GKE 上での Apache Solr Operator v0.3.0 の探求
著者: Tim Potter
今年初めに、Bloomberg は Solr Operator を Apache Software Foundation に寛大にも寄付しました。最新のv0.3.0 リリースは、Apache 傘下での最初のリリースであり、Apache Solr コミュニティ全体にとって重要なマイルストーンとなります。この Operator は、Solr の最初のサテライトプロジェクトであり、Solr PMC によって管理されますが、Apache Solr とは独立してリリースされます。コミュニティは、大規模な Solr 運用で得られた貴重な教訓とベストプラクティスを、Kubernetes 上の自動化されたソリューションに変換するための強力な手段を手に入れました。
はじめに
この投稿では、適切に構成された Solr クラスタを Kubernetes にデプロイする必要がある DevOps エンジニアの視点から、v0.3.0 リリースについて探求します。
Solr Operator を使用すると、Kubernetes 上で Solr を簡単に開始できます。ローカルチュートリアルに従えば、すぐにローカルで Solr クラスタを稼働させることができます。しかし、本番環境への展開には、セキュリティ、高可用性、パフォーマンス監視という3つの追加の懸念事項が考えられます。このガイドの目的は、これらの重要な本番環境に関する懸念事項の計画と実装を支援することです。
詳細に入る前に、下記の図を確認してください。この図は、Operator によって Kubernetes にデプロイされた Solr クラスタの主要なコンポーネント、構成、および相互作用を示しています。もちろん、他にも多くの Kubernetes オブジェクト(シークレット、サービスアカウントなど)が関わっていますが、この図は主要なオブジェクトのみを示しています。
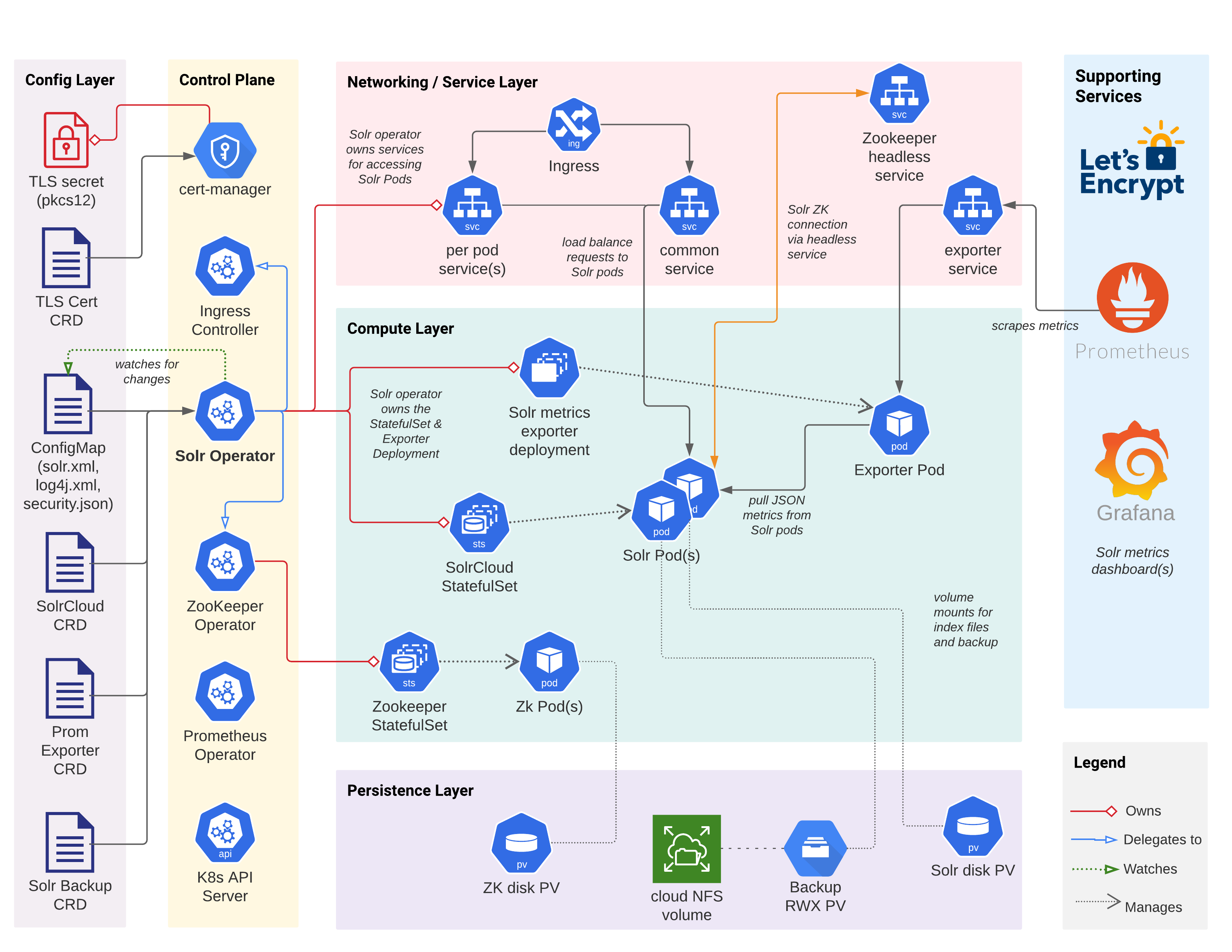
はじめに
Solr Operator、Solr クラスタ、およびサポートサービスの基本的なデプロイを GKE 上で実行してみましょう。私は Google と正式な関係はありませんが、この投稿では使いやすさのために GKE を使用しています。ただし、Amazon の EKS や AKS などの他のクラウド管理 Kubernetes でも、同じ基本的なプロセスが機能します。このドキュメントのセクションを進めていく中で、この初期構成を改善していきます。最後に、クラウドで本番環境対応の Solr クラスタを実行するために必要な CRD 定義とサポートスクリプトを用意します。
Kubernetes の設定
自宅で一緒に作業することをお勧めしますので、GKE クラスタを起動し、ターミナルを開いてください。GKE を初めて使用する場合は、このドキュメントに進む前にGKE クイックスタートをよく理解してください。より優れた HA を実現するには、3 つのゾーンにまたがる**リージョン** GKE クラスタをデプロイする必要があります(ゾーンごとに少なくとも 1 つの Solr ポッド)。もちろん、開発/テスト目的で 1 つのゾーンにゾーナルクラスタをデプロイできますが、私が示す例は、us-central1 リージョンで実行され、3 つのゾーンのそれぞれに 1 つのノードを持つ 3 ノードの GKE クラスタに基づいています。
開始するには、nginx ingress コントローラーを ingress-nginx 名前空間にインストールする必要があります。
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.45.0/deploy/static/provider/cloud/deploy.yaml
詳細については、GKE への Nginx Ingress のデプロイを参照してください。
イングレスコントローラーが正常に動作していることを確認するには、次のコマンドを実行します。
kubectl get pods -l app.kubernetes.io/name=ingress-nginx -n ingress-nginx \
--field-selector status.phase=Running
次のような期待される出力が見られるはずです。
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-6c94f69c74-fxzp7 1/1 Running 0 6m23s
このドキュメントでは、Operator と Solr をsop030という名前空間へデプロイします。
kubectl create ns sop030
kubectl config set-context --current --namespace=sop030
Solr Operator の設定
以前のバージョンの Solr Operator をインストールした場合は、次の手順を使用してApache Solrバージョンにアップグレードしてください。Apache へのアップグレード。それ以外の場合は、Apache Solr Helm リポジトリを追加し、Solr CRDをインストールし、Solr Operator をインストールします。
helm repo add apache-solr https://solr.apache.org/charts
helm repo update
kubectl create -f https://solr.apache.org/operator/downloads/crds/v0.3.0/all-with-dependencies.yaml
helm upgrade --install solr-operator apache-solr/solr-operator \
--version 0.3.0
この時点で、名前空間に Solr Operator ポッドが実行されていることを確認します。
kubectl get pod -l control-plane=solr-operator
kubectl describe pod -l control-plane=solr-operator
ID でポッドをアドレス指定する代わりに、ラベルセレクターフィルターを使用していることに注意してください。これにより、ポッドの詳細を取得するために ID を調べる必要がなくなります。
名前空間にZookeeper Operatorポッドも実行されているはずです。次を使用して確認してください。
kubectl get pod -l component=zookeeper-operator
Solr CRD
カスタムリソース定義(CRD)を使用すると、アプリケーション開発者は Kubernetes に新しいタイプのオブジェクトを定義できます。これにはいくつかの利点があります。
- ドメイン固有の構成設定を運用担当者に公開します。
- 定型コードを削減し、実装の詳細を隠蔽します。
- kubectl を使用して CRD に対して CRUD 操作を実行します。
- 他の K8s リソースと同様に etcd に保存され、管理されます。
Solr Operator は、SolrCloud リソース、メトリクスエクスポーターリソース、バックアップ/リストアリソースなど、Solr 固有のオブジェクトを表す CRD を定義します。SolrCloud CRD は、Kubernetes 名前空間に Solr クラスタをデプロイおよび管理するために必要な構成設定を定義します。最初に、kubectl を使用して SolrCloud CRD を見てみましょう。
# get a list of all CRDs in the cluster
kubectl get crds
# get details about the SolrCloud CRD Spec
kubectl explain solrclouds.spec
kubectl explain solrclouds.spec.solrImage
# get details about the SolrCloud CRD Status
kubectl explain solrclouds.status
上記のexplainコマンドからの出力を確認してください。さまざまな構造とフィールドは、なじみのあるものに見えるはずです。自由に掘り下げて、SolrCloud CRD の Spec と Status のさまざまな部分を調べてください。
Solr Cloud の作成
Kubernetes 名前空間に SolrCloud オブジェクトのインスタンスをデプロイするには、以下に示す例のような YAML を作成します。
apiVersion: solr.apache.org/v1beta1
kind: SolrCloud
metadata:
name: explore
spec:
customSolrKubeOptions:
podOptions:
resources:
limits:
memory: 3Gi
requests:
cpu: 700m
memory: 3Gi
dataStorage:
persistent:
pvcTemplate:
spec:
resources:
requests:
storage: 2Gi
reclaimPolicy: Delete
replicas: 3
solrImage:
repository: solr
tag: 8.8.2
solrJavaMem: -Xms500M -Xmx500M
updateStrategy:
method: StatefulSet
zookeeperRef:
provided:
chroot: /explore
image:
pullPolicy: IfNotPresent
repository: pravega/zookeeper
tag: 0.2.9
persistence:
reclaimPolicy: Delete
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
replicas: 3
zookeeperPodPolicy:
resources:
limits:
memory: 500Mi
requests:
cpu: 250m
memory: 500Mi
Solr と Zookeeper のリソース要求/制限とディスクサイズに十分注意してください。各 Solr ポッドに適切な量のメモリ、CPU、ディスクを割り当てることは、クラスタを設計する際の重要なタスクです。もちろん、Kubernetes を使用すれば必要に応じてポッドを追加できますが、ポッドをデプロイする前に、ユースケースに合った適切なリソース要求/制限とディスクサイズを見積もる必要があります。本番環境のサイジングは、このドキュメントの範囲外であり、ユースケースごとに大きく異なります(通常は現実的な負荷テストを実行して試行錯誤が必要です)。
SolrCloud YAML で注目すべき点は、設定の大部分が Solr 固有であり、過去に Solr を使用したことがある場合は自己説明的であることです。運用チームは、この YAML をソース管理に保持し、Kubernetes で SolrCloud クラスタを作成するプロセスを自動化できます。バックアップ/復元や Prometheus エクスポーター CRD 定義などの SolrCloud YAML と関連オブジェクトを管理するために、Helm チャートを作成することもできます。
シェルを開き、次のコマンドを実行して Operator ポッドのログを監視します。
kubectl logs -l control-plane=solr-operator -f
ID でポッドをアドレス指定する代わりに、ラベルセレクター(-l ...)を使用していることに注意してください。これにより、Operator ログを表示するたびにポッド ID を探す必要がなくなります。
explore SolrCloud を K8s にデプロイするには、上記の YAML をexplore-SolrCloud.yamlという名前のファイルに保存し、別のシェルタブで次のコマンドを実行します。
kubectl apply -f explore-SolrCloud.yaml
このドキュメントの残りの部分で、explore-SolrCloud.yamlファイルを更新します。
"spec:"で始まるコードセクションは、このファイルを参照しています。
この SolrCloud 定義を Kubernetes API サーバーに送信すると、ウォッチャーのようなメカニズムを使用して Solr Operator(名前空間にポッドとして実行)に通知されます。これにより、Operator で調整プロセスが開始され、explore SolrCloud クラスタを実行するために必要なさまざまな K8s オブジェクトが作成されます(上記の図を参照)。SolrCloud インスタンスがデプロイされる際に、Operator のログを簡単に確認してください。
CRD の主な利点の1つは、ネイティブの K8s オブジェクトと同様にkubectlを使用して対話できることです。
$ kubectl get solrclouds
NAME VERSION TARGETVERSION DESIREDNODES NODES READYNODES AGE
explore 8.8.2 3 3 3 73s
$ kubectl get solrclouds explore -o yaml
バックグラウンドでは、Operator は、Solr ポッドのセットを管理するためのStatefulSetを作成しました。次を使用してexplore StatefulSet を見てみましょう。
kubectl get sts explore -o yaml
この初期 SolrCloud 定義では、わずかに微妙な設定に依存しています。
updateStrategy:
method: StatefulSet
既存の SolrCloud で TLS を有効にするために、updateStrategyメソッドをStatefulSetで開始する必要があります。TLS を有効にした後、HA セクションでこれをManagedに変更します。Managedを使用するには、Operator がコレクション API を呼び出してCLUSTERSTATUSを取得する必要がありますが、クラスタが HTTP から HTTPs に変換されている間は機能しません。実際のデプロイでは、既存のクラスタで TLS にアップグレードするのではなく、最初に TLS を有効にして開始する必要があります。
また、クラスタをロックダウンしてから先に進むため、まだコレクションを作成したり、データを読み込んだりしないようにしましょう。
Zookeeper 接続
Solr Cloud は Apache Zookeeper に依存しています。explore SolrCloud 定義では、提供済みオプションを使用しています。これは、Solr Operator が SolrCloud インスタンスに Zookeeper アンサンブルを提供することを意味します。バックグラウンドでは、Solr Operator はZookeeperCluster CRD インスタンスを定義し、Zookeeper Operator によって管理されます。providedオプションは、開始と開発に役立ちますが、Zookeeper Operator でサポートされているすべての構成オプションを公開するわけではありません。本番環境へのデプロイメントでは、SolrCloud CRD 定義の外側で独自のZookeeperClusterを定義し、spec.zookeeperRefの下のconnectionInfoを使用して Zookeeper アンサンブル接続文字列を指すことを検討してください。これにより、Zookeeper クラスタのデプロイメントを完全に制御でき、複数の SolrCloud インスタンス(およびその他のアプリケーション)が同じ Zookeeper サービスを共有できるようになり(もちろん異なる chroot を使用)、懸念事項の適切な分離が実現されます。あるいは、Solr Operator は Zookeeper Operator を必要としないため、Zookeeper Operator がニーズを満たしていない場合は、Helm チャートを使用して Zookeeper クラスタをデプロイできます。
カスタム Log4J 構成
先に進む前に、ユーザー提供の ConfigMap からカスタム Log4j 構成を読み込むことができる Operator の便利な機能について説明しておきます。本番環境で問題のトラブルシューティングに役立つように、Solr の Log4j 構成をカスタマイズする必要がある状況に直面する可能性があるため、この機能について説明します。ここでは詳細には触れませんが、カスタムログ構成のドキュメントを使用して、独自の Log4J 構成を構成してください。
セキュリティ
セキュリティは常に最優先事項であるべきです。特に GKE のようなパブリッククラウドで実行する場合、システムが侵害される運用エンジニアにならないようにする必要があります。このセクションでは、Solr の API エンドポイントに対して TLS、基本認証、および認可制御を有効にします。すべての構成オプションの詳細については、SolrCloud CRDのドキュメントを参照してください。
SolrでTLSを有効にするには、公開X.509証明書と秘密鍵を含むTLSシークレットを用意するだけです。Kubernetesエコシステムは、証明書の発行と管理のための強力なツールを提供します。 cert-manager。クラスタにまだインストールされていない場合は、Solrオペレータによって提供される基本手順に従って、最新バージョンのcert-managerをインストールしてください。証明書の発行にcert-managerを使用する。
Cert-managerとLet’s Encrypt
まず、自己署名証明書から始めましょう。自己署名発行者(cert-manager CRD)、証明書(cert-manager CRD)、およびキーストアパスワードを保持するシークレットを作成する必要があります。次のYAMLをファイルに保存し、kubectl apply -fを使用して適用します。
---
apiVersion: v1
kind: Secret
metadata:
name: pkcs12-keystore-password
stringData:
password-key: Test1234
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: selfsigned-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: explore-selfsigned-cert
spec:
subject:
organizations: ["self"]
dnsNames:
- localhost
secretName: explore-selfsigned-cert-tls
issuerRef:
name: selfsigned-issuer
keystores:
pkcs12:
create: true
passwordSecretRef:
key: password-key
name: pkcs12-keystore-password
証明書に対してPKCS12キーストアを生成するように要求したことに注意してください
keystores:
pkcs12:
create: true
これは、Javaベースのアプリケーションを使用する場合のcert-managerの優れた機能です。JavaはPKCS12をネイティブに読み取ることができますが、cert-managerが自動的にこれを実行しない場合、keytoolを使用してtls.crtファイルとtls.keyファイルをコンバートする必要があります。
Cert-managerは、Solrで使用されるX.509証明書、秘密鍵、およびPKCS12準拠のキーストアを含むKubernetesシークレットを作成します。次のコマンドを使用して、シークレットの内容を検査してください。
kubectl get secret explore-selfsigned-cert-tls -o yaml
explore-SolrCloud.yaml内のSolrCloud CRD定義を更新してTLSを有効にし、キーストアを保持するシークレットを指定します。
spec:
...
solrAddressability:
commonServicePort: 443
external:
domainName: YOUR_DOMAIN_NAME_HERE
method: Ingress
nodePortOverride: 443
useExternalAddress: false
podPort: 8983
solrTLS:
restartOnTLSSecretUpdate: true
pkcs12Secret:
name: explore-selfsigned-cert-tls
key: keystore.p12
keyStorePasswordSecret:
name: pkcs12-keystore-password
key: password-key
Ingress経由でSolrを外部に公開し、一般的なサービスポートを443に変更していることにも注意してください。これは、TLS対応サービスを使用する場合により直感的です。SolrCloud CRDへの変更を適用するには、次のコマンドを使用します。
kubectl apply -f explore-SolrCloud.yaml
これにより、自己署名証明書を使用してTLSを有効にするために、Solrポッドのローリングリスタートがトリガーされます。Solrポッドの1つ(ポート8983)にポートフォワードを開き、次のコマンドを実行して、SolrがHTTPS経由でトラフィックを提供していることを確認します。
curl https://:8983/solr/admin/info/system -k
Let’s Encrypt発行のTLS証明書
自己署名証明書はローカルテストに最適ですが、Web上でサービスを公開するには、信頼できるCAによって発行された証明書が必要です。所有するドメインのSolrクラスタに対して証明書を発行するために、Let’s Encryptを使用します。Solrクラスタのドメイン名がない場合は、このセクションをスキップし、必要に応じて参照してください。ここで使用しているプロセスは、次のドキュメントに基づいています。GoogleのACME DNS01レゾルバー。
GKE環境用に作成したLet’s Encrypt発行者はこちらです。
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: acme-letsencrypt-issuer
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email: *** REDACTED ***
privateKeySecretRef:
name: acme-letsencrypt-issuer-pk
solvers:
- dns01:
cloudDNS:
project: GCP_PROJECT
serviceAccountSecretRef:
name: clouddns-dns01-solver-svc-acct
key: key.json
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: explore-solr-tls-cert
spec:
dnsNames:
- YOUR_DOMAIN_NAME_HERE
issuerRef:
kind: Issuer
name: acme-letsencrypt-issuer
keystores:
pkcs12:
create: true
passwordSecretRef:
key: password-key
name: pkcs12-keystore-password
secretName: explore-solr-tls-letsencrypt
subject:
countries:
- USA
organizationalUnits:
- k8s
organizations:
- solr
証明書発行者の作成には、通常、プラットフォーム固有の構成が必要です。GKEの場合、DNS01レゾルバーを使用していることに注意してください。これは、DNS管理者権限を持つサービスアカウントの資格情報が必要です。これは、GCPコンソールまたはgcloud CLIを使用して構成する必要があります。私の環境では、資格情報はclouddns-dns01-solver-svc-acctという名前のシークレットに保存されています。
cert-managerポッド(cert-manager名前空間内)のログをtailコマンドで確認して、発行プロセスの進捗状況を追跡できます。
kubectl logs -l app.kubernetes.io/name=cert-manager -n cert-manager
Let's EncryptによってTLS証明書が発行されたら、(上記の自己署名プロセスを実行したと仮定して)SolrCloudインスタンスを再構成し、Ingress経由でSolrを公開し、cert-managerによって作成されたTLSシークレットに保存されている証明書と秘密鍵を含むPKCS12キーストアを使用します。
spec:
...
solrTLS:
pkcs12Secret:
name: explore-solr-tls-letsencrypt
key: keystore.p12
最後のステップは、IngressのIPアドレスをIngressのホスト名にマップするDNS Aレコードを作成することです。
mTLS
SolrオペレータはmTLS対応のSolrクラスタをサポートしていますが、このドキュメントの範囲を超えています。mTLSの構成については、Solrオペレータのドキュメントを参照してください。
認証と認可
前のセクションの手順に従った場合、Solrポッド間の通信は暗号化されますが、着信リクエストにユーザーID(認証)があり、要求しているユーザーがリクエストの実行を承認されていることを確認する必要もあります。v0.3.0以降、Solrオペレータは基本認証とSolrのルールベースの認可制御をサポートしています。
開始する最も簡単な方法は、オペレータに基本認証と認可制御をブートストラップさせることです。詳細な手順については、次のドキュメントを参照してください。認証と認可
spec:
...
solrSecurity:
authenticationType: Basic
オペレータは、admin、k8s-oper、solrの3人のSolrユーザーの資格情報を構成します。
次のコマンドを実行して、adminユーザーとしてSolr管理Web UIにログインします。
kubectl get secret explore-solrcloud-security-bootstrap \
-o jsonpath='{.data.admin}' | base64 --decode
この時点で、Solrポッド内とポッド間のすべてのトラフィックはTLSを使用して暗号化され、APIエンドポイントはSolrのルールベースの認可制御と基本認証によってロックダウンされます。Solrが適切にロックダウンされたので、高可用性(HA)の構成に進みましょう。
高可用性
このセクションでは、KubernetesでSolrポッドの高可用性を実現するためのいくつかの重要なトピックについて説明します。ノードの可用性を確保することは、方程式の一部に過ぎません。高可用性が必要な各コレクションの各シャードのレプリカがポッドに適切に分散されていることを確認する必要もあります。そうすることで、ノードの損失、またはゾーン全体の損失でさえ、サービスの中断につながることはありません。ただし、障害が発生した場合にいくつかのレプリカをオンラインの状態に維持することは、ある程度までしか役に立ちません。ある時点で、健全なレプリカはリクエストによって過負荷になる可能性があるため、実装する可用性戦略では、健全なレプリカへの負荷の急増にも対応する必要があります。
ポッドアンチアフィニティ
Solrオペレータを使用した高可用性の調査を開始するために、ポッドアンチアフィニティを使用して、Solrポッドがクラスタに均等に分散されるようにしましょう。
必要なSolrポッドの数を決定したら、ランダムなノード障害とゾーンレベルの障害(マルチゾーンクラスタの場合)に耐えるために、クラスタ全体にポッドをバランスよく分散する必要があります。ポッドアンチアフィニティルールを使用します。
クラスタ内の各ノードのゾーンを確認するには、次のコマンドを実行します。
kubectl get nodes -L topology.kubernetes.io/zone
次のpodAntiAffinityの例では、solr-cloud=exploreラベルセレクターに一致するポッドは、クラスタ内の異なるノードとゾーンに分散されます。
ヒント:Solrオペレータは、すべてのポッドにSolrCloudインスタンスの名前を「solr-cloud」ラベルとして設定します。
spec:
...
customSolrKubeOptions:
podOptions:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: "technology"
operator: In
values:
- solr-cloud
- key: "solr-cloud"
operator: In
values:
- explore
topologyKey: topology.kubernetes.io/zone
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "technology"
operator: In
values:
- solr-cloud
- key: "solr-cloud"
operator: In
values:
- explore
topologyKey: kubernetes.io/hostname
明らかに、3つのゾーンに3つのノードがあり、3つのSolrポッドがある場合、これはあまり重要ではありません。ホスト名アンチアフィニティルールだけでバランスの取れた分散が得られます。大規模なクラスタでは、ホスト名とゾーンの両方のルールを持つことが重要です。
マルチゾーンクラスタを実行していない場合は、topology.kubernetes.io/zoneに基づくルールを削除できます。さらに、このルールは、Kubernetesが他の健全なゾーンに置換ノードとポッドをスピンアップできるように、ハード要件ではなく優先事項にする必要があると考えています。
また、既存のSolrCloudにこれらのアンチアフィニティルールを適用すると、Solrディスクに使用されている基盤となる永続ボリュームクレーム(PVC)がゾーンにピン留めされているため、ポッドのスケジューリングの問題が発生する可能性があります。新しいアンチアフィニティルールに基づいて別のゾーンに移動するSolrポッドは、再アタッチする必要があるPVCが元のゾーンにしか存在しないため、Pending状態になります。したがって、SolrCloudクラスタをロールアウトする前に、ポッドアフィニティルールを計画しておくことをお勧めします。
クラスタ内の使用可能なノードよりも多くのSolrポッドが必要な場合は、kubernetes.io/hostnameに基づくルールにrequiredDuringSchedulingIgnoredDuringExecutionではなくpreferredDuringSchedulingIgnoredDuringExecutionを使用する必要があります。Kubernetesはポッドをノードに均等に分散しようとしますが、複数のポッドがいつか同じノードにスケジュールされます(明らかに)。
「explore」SolrCloudに3つのレプリカを要求したと仮定すると、3つのゾーンにポッドが均等に分散されます。次のコマンドを実行して、Solrポッドが実行されている一意のノードの数を確認し、その数を数えます。
kubectl get po -l solr-cloud=explore,technology=solr-cloud \
-o json | jq -r '.items | sort_by(.spec.nodeName)[] | [.spec.nodeName] | @tsv' | uniq | wc -l
出力は次のようになります:3
ゾーンにも分散するために、Zookeeperポッドにも同様のアンチアフィニティ構成を使用する必要があります。
ゾーン対応レプリカ配置
クラスタのポッドのサイズが適切に調整され、HAを促進するためにクラスタ全体に分散されたら、HAが必要なコレクションのすべてのレプリカが配置されていることを確認する必要があります。言い換えれば、クラスタレイアウトを利用するために、同じシャードのすべてのレプリカが同じノードまたはゾーンに配置される場合、クラスタ全体にポッドを分散しても意味がありません。Solr側では、開始するための良いルールは、次のものを使用して、同じシャードのレプリカが他のホストを優先することです。
{"node": "#ANY", "shard": "#EACH", "replica":"<2"},
このルールやその他のタイプのルールについては、Solr自動スケーリングを参照してください。
コレクションをオーバーシャーディングしている場合、つまり、合計レプリカ数がポッド数よりも多い場合、ノードレベルの自動スケーリングルールでカウントのしきい値を緩和する必要がある可能性があります。
注:Solr自動スケーリングフレームワークは8.xで非推奨となり、9.xでは削除されました。ただし、このドキュメントでレプリカ配置に利用するルールは、9.xで利用可能なAffinityPlacementPluginに置き換えられました。詳細については、solr/core/src/java/org/apache/solr/cluster/placement/plugins/AffinityPlacementFactory.javaを参照してください。
マルチAZクラスタでは、StatefulSet内の各Solrポッドには、そのポッドのゾーンを識別する一意のラベルであるavailability_zone Javaシステムプロパティを設定する必要があります。availability_zoneプロパティは、自動スケーリングルールで使用して、SolrCloudクラスタ内のすべての使用可能なゾーンにレプリカを分散できます。
{"replica":"#EQUAL", "shard":"#EACH", "sysprop.availability_zone":"#EACH"},
Solrポッドのサービスアカウントにノードの取得権限がある場合、Downward APIを使用してノードメタデータからゾーンを取得できます。ただし、多くの管理者はこの権限を与えることをためらっています。 http://metadata.google.internal/computeMetadata/v1/instance/zone APIをcurlするGCP固有のソリューションを以下に示します。
spec:
...
customSolrKubeOptions:
podOptions:
initContainers: # additional init containers for the Solr pods
- name: set-zone # GKE specific, avoids giving get nodes permission to the service account
image: curlimages/curl:latest
command:
- '/bin/sh'
- '-c'
- |
zone=$(curl -sS http://metadata.google.internal/computeMetadata/v1/instance/zone -H 'Metadata-Flavor: Google')
zone=${zone##*/}
if [ "${zone}" != "" ]; then
echo "export SOLR_OPTS=\"\${SOLR_OPTS} -Davailability_zone=${zone}\"" > /docker-entrypoint-initdb.d/set-zone.sh
fi
volumeMounts:
- name: initdb
mountPath: /docker-entrypoint-initdb.d
volumes:
- defaultContainerMount:
mountPath: /docker-entrypoint-initdb.d
name: initdb
name: initdb
source:
emptyDir: {}
initContainerがset-zone.shスクリプトを/docker-entrypoint-initdb.dに追加することに注意してください。Docker Solrフレームワークは、Solrの開始前にこのディレクトリ内のスクリプトをソースします。同様のアプローチをEKSにも適用できます(http://169.254.169.254/latest/dynamic/instance-identity/documentの出力を参照)。もちろん、プラットフォーム固有のアプローチを使用することは理想的ではありませんが、ノードの取得権限を与えることも理想的ではありません。重要なのは、システムで機能するアプローチを使用してavailability_zoneシステムプロパティを設定することです。
Solr 8.2に追加されたnode.sysprop shardPreferenceを使用して、分散クエリが同じゾーン内の他のレプリカを優先するようにする必要があります。このクエリルーティングの優先順位は、両方のゾーンが正常な場合にゾーンを跨ぐクエリを削減するのにも役立ちます。詳細については、Solrリファレンスガイド- シャードの優先順位を参照してください。
availability_zoneシステムプロパティを使用してレプリカ配置に影響を与える自動スケーリングポリシーを適用することは、読者の課題として残しておきます。
レプリカの種類
オペレーターを使用して複数のSolrCloudインスタンスをデプロイする場合、それらがすべて同じZooKeeper接続文字列(およびchroot)を使用すると、Solrの観点からは単一のSolr Cloudクラスタとして動作します。このアプローチを使用して、Kubernetesクラスタ内の異なるノードにSolrポッドを割り当てることができます。たとえば、書き込みトラフィックと読み取りトラフィックを分離するために、TLOGレプリカをあるノードセットで、PULLレプリカを別のノードセットで実行する場合があります(参照:レプリカの種類)。レプリカの種類によるトラフィックの分離はこのドキュメントの範囲外ですが、オペレーターを使用して複数のSolrCloudインスタンスをデプロイすることで、その分離を実現できます。各インスタンスには、solr_node_typeなどのJavaシステムプロパティを設定して、Solrポッドを互いに区別する必要があります。Solrの自動スケーリングポリシーエンジンは、システムプロパティを使用してタイプ別にレプリカを割り当てることをサポートしています。
ローリングリスタート
オペレーターの主な利点の1つは、アプリケーション固有の状態を考慮に入れるために、Kubernetesのデフォルトの動作を拡張できることです。たとえば、StatefulSetのローリングリスタートを実行する場合、K8sは最も高い序数を持つポッドから開始して0まで順に処理し、再開されたポッドが実行中状態になるまで待機します。このアプローチは機能しますが、通常、大規模クラスタでは遅すぎ、そのノード上のレプリカが回復しているかどうかを知らずに実行すると有害になる可能性があります。
これとは対照的に、オペレーターはStatefulSetのローリングリスタート操作を強化し、どのSolrポッドがオーバーシーアをホストしているか(最後に再起動)、ポッド上のリーダーの数などを考慮します。その結果、複数のポッドを同時に再起動できる、SolrCloudの最適化されたローリングリスタートプロセスが実現します。オペレーターはSolrのクラスタステータスAPIを使用して、同時に再起動するポッドを決定する際に、すべてのシャード*について少なくとも1つのレプリカがオンラインであることを確認します。さらに、これらのカスタムの調整プロセスは、Kubernetesで非常に重要なべき等性の概念に従います。同じ開始状態が与えられた場合、調整を100回呼び出すことができますが、結果は1回目と100回目で同じになります。
最初にStatefulSet方式を使用して、既存のクラスタをTLSを使用するように移行したことを思い出してください。次の設定を使用して、それをManaged方式に変更しましょう。
spec:
...
updateStrategy:
managed:
maxPodsUnavailable: 2
maxShardReplicasUnavailable: 2
method: Managed
explore-SolrCloud.yamlにこれを追加して、変更を適用します。
* 上で見たように、Managed更新戦略はカスタマイズ可能であり、必要な安全レベルまたは速度レベルに設定できます。詳細については、更新ドキュメントを参照してください。
パフォーマンスモニタリング
これで、Solrオペレーターによってデプロイおよび管理される、安全でHA対応のSolrクラスタができました。最後に取り上げたいのは、Prometheusスタックを使用したパフォーマンスモニタリングです。
Prometheusスタック
おそらく、すでにPrometheusを使用してモニタリングを行っていると思いますが、クラスタにインストールされていない場合は、インストール手順を使用して、Grafanaを含むPrometheusスタックをインストールしてください。
Prometheusエクスポーター
オペレーターのドキュメントでは、SolrCloudインスタンスのPrometheusエクスポーターをデプロイする方法について説明しています。基本認証とTLSを有効にしたため、次の設定を使用して、エクスポーターが安全なSolrポッドと通信できるようにする必要があります。
solrReference:
cloud:
name: "explore"
basicAuthSecret: explore-solrcloud-basic-auth
solrTLS:
restartOnTLSSecretUpdate: true
pkcs12Secret:
name: explore-selfsigned-cert-tls
key: keystore.p12
keyStorePasswordSecret:
name: pkcs12-keystore-password
key: password-key
自己署名証明書を使用しているか、Let's Encryptなど別のCAが発行した証明書を使用しているかによって、pkcs12Secret.nameが正しいことを確認してください。
Prometheusオペレーターがメトリクスをスクレイピングするサービスが正しいことを確認してください。
kubectl get svc -l solr-prometheus-exporter=explore-prom-exporter
正常なサービスが表示されたら、サービスモニターを作成して、Prometheusがexplore-prom-exporter-solr-metricsサービスを介してエクスポーターポッドからメトリクスのスクレイピングを開始するようにします。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: solr-metrics
labels:
release: prometheus-stack
spec:
selector:
matchLabels:
solr-prometheus-exporter: explore-prom-exporter
namespaceSelector:
matchNames:
- sop030
endpoints:
- port: solr-metrics
interval: 15s
エクスポーターが有用なメトリクスを生成し始める前に、クラスタに少なくとも1つのコレクションを作成する必要があります。
Grafanaダッシュボード
kubectl exposeを使用して、GrafanaのLoadBalancer(外部IP)を作成します。
kubectl expose deployment prometheus-stack-grafana --type=LoadBalancer \
--name=grafana -n monitoring
しばらく待ってから、次のようにしてGrafanaサービスの外部IPアドレスを取得します。
kubectl -n monitoring get service grafana \
-o jsonpath='{.status.loadBalancer.ingress[0].ip}'
あるいは、ポート3000でリッスンしているGrafanaポッドへのポートフォワードを開くことができます。
adminとprom-operatorを使用してGrafanaにログインします。
ソースディストリビューションからデフォルトのSolrダッシュボードをダウンロードします。
wget -q -O grafana-solr-dashboard.json \
"https://raw.githubusercontent.com/apache/lucene-solr/branch_8x/solr/contrib/prometheus-exporter/conf/grafana-solr-dashboard.json"
grafana-solr-dashboard.jsonファイルをGrafanaに手動でインポートします。
この時点で、データをロードしてクエリパフォーマンステストを実行する必要があります。マルチゾーンクラスタを実行している場合は、同じゾーン内のレプリカを優先するように次のクエリパラメーターをクエリリクエストに追加してください(すべてのゾーンに正常なレプリカがある場合、リクエストごとのゾーン間のトラフィックを削減するのに役立ちます)。クエリロードテストツールがない場合は、Gatling(gatling.io)を検討することをお勧めします。
shards.preference=node.sysprop:sysprop.availability_zone,replica.location:local
まとめ
この時点で、PrometheusとGrafanaを使用してパフォーマンスモニタリングを行う、安全でHA対応のバランスの取れたSolrクラスタを作成するためのブループリントができました。本番環境にロールアウトする前に、バックアップ/リストア、自動スケーリング、および主要なヘルスインジケーターのアラートについても考慮する必要があります。これらの追加の側面の一部を今後の投稿で取り上げられることを願っています。
他に情報が必要な懸念事項はありますか?Slack #solr-operatorまたはGitHub Issuesでお知らせください。
この記事で使用したSolrCloud、Prometheusエクスポーター、およびサポートオブジェクトのYAMLの最終リストを次に示します。お楽しみください!
---
apiVersion: v1
kind: Secret
metadata:
name: pkcs12-keystore-password
stringData:
password-key: Test1234
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: selfsigned-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: explore-selfsigned-cert
spec:
subject:
organizations: ["self"]
dnsNames:
- localhost
secretName: explore-selfsigned-cert-tls
issuerRef:
name: selfsigned-issuer
keystores:
pkcs12:
create: true
passwordSecretRef:
key: password-key
name: pkcs12-keystore-password
---
apiVersion: solr.apache.org/v1beta1
kind: SolrCloud
metadata:
name: explore
spec:
customSolrKubeOptions:
podOptions:
resources:
limits:
memory: 3Gi
requests:
cpu: 700m
memory: 3Gi
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: "technology"
operator: In
values:
- solr-cloud
- key: "solr-cloud"
operator: In
values:
- explore
topologyKey: topology.kubernetes.io/zone
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "technology"
operator: In
values:
- solr-cloud
- key: "solr-cloud"
operator: In
values:
- explore
topologyKey: kubernetes.io/hostname
initContainers: # additional init containers for the Solr pods
- name: set-zone # GKE specific, avoids giving get nodes permission to the service account
image: curlimages/curl:latest
command:
- '/bin/sh'
- '-c'
- |
zone=$(curl -sS http://metadata.google.internal/computeMetadata/v1/instance/zone -H 'Metadata-Flavor: Google')
zone=${zone##*/}
if [ "${zone}" != "" ]; then
echo "export SOLR_OPTS=\"\${SOLR_OPTS} -Davailability_zone=${zone}\"" > /docker-entrypoint-initdb.d/set-zone.sh
fi
volumeMounts:
- name: initdb
mountPath: /docker-entrypoint-initdb.d
volumes:
- defaultContainerMount:
mountPath: /docker-entrypoint-initdb.d
name: initdb
name: initdb
source:
emptyDir: {}
dataStorage:
persistent:
pvcTemplate:
spec:
resources:
requests:
storage: 2Gi
reclaimPolicy: Delete
replicas: 3
solrImage:
repository: solr
tag: 8.8.2
solrJavaMem: -Xms500M -Xmx510M
updateStrategy:
managed:
maxPodsUnavailable: 2
maxShardReplicasUnavailable: 2
method: Managed
solrAddressability:
commonServicePort: 443
external:
domainName: YOUR_DOMAIN_NAME_HERE
method: Ingress
nodePortOverride: 443
useExternalAddress: false
podPort: 8983
solrTLS:
restartOnTLSSecretUpdate: true
pkcs12Secret:
name: explore-selfsigned-cert-tls
key: keystore.p12
keyStorePasswordSecret:
name: pkcs12-keystore-password
key: password-key
solrSecurity:
authenticationType: Basic
zookeeperRef:
provided:
chroot: /explore
image:
pullPolicy: IfNotPresent
repository: pravega/zookeeper
tag: 0.2.9
persistence:
reclaimPolicy: Delete
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
replicas: 3
zookeeperPodPolicy:
resources:
limits:
memory: 500Mi
requests:
cpu: 250m
memory: 500Mi
---
apiVersion: solr.apache.org/v1beta1
kind: SolrPrometheusExporter
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: explore-prom-exporter
spec:
customKubeOptions:
podOptions:
resources:
requests:
cpu: 300m
memory: 800Mi
solrReference:
cloud:
name: "explore"
basicAuthSecret: explore-solrcloud-basic-auth
solrTLS:
restartOnTLSSecretUpdate: true
pkcs12Secret:
name: explore-selfsigned-cert-tls
key: keystore.p12
keyStorePasswordSecret:
name: pkcs12-keystore-password
key: password-key
numThreads: 6
image:
repository: solr
tag: 8.8.2
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: solr-metrics
labels:
release: prometheus-stack
spec:
selector:
matchLabels:
solr-prometheus-exporter: explore-prom-exporter
namespaceSelector:
matchNames:
- sop030
endpoints:
- port: solr-metrics
interval: 15s