が読めるラベルを割り当てようとします。
Solrのクラスタリングアルゴリズムは、単一のクエリの検索結果に含まれるドキュメントに適用されます。これは、*オンライン*クラスタリングと呼ばれます。
特定のクエリに対して検出されたクラスタは、*動的ファセット*と見なすことができます。これは、通常のファセットが困難な場合(フィールド値が事前にわからない場合)またはクエリが本質的に探索的な場合に役立ちます。Carrot2プロジェクトのデモページで、検索結果のクラスタリングの動作例をご覧ください(ビジュアライゼーションのグループは、右側の検索結果で自動的に検出されており、外部情報は含まれていません)。
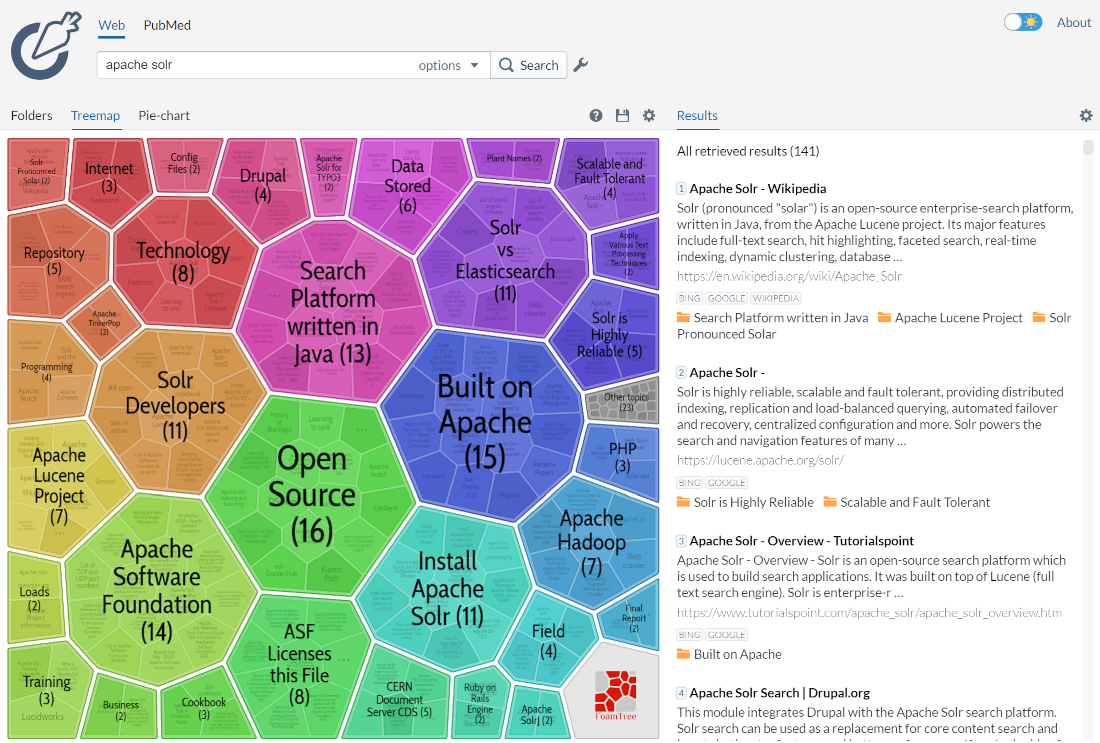
システムに発行されたクエリは*Apache Solr*でした。ファセット化の目的はユーザーが検索結果セットを探索してクエリを言い換えたり、現在のドキュメントのサブセットに焦点を絞ったりすることと似ていますが、ファセット化では同様のグループセットが得られないことは明らかです。クラスタリングは、上位数件を超えて検索結果を深く掘り下げるのに役立つという点で、結果のグループ化にも似ています。
モジュール
これは、使用する前に有効にする必要がある `clustering` Solrモジュールによって提供されます。
設定クイックスタート
クラスタリング拡張機能は検索コンポーネントとして機能します。たとえば、`solrconfig.xml`で宣言および設定する必要があります。
<searchComponent class="org.apache.solr.handler.clustering.ClusteringComponent" name="clustering">
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.fields">title, content</str>
<str name="clustering.algorithm">Lingo</str>
</lst>
</searchComponent>上記は、単一の**エンジン**でクラスタリングコンポーネントを宣言しています。実行時に複数のエンジンを宣言して切り替えることができます。エンジンの設定方法の詳細については、後ほど説明します。
クラスタリングコンポーネントは`SearchHandler`に添付し、プロパティ`clustering`を介して明示的に有効にする必要があります。以下に示すように、ハンドラのパイプラインの**最後**のコンポーネントとして添付することが重要です。
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<bool name="clustering">true</bool>
<str name="clustering.engine">lingo</str>
</lst>
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>上記例のように、クラスタリングがアタッチされると、検索ハンドラのクエリに一致するすべてのドキュメントに対して自動的にクラスタリングが実行されます。クラスタリング拡張機能は、エンジンの clustering.fields パラメータにリストされているすべてのテキストフィールドを考慮し、検出されたグループ構造を含む clusters と呼ばれるレスポンスセクションを生成します。次に例を示します(簡潔にするためにJSONレスポンスを使用)。
{
"clusters": [
{
"labels": ["Memory"],
"score": 6.80,
"docs":[ "0579B002",
"EN7800GTX/2DHTV/256M",
"TWINX2048-3200PRO",
"VDBDB1A16",
"VS1GB400C3"]},
{
"labels":["Coins and Notes"],
"score":28.560285143284457,
"docs":["EUR",
"GBP",
"NOK",
"USD"]},
{
"labels":["TFT LCD"],
"score":15.355729924203429,
"docs":["3007WFP",
"9885A004",
"MA147LL/A",
"VA902B"]}
]
}各クラスタの labels 要素は、動的に検出されたフレーズであり、docs 要素の下にあるすべてのドキュメント識別子を記述し、適用されます。
Solr ディストリビューションの例
Solr に含まれる "techproducts" の例は、結果のクラスタリングに必要なすべてのコンポーネントであらかじめ設定されていますが、デフォルトでは無効になっています。
クラスタリングコンポーネント拡張機能と、それを使用するように設定された専用の検索ハンドラを有効にするには、例を実行するときに JVM システムプロパティを指定します。
bin/solr start -e techproducts -Dsolr.clustering.enabled=trueブラウザで次の URL を開くと、クラスタリングハンドラを試すことができます。
https://:8983/solr/techproducts/clustering?q=*:*&rows=100&wt=xml
出力 XML には、検索結果と、最後に自動的に検出されたクラスタの配列が含まれている必要があります。出力はここに示されている出力に似ています。
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">299</int>
</lst>
<result name="response" numFound="32" start="0" maxScore="1.0">
<doc>
<str name="id">GB18030TEST</str>
<str name="name">Test with some GB18030 encoded characters</str>
<arr name="features">
<str>No accents here</str>
<str>这是一个功能</str>
<str>This is a feature (translated)</str>
<str>这份文件是很有光泽</str>
<str>This document is very shiny (translated)</str>
</arr>
<float name="price">0.0</float>
<str name="price_c">0,USD</str>
<bool name="inStock">true</bool>
<long name="_version_">1448955395025403904</long>
<float name="score">1.0</float>
</doc>
<!-- more search hits, omitted -->
</result>
<arr name="clusters">
<lst>
<arr name="labels">
<str>DDR</str>
</arr>
<double name="score">3.9599865057283354</double>
<arr name="docs">
<str>TWINX2048-3200PRO</str>
<str>VS1GB400C3</str>
<str>VDBDB1A16</str>
</arr>
</lst>
<lst>
<arr name="labels">
<str>iPod</str>
</arr>
<double name="score">11.959228467119022</double>
<arr name="docs">
<str>F8V7067-APL-KIT</str>
<str>IW-02</str>
<str>MA147LL/A</str>
</arr>
</lst>
<!-- More clusters here, omitted. -->
<lst>
<arr name="labels">
<str>Other Topics</str>
</arr>
<double name="score">0.0</double>
<bool name="other-topics">true</bool>
<arr name="docs">
<str>adata</str>
<str>apple</str>
<str>asus</str>
<str>ati</str>
<!-- other unassigned document IDs here -->
</arr>
</lst>
</arr>
</response>このクエリ(*:*)で検出されたいくつかのクラスタは、すべての検索結果を DDR、iPod、ハードドライブなどのさまざまなカテゴリに分類します。各クラスタには、クラスタの「良さ」を示すラベルとスコアがあります。スコアはアルゴリズム固有であり、同じセット内の他のクラスタのスコアとの関係においてのみ意味があります。言い換えれば、クラスタ A のスコアがクラスタ B より高い場合、クラスタ A の品質が優れている(ラベルが優れている、またはドキュメントセットの一貫性が高い)はずです。各クラスタには、それに属するドキュメントの識別子の配列があります。これらの識別子は、スキーマで宣言された uniqueKey フィールドに対応します。
クラスタラベルが意味をなさない場合があります(これは、クラスタ化されたフィールドのテキスト、ドキュメントの数、アルゴリズムパラメータなど、多くの要因によって異なります)。また、一部のドキュメントは除外され、まったくクラスタ化されない場合があります。これらは、other-topics プロパティが true に設定された合成の その他のトピック グループに割り当てられます(例については、上記の XML ダンプを参照してください)。その他のトピックグループのスコアはゼロです。
設定
コンポーネント設定
次のプロパティは、ClusteringComponent の状態を制御します。
clustering-
オプション
デフォルト:
falseコンポーネントは、正しく宣言され、検索ハンドラにアタッチされている場合でも、デフォルトでは無効になっています。
clusteringプロパティをtrueに設定して有効にする必要があります。これは、次のセクションで説明するように、検索ハンドラにデフォルトパラメータを設定することで実行できます。 clustering.engine-
オプション
デフォルト:説明を参照
使用するエンジンを宣言します。存在しない場合は、最初に宣言されたアクティブエンジンが使用されます。
クラスタリングエンジン
solrconfig.xml のクラスタリングコンポーネントの宣言には、エンジンと呼ばれる1つ以上の事前定義された設定を含める必要があります。たとえば、以下の設定を考えてみましょう。
<searchComponent class="org.apache.solr.handler.clustering.ClusteringComponent" name="clustering">
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">title, content</str>
</lst>
<lst name="engine">
<str name="name">stc</str>
<str name="clustering.algorithm">STC</str>
<str name="clustering.fields">title</str>
</lst>
</searchComponent>これは、2つの個別のエンジン(lingo と stc)を宣言しています。これらの設定には、異なるクラスタリングアルゴリズムと、クラスタ化されたドキュメントフィールドの異なるセットがあります。アクティブエンジンは、実行時に(URL 経由で)clustering.engine=name パラメータを渡すか、以下に示すように検索ハンドラの構成内でデフォルトとして選択できます。
<requestHandler name="/clustering" class="solr.SearchHandler">
<lst name="defaults">
<!-- Clustering component enabled. -->
<bool name="clustering">true</bool>
<str name="clustering.engine">stc</str>
<!-- Cluster the top 100 search results - bump up the 'rows' parameter. -->
<str name="rows">100</str>
</lst>
<!-- Append clustering at the end of the list of search components. -->
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>クラスタリングエンジン設定パラメータ
宣言された各エンジンは、以下に説明するいくつかのパラメータを使用して設定できます。
clustering.fields-
必須
デフォルト:なし
クラスタリングのテキストコンテンツを含む必要があるテキストフィールドの、カンマ(またはスペース)区切りのリスト。少なくとも1つのフィールドを指定する必要があります。これらのフィールドは、検索ハンドラの
flパラメータとは別であるため、クラスタ化されたフィールドをレスポンスに含める必要はありません。 clustering.algorithm-
必須
デフォルト:なし
クラスタリングアルゴリズムは、ドキュメント間の関係を発見し、人間が読めるクラスタラベルを形成する実際のロジック(実装)です。このパラメータは、このエンジンが使用するクラスタリングアルゴリズムの名前を設定します。アルゴリズムは、Carrot2定義のサービス拡張機能を介して Solr に提供されます。デフォルトでは、次のオープンソースアルゴリズムを使用できます:
Lingo、STC、Bisecting K-Means。商用クラスタリングアルゴリズムLingo3Gは同じ拡張ポイントにプラグインでき、クラスパスで使用可能な場合は使用できます。
clustering.maxLabels-
オプション
デフォルト:なし
返されるクラスタラベルの最大数(アルゴリズムがより多くのラベルを返す場合、リストは切り捨てられます)。デフォルトでは、すべてのラベルが返されます。
clustering.includeSubclusters-
オプション
デフォルト:なし
trueの場合、階層型クラスタリングをサポートするアルゴリズムのレスポンスにサブクラスタが含まれます。falseの場合、トップレベルのクラスタのみが返されます。 clustering.includeOtherTopics-
オプション
デフォルト:
truetrueの場合、他のクラスタに割り当てられていないすべてのドキュメントで構成される、その他のトピックと呼ばれる合成クラスタが形成され、返されます。この合成クラスタが不要な場合は、falseに設定できます。 clustering.resources-
オプション
デフォルト:なし
アルゴリズム固有のリソースと設定ファイル(ストップワード、その他の語彙リソース、デフォルト設定)の場所。このプロパティはデフォルトで
nullであり、すべてのリソースはそれぞれのアルゴリズムのデフォルトリソースプール(JAR)から読み取られます。このプロパティが空でない場合、Solr コアの構成ディレクトリを基準として解決されます。このパラメータは、Solr の起動時にのみ適用でき、リクエストごとに上書きすることはできません。
エンジン設定に適用されるプロパティは他にもあります。これらについては、以下の機能セクションで説明します。
フルフィールドおよびクエリコンテキスト(スニペット)クラスタリング
クラスタリングアルゴリズムは、フィールドのコンテンツ全体、またはクエリに一致する領域(いわゆるスニペット)の周囲の左右のコンテキストのみを使用できます。直感に反して、クエリコンテキストを使用すると、アルゴリズムに供給されるデータが少なくても、クラスタリングの品質が向上する可能性があります。これは通常、スニペットがクエリを囲むフレーズや用語に焦点を当てているため、アルゴリズムが処理するデータの信号対雑音比が優れているという事実が原因です。
フィールドに多くのコンテンツが含まれている場合(これはクラスタリングのパフォーマンスに影響します)、クエリコンテキストを使用することをお勧めします。
次の3つのプロパティは、コンテキストまたはフルコンテンツが処理されるかどうか、およびクラスタリング用にスニペットがどのように形成されるかを制御します。
clustering.preferQueryContext-
オプション
デフォルト:なし
trueの場合、エンジンはクエリ一致領域の周囲のコンテキストを抽出し、これらのコンテキストをクラスタリングアルゴリズムの入力として使用しようとします。 clustering.contextSize-
オプション
デフォルト:なし
コンテキスト検索アルゴリズム(内部ハイライター)によって作成された各スニペットの最大サイズ(文字数)。
clustering.contextCount-
オプション
デフォルト:なし
単一フィールドからの異なる、連続していないスニペットの最大数。
デフォルトのクラスタリング言語
Carrot2(Solr に付属)のクラスタリングアルゴリズムのデフォルト実装には、多くの言語を前処理するための組み込みサポート(ステミング、ストップワード)があります。クラスタリングアルゴリズムに、クラスタリングに使用する言語のヒントを提供することが重要です。これは、デフォルト言語の名前を渡すか、各ドキュメントにフィールドとして言語を提供するという2つの方法で実行できます。次の2つのエンジン設定パラメータはこれを制御します。
clustering.language-
オプション
デフォルト:
Englishクラスタリングに使用するデフォルト言語の名前。指定された言語が使用可能でなければならず、クラスタリングアルゴリズムがそれをサポートしている必要があります。
clustering.languageField-
オプション
デフォルト:なし
ドキュメントの言語を格納するドキュメントフィールドの名前。ドキュメントにフィールドが存在しないか、値が空白の場合、デフォルト言語が使用されます。
サポートされている言語のリストは動的に変更される可能性があり(言語は外部サービスプロバイダー拡張機能を介してロードされます)、選択したアルゴリズムによって異なる場合があります(アルゴリズムは、リソースが使用可能な言語のサブセットをサポートできます)。クラスタリングコンポーネントは、Solr の起動時にサポートされているすべてのアルゴリズムと言語のペアをログに記録するため、特定の Solr インスタンスで何がサポートされているかを確認できます。例えば
2020-10-29 [...] Clustering algorithm Lingo3G loaded with support for the following languages: Dutch, English
2020-10-29 [...] Clustering algorithm Lingo loaded with support for the following languages: Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish
2020-10-29 [...] Clustering algorithm Bisecting K-Means loaded with support for the following languages: Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish多言語コンテンツの処理
インデックス(およびクエリ結果)に複数の言語のドキュメントが含まれていることがよくあります。このような検索結果のクラスタリングは問題があります。理想的には、エンジンはドキュメントのコンテンツを翻訳(または理解)し、記述されている言語に関係なく、関連情報をまとめてグループ化する必要があります。
実際には、クラスタリングアルゴリズムは通常はるかに単純です。ドキュメントに出現する用語やフレーズの統計的特性から、ドキュメント間の類似性を推測します。そのため、異なる言語で書かれたテキストはあまりうまくクラスタ化されません。
この状況に対処するために、Solr のデフォルトのクラスタリングコンポーネント実装は、最初にすべてのドキュメントを言語別にグループ化し、次にその言語の各サブグループにクラスタリングを適用しようとします。各ドキュメントの言語を個別のフィールドとして保存し、上記で説明した clustering.languageField 設定プロパティを使用してそれを指すことをお勧めします。
アルゴリズム設定の調整
Solr に付属のクラスタリングアルゴリズムは、デフォルトのパラメータ値と言語リソースを使用します。本番環境での使用には、両方を調整することを強くお勧めします。デフォルトの言語リソースを改善して、特定のドキュメントドメインに共通の単語やフレーズを含めると、クラスタリングの品質が大幅に向上します。
Carrot2 アルゴリズムには、広範なパラメータと言語リソースの調整オプションがあります。最新のプロジェクトドキュメントを参照してください。特に、言語リソースセクションと各アルゴリズムの属性セクション。
クラスタリングアルゴリズムパラメータの変更
クラスタリングアルゴリズムの設定は、Solr パラメータを介して永続的に(エンジンの宣言で)またはリクエストごとに(Solr URL パラメータを介して)変更できます。
たとえば、次のエンジン設定があるとします。
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
</lst>まず、Carrot2 ドキュメントサイトで Lingo アルゴリズムの設定パラメータを見つけます。
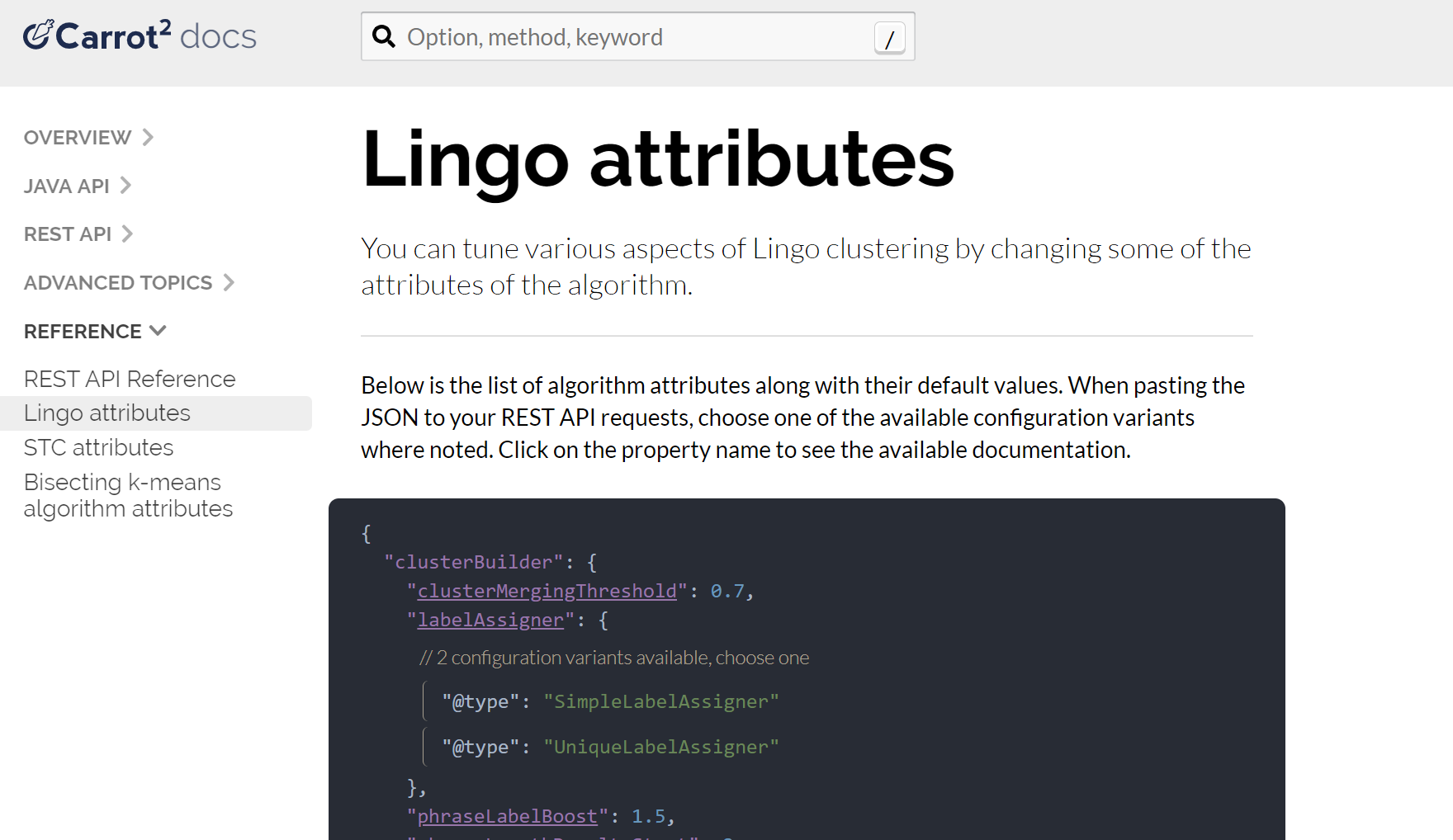
次に、変更したい特定の設定を見つけ、その設定への REST API パスをメモします(この場合、パラメータは minClusterSize で、パスは preprocessing.documentAssigner.minClusterSize です)。

次に、完全なパスと値のペアをエンジンの設定に追加します。
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
<int name="preprocessing.documentAssigner.minClusterSize">3</int>
</lst>以下のルールが適用されます。
-
パラメータの型は、Carrot2 仕様に記載されている型と一致している必要があります。
-
パラメータが
solrconfig.xml内のエンジンの設定に追加された場合、変更を反映するにはコアをリロードする必要があります。または、リクエスト URL 経由でパラメータを渡して、リクエストごとに動的に変更することもできます。たとえば、「techproducts」の例を実行している場合、これは少なくとも 3 つのドキュメントを含むクラスタのみに絞り込みます:https://:8983/solr/techproducts/clustering?q=*:*&rows=100&wt=json&preprocessing.documentAssigner.minClusterSize=3 -
複合型の場合、インスタンス化された型の名前を持つパラメータキーは、独自のパラメータの前に付ける必要があります。
カスタム言語リソース
クラスタリングアルゴリズムは、言語およびドメイン固有の言語リソースに依存して、クラスタの品質を向上させます(ドメイン固有のノイズや定型的な言語を破棄することにより)。
デフォルトでは、言語リソースはエンジンで宣言されたアルゴリズムのデフォルト JAR から読み取られます。 clustering.resources パラメータを指定することで、これらのリソースのカスタムの場所を渡すことができます。このパラメータの値は、Solr コアの設定ディレクトリからの相対パスに解決されます。たとえば、次の定義は
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
<str name="clustering.resources">lingo-resources</str>
</lst>次のログエントリと予想されるリソースの場所になります
Clustering algorithm resources first looked up relative to: [.../example/techproducts/solr/techproducts/conf/lingo-resources]アルゴリズムリソースの調整を開始する最良の方法は、対応する Carrot2 JAR ファイル(または Carrot2 ディストリビューション)からすべてのデフォルトをコピーすることです。
パフォーマンスに関する考慮事項
検索結果のクラスタリングには、いくつかのパフォーマンスに関する考慮事項があります。
-
通常よりも多い数の検索結果(50、100以上のドキュメント)を取得するコスト、
-
クラスタリング自体の追加の計算コスト。
-
分散モードでは、クラスタリング対象のドキュメントフィールドの内容はシャードから収集され、ネットワークオーバーヘッドがいくらか追加されます。
単純なクエリの場合、クラスタリング時間が通常は他のすべてを支配します。ドキュメントフィールドが非常に長い場合、格納されたコンテンツの取得がボトルネックになる可能性があります。
クラスタリングのパフォーマンスへの影響は、いくつかの方法で軽減できます。
-
クラスタリングするデータ量を減らす:完全なフィールドコンテンツの代わりにクエリコンテキスト(スニペット)を使用する(
clustering.preferQueryContext=true)。 -
ドキュメントフィールドのサブセットのみでクラスタリングを実行するか、クラスタリング用のフィールドをキュレートする(インデックス時に要約を追加する)ことで、入力を小さくします。
-
特定のアルゴリズムに直接関連するパフォーマンス属性を調整します。
-
異なる、より高速なアルゴリズムを試す(Lingo の代わりに STC、STC の代わりに Lingo3G)。
追加リソース
以下のリソースは、Solr のクラスタリングコンポーネントとその潜在的なアプリケーションに関する追加情報を提供します。
-
Solr 検索結果のクラスタリングと視覚化(Berlin BuzzWords カンファレンス、2011):http://2011.berlinbuzzwords.de/sites/2011.berlinbuzzwords.de/files/solr-clustering-visualization.pdf